







一、缓存更新策略
缓存的更新需要考虑数据的一致性、更新的成本。
Ⅰ、通过内存溢出控制策略剔除旧数据
可以通过设置maxmemory-policy来抛弃掉LRU的数据以腾出内存给新的需要缓存的数据使用。
总结:这种方法的数据一致性较差(指Redis和MySQL的一致性)。由于 当数据不在缓存时且数据是热点数据才更新缓存,所以当Redis服务器的内存使用离maxmemory-policy还有较多空间时,缓存中的数据没有丢弃则会一直得不到更新。
Ⅱ、超时剔除
通过setex命令为键增加过期时间。当数据不在缓存时且数据是热点数据才更新缓存。
总结:在过期时间内还是存在数据一致性问题。
Ⅲ、主动更新
每次在对MySQL数据进行set()操作时都主动更新一次Redis,这个主动更新操作可以通过MQ或直接在Spring中实现.
总结:数据一致性最高,但增加了更新成本.
二、缓存粒度控制
要用Redis缓存通用性最高的数据,如热点MySQL行的某几个属性。
三、缓存穿透
Ⅰ、问题描述
缓存穿透是指前端不断地请求一个根本不存在的数据,而通常为了不占用缓存的空间,空数据一般是不会被更新去缓存的,这样就使得后台在查询这些数据时总是去MySQL层查询,MySQL压力剧增。
Ⅱ、解决方案
①、缓存空对象
当从MySQL查询到数据不存在,则将该key放进Redis中,使得以后再查询此条空数据时就不用去访问MySQL。
缺点:当这些查询是专门的空数据攻击时,这样的做法会使得问题更加严重。
⭐②、布隆过滤器判断存在性
在Redis和MySQL前做一层布隆过滤器拦截,当布隆过滤器返回此key存在于数据库中时,才进行 缓存查找 和 数据库查找并更新缓存 逻辑。
1、具体实现
-
在Spring中插入或更新数据时,如果从数据热点,则更新redis缓存;否则只更新
BloomFilter和MySQL。 -
在Spring中获取数据时,先进行布隆过滤器判断,判断存在再请求缓存和MySQL。
2、架构设计
-
如果是单机后台系统,则可以在Spring中使用Guava的
BloomFilter。此方案最大的缺点是只能在单机后台中发挥作用。 -
如果是分布式后台系统,则要使用Redis的
BloomFilter。
3、布隆过滤器原理
- 某key要映射到布隆过滤器时,使用多个hash函数对此key求hash得出多个下标值,然后根据这些下标值,对布隆过滤器内部维护的
BitMap的下标元素置1。 - 当要判断某key是否存在时,一样使用hash函数求出下标值,然后查看
BitMap的这些下标是否都为1,若是则证明此元素有可能 存在,若不是则证明此元素 不可能存在. - ⭐⭐应用场景:1. 海量数据去重,如果准确度要求不高就可以使用布隆过滤器;要求准确无误就要使用
HashSet2.利用布隆过滤器减少磁盘 IO 或者网络请求,这种应用就是缓存穿透的解决方案
四、缓存雪崩
Ⅰ、问题描述
缓存雪崩指的是Redis缓存层崩掉之后,请求不断地打向MySQL数据库。
Ⅱ、解决方案
①、保证缓存层服务的高可用性
用集群或哨兵模式保证其高可用
②、使用多级缓存
③、使用 hystrix限流,在缓存接近崩溃边缘时调低通过的请求个数,并将剩余请求个数降级交给降级组件
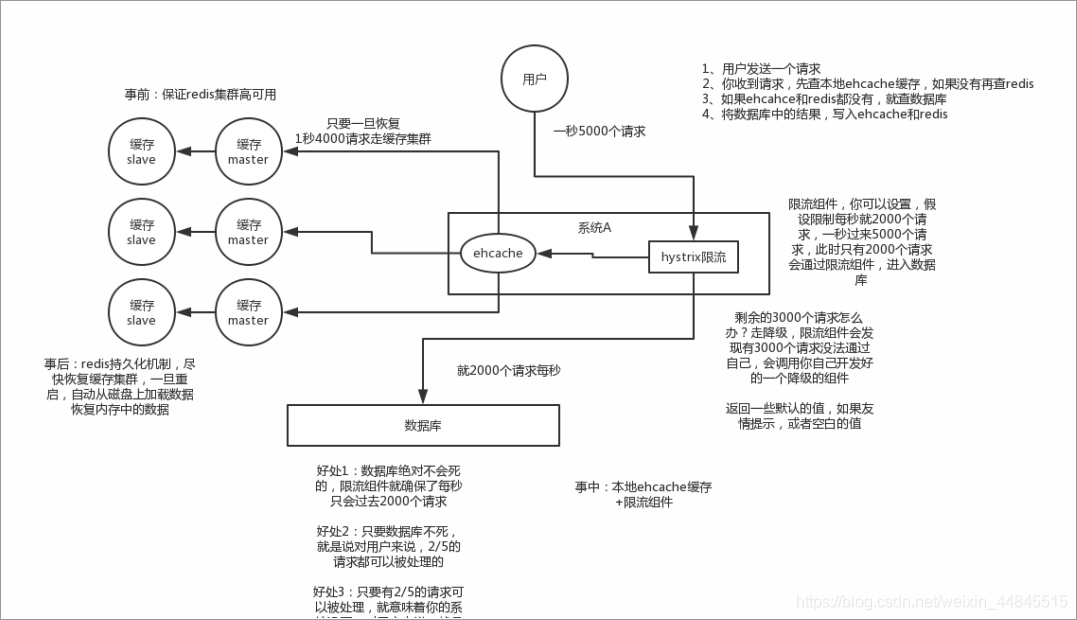
五、热点key重建问题
Ⅰ、问题描述
缓存中有一个热点key,访问并发量非常高。当热点key在Redis过期失效的那一刻,所有同时访问此key的后台线程都会转去访问MySQL进而更新Redis缓存,使得大量的线程重建缓存做了无谓的工作。
Ⅱ、解决方案
①使用Redis分布式锁
在查询缓存发现缓存中没有热点key时,都向redis申请一个锁(set key:lock 1 EX 60 NX),若申请成功,再进行访问MySQL重建Redis缓存的操作;若申请失败,则证明此时有其他线程(服务器)正在对此key进行缓存重建,可以递归自旋判断key是否为空并尝试获取分布式锁(因为如果其他线程所在服务器由于宕机更新缓存失败,则要重新争抢锁继续更新),等到不为空时再直接获取数据,这样就使得只有一个线程会重建热点key.
1、分布式锁的后台实现

这个架构设计的考虑了两点:
- 如果不设置守护线程,若线程A只是执行的慢并没有宕机,可是锁却过期了而被其他线程争抢到了,此时的线程A就处于在临界区却没有锁保护的状态。
- 命令必须是这样写
set key:lock 1 EX 60 NX,不能产生复合操作。
具体逻辑:
主逻辑线程使用set key:lock 1 EX 60 NX命令得到了Redis锁,于是开启守护线程监测主逻辑线程的状态。如果服务器并没有宕机,只是可能由于其他原因导致主逻辑线程拥有锁的时间比较长,此时守护线程则要为主逻辑线程的锁 续时 以防止由于超时使得其他线程将该锁争抢了;如果真的宕机了,那守护线程也没了,等到分布式锁自然超时其他服务器线程就又可以来争抢锁了。
package com.robin.twitter.utils;
import org.springframework.data.redis.core.StringRedisTemplate;
import java.time.Duration;
import java.util.concurrent.*;
/**
* 此类只是提供一个操作分布式锁的接口,分布式锁的真正实现在Redis,所以正确的使用方法应该是线程需要争抢某key的锁
* 时创建一个此对象,而不是 由于多个线程都争抢同一个key从而共享一个了 操作分布式锁的接口.理论上应该如此,
* 但我还是把这个类设计成了线程安全.
*
* @author Robin
* @date 2020/4/2 -23:06
*/
public class DistributedLock
{
/**
* 标记锁状态
* 由于是守护线程和创建锁线程共享的状态,所以要加volatile
*/
private volatile int state = 0;
private static final String LOCKING = "1";
private Thread exclusiveOwnerThread;
/**
* 守护线程池,设置等待队列为SynchronousQueue和最大线程数1000,使得在高并发申请锁时,守护任务也不会有延迟执行
*/
private static final ExecutorService THREAD_POOL = new
ThreadPoolExecutor(0, 1000, 40L, TimeUnit.SECONDS, new SynchronousQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());
/**
* 目标key的redisClient
*/
private final StringRedisTemplate stringRedisTemplate;
/**
* 守护线程Runnable
*/
private DaemonRunnable daemonTask;
/**
* 锁
*/
private final String key;
/**
* 限制过期时间
*/
private final long limit;
/**
* @param s 目标key的redisClient
* @param key 目标key
* @param limit 限制过期时间
*/
public DistributedLock(StringRedisTemplate s, String key, long limit)
{
this.stringRedisTemplate = s;
this.key = key;
this.limit = limit;
}
private class DaemonRunnable implements Runnable
{
//记录锁持有结束的时间戳,以秒为单位
long limitTime;
public DaemonRunnable(long time)
{
this.limitTime = time/1000 + limit;
}
@Override
public void run()
{
try
{
while (state > 0)
{
if (limitTime - 10 > 0)
{
//睡到过期前10s
Thread.sleep((limitTime - 10) * 1000);
}
//在过期前5s再次给key加时.算上5s的网络IO应该赶得上把?
if (System.currentTimeMillis() > (limitTime-5)*1000)
{
/**
* 由于修改state和更新redis锁是一个复合操作,这里我的unlock()逻辑是先删除Redis锁
* 再修改state,若删除Redis锁后刚好执行到这里就又给该key加上锁了,不符合逻辑
* 所以必须该锁存在时才给它加时
*/
stringRedisTemplate.opsForValue().setIfPresent(key, "1",
Duration.ofSeconds(limit));
limitTime+=limit;
}
}
} catch (InterruptedException e)
{
//就算被打断还是要继续执行
run();
}
}
}
/**
* 尝试获取redis锁
*
* @return 返回true则获取成功,false则失败
*/
public boolean tryLock()
{
//获取该键的锁
//此代码不会返回null,不用看这编译错误,看源码注释
if (stringRedisTemplate.opsForValue().setIfAbsent(key, LOCKING,
Duration.ofSeconds(limit)))
{
state = 1;
setExclusiveOwnerThread(Thread.currentThread());
//开启守护线程
daemonTask = new DaemonRunnable(System.currentTimeMillis());
THREAD_POOL.execute(daemonTask);
return true;
}
return false;
}
protected final void setExclusiveOwnerThread(Thread currentThread)
{
this.exclusiveOwnerThread = currentThread;
}
protected final Thread getExclusiveOwnerThread()
{
return this.exclusiveOwnerThread;
}
/**
* 解锁
*
* @param key
*/
public void unLock(String key)
{
//锁着锁的线程才能解锁
/**
* 为什么exclusiveOwnerThread不需要volatile修饰保证可见性?
* 如果setExclusiveOwnerThread(null)对某条线程不可见,当该线程作死没lock()也要unLock()时
* 就会发现exclusiveOwnerThread还是等于持有 过 分布式锁的线程,也还是无法进入临界区,所以不保证
* 可见性也还是线程安全
*/
if (Thread.currentThread() != getExclusiveOwnerThread())
{
throw new IllegalMonitorStateException();
}
stringRedisTemplate.delete(key);
state = 0;
setExclusiveOwnerThread(null);
}
}
渣比代码,有问题请在评论区指正,感谢!
参考资料
《JavaGuide》面试总结
《Redis开发与运维》














 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









