







 本文介绍了使用Python爬虫抓取2021年中国大学排名的过程,包括确定目标、解析网页和展示结果。通过解析网页源码,找到并提取排名、大学名称、省市、类型、总分和办学层次等信息。
本文介绍了使用Python爬虫抓取2021年中国大学排名的过程,包括确定目标、解析网页和展示结果。通过解析网页源码,找到并提取排名、大学名称、省市、类型、总分和办学层次等信息。
本文初衷仅作为学习交流,因为我在刚开始学的时候什么东西都爬不出来,艰苦摸索过一段时间,希望这篇文章可以给爬虫入门的小伙伴一点帮助
看见有些小伙伴问我为什么爬取不到信息,是因为我这篇博客是2020年写的,如今最好大学网也改版啦,想要爬取信息就需要重新解析网页了。
本文是写于我刚学习python爬虫的时候,自身对爬虫的理解也不太深,所以对博客爬取具体详情也没有细说。源于学习mooc上嵩天老师的爬取大学排名,练习网址为最好大学网
一、确定目标
希望写出一个小爬虫获取信息,首先需要确定的是自己希望爬取的内容在上面地方。进入网站可看见如下页面
我确定的目标是中国大学排名,点击进入查看
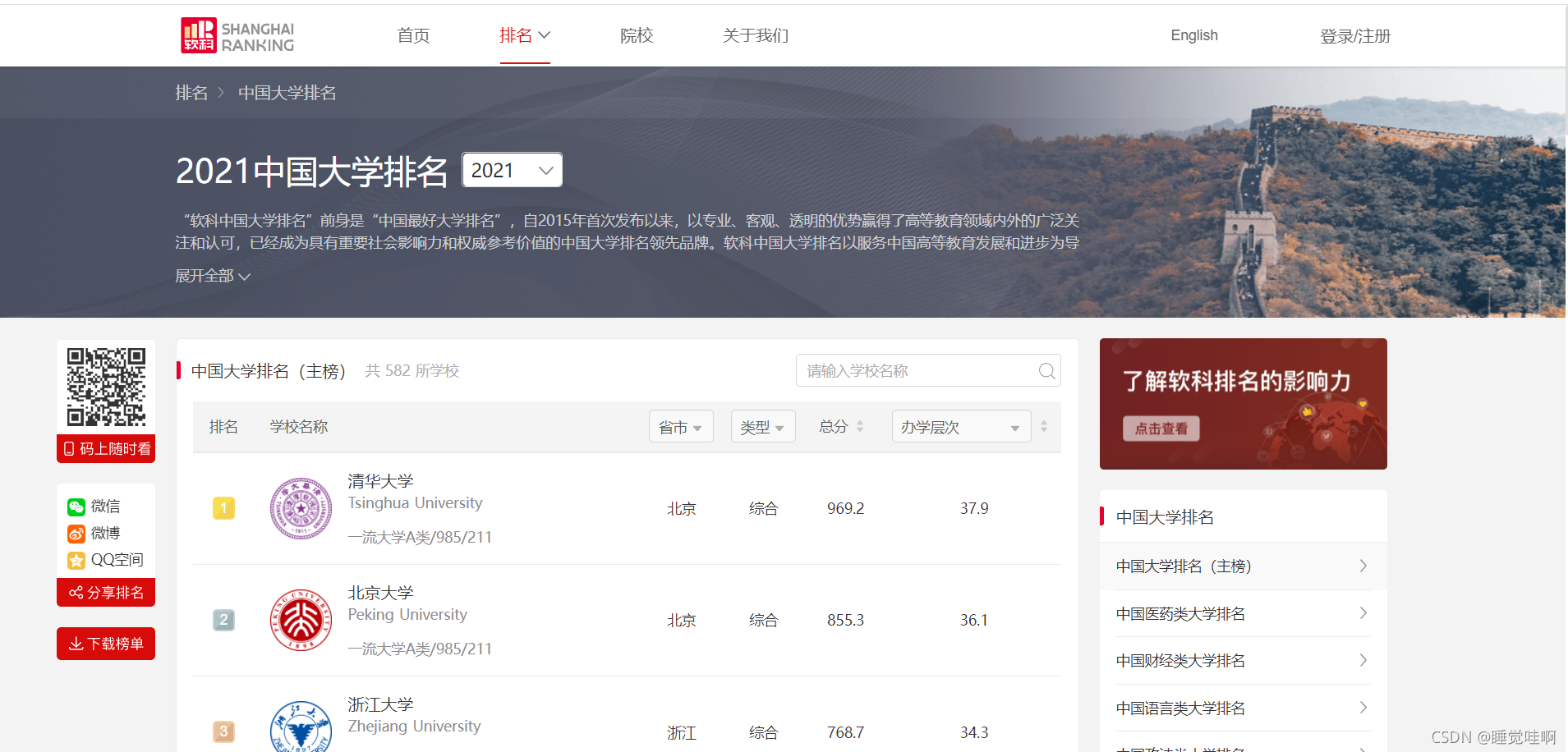
二、解析网页
已经进入了目标页面,按f12键查看网页源码,具体如下。
前期的准备工作就已经完成了,接下来我们需要先尝试的爬一下,测试网页有什么反爬机制,代码如下。
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()#如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3981
3981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









