







窗口函数的主要作用是对数据进行分组排序、求和、求平均值、计数等。
1.窗口函数的基本语法
<分析函数> OVER ([PARTITION BY <列清单>] ORDER BY <排序用列清单> [ROWS BETWEEN 开始位置 AND 结束位置])
理解窗口函数的基本语法:
over()函数中包括三个函数:包括分区 partition by 列名、排序 order by 列名、指定窗口范围 rows between 开始位置 and 结束位置。我们在使用over()窗口函数时,over()函数中的这三个函数可组合使用也可以不使用。
over()函数中如果不使用这三个函数,窗口大小是针对查询产生的所有数据,如果指定了分区,窗口大小是针对每个分区的数据。
1.1 partition by
partition by划分的范围被称为窗口,这也是窗口函数的由来。
1.2 order by
order by决定着窗口范围内的数据以什么样的方式排序。
1.3 rows between 开始位置 and 结束位置
指的是指定窗口范围,比如第一行到当前行。而这个范围是随着数据变化的。over(rows between 开始位置 and 结束位置)搭配分析函数时,分析函数按照这个范围进行计算的。
窗口范围说明:
我们常使用的窗口范围是ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当 前行),常用该窗口来计算累加。
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点(一般结合PRECEDING,FOLLOWING使用)
UNBOUNDED PRECEDING 表示该窗口最前面的行(起点)
UNBOUNDED FOLLOWING:表示该窗口最后面的行(终点)
比如说:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行)
ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING(表示往前2行到往后1行)
ROWS BETWEEN 2 PRECEDING AND 1 CURRENT ROW(表示往前2行到当前行)
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING(表示当前行到终点)
一个比较完整的SQL查询语句的编写顺序:
SELECT DISTINCT Table1., Table2.
FROM
Table1 JOIN Table2 ON matching_condition
WHERE constraint_expression
GROUP BY [columns]
HAVING constraint_expression
ORDER BY [columns] LIMIT count
SQL解析器在执行SQL的顺序与编写顺序是不同的:
| SQL关键字 | 编写顺序编号 | 执行顺序编号 |
|---|---|---|
| SELECT | 1 | 5 |
| FROM | 2 | 1 |
| WHERE | 3 | 2 |
| GROUP BY | 4 | 3 |
| HAVING | 5 | 4 |
| ORDER BY | 6 | 6 |
| LIMIT | 7 | 7 |

上述SQL执行顺序可视化图示如下:
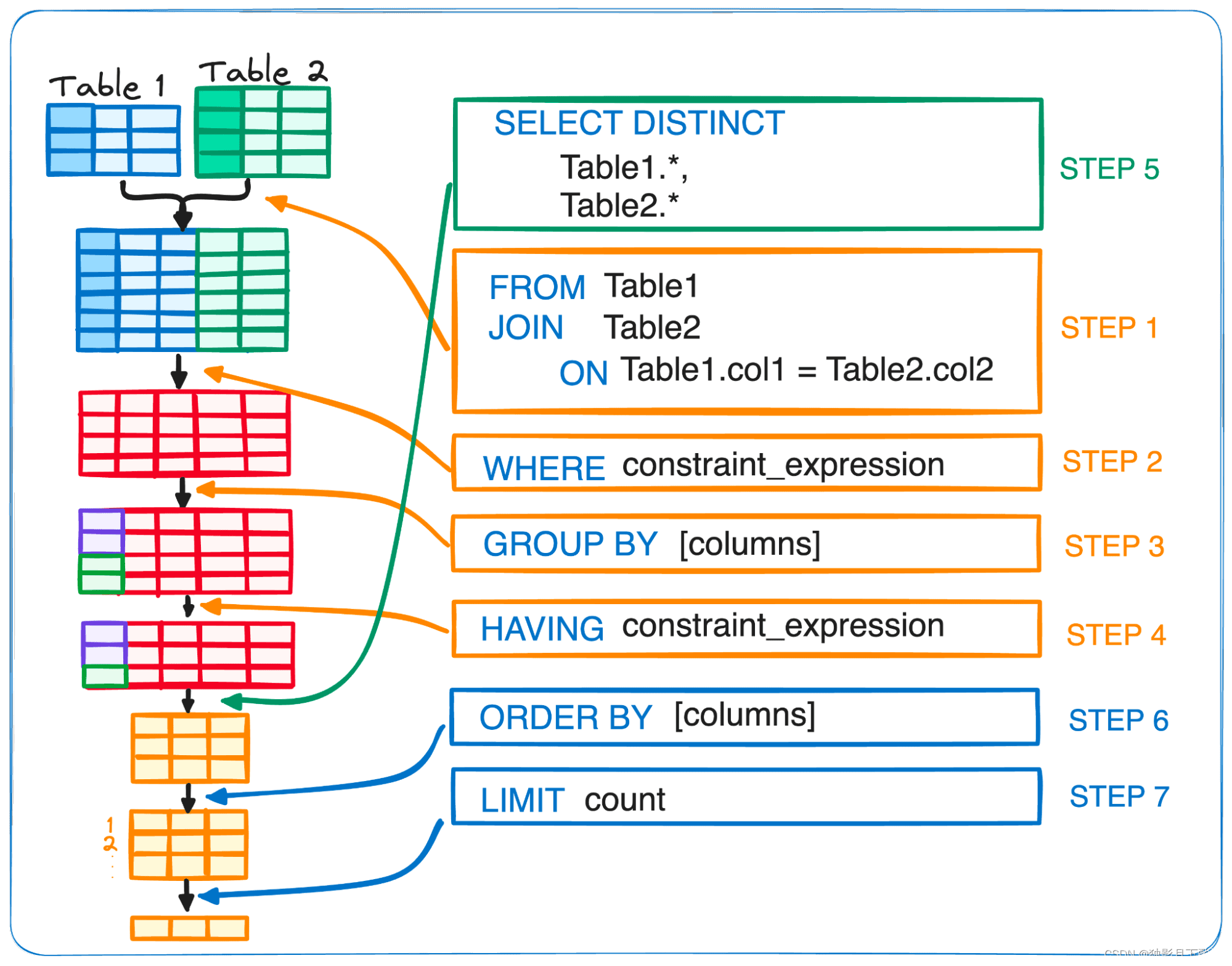
在加入窗口函数的基础上SQL的执行顺序也会发生变化,具体的执行顺序如下(window就是窗口函数):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sSnecEa8-1628578703350)(C:\Users\hbwhx\Desktop\学习\窗口函数\Windows Functions.assets\image-20210713143908533.png)]](https://i-blog.csdnimg.cn/blog_migrate/a35d3bb239e6f4a89e871990dff1024f.png)
2.窗口函数的类型
专用窗口函数例如rank、row_number、lag和lead等,在窗口函数中有静态函数和动态函数的分类,具体的划分如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3ut14zoW-1628578703352)(C:\Users\hbwhx\Desktop\学习\窗口函数\Windows Functions.assets\image-20210713144138756.png)]](https://i-blog.csdnimg.cn/blog_migrate/6c4ed0660c54abd1e007d7202bbb7985.png)
2.1 排序函数(NTILE,ROW_NUMBER,RANK,DENSE_RANK)
准备数据
-- 原始数据
cookie1,2018-04-10,1
cookie1,2018-04-11,5
cookie1,2018-04-12,7
cookie1,2018-04-13,3
cookie1,2018-04-14,2
cookie1,2018-04-15,4
cookie1,2018-04-16,4
cookie2,2018-04-10,2
cookie2,2018-04-11,3
cookie2,2018-04-12,5
cookie2,2018-04-13,6
cookie2,2018-04-14,3
cookie2,2018-04-15,9
cookie2,2018-04-16,7
--建表语句
CREATE TABLE t1 (
cookieid string,
createtime string, --day
pv INT
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
stored as textfile;
-- 加载数据:
load data local inpath '/root/hivedata/t1.dat' into table t1;
2.1.1 NTILE
背景:
需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这个中间的三分之一数据拿出来呢?NTILE函数即可满足。
ntile可以看成是:把有序的数据集合平均分配到指定的数量(num)个桶中, 将桶号分配给每一行。
如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
语法是:ntile (num) over ([partition_clause] order_by_clause) as xxx
然后可以根据桶号,选取前或后 n分之几的数据。
数据会完整展示出来,只是给相应的数据打标签;具体要取几分之几的数据,需要再嵌套一层根据标签取出。注意:
NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
SELECT
cookieid,
createtime,
pv,
NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn1,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2,
NTILE(4) OVER(ORDER BY createtime) AS rn3
FROM t1
ORDER BY cookieid,createtime;
比如,统计一个cookie,pv数最多的前1/3的天
SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn
FROM t1;
其中rn = 1 的记录,就是我们想要的结果
2.1.2 ROW_NUMBER
ROW_NUMBER() 从1开始,按照顺序,生成分组内记录的序列
SELECT
cookieid,
createtime,
pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn
FROM t1;
2.1.3 RANK 和 DENSE_RANK
RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM t1
WHERE cookieid = 'cookie1';
2.2 聚合函数(SUM,AVG,MIN,MAX,CUME_DIST,PERCENT_RANK)
准备数据
-- 建表语句:
create table t2(
cookieid string,
createtime string, --day
pv int
) row format delimited
fields terminated by ',';
-- 加载数据:
load data local inpath '/root/hivedata/t2.dat' into table t2;
cookie1,2018-04-10,1
cookie1,2018-04-11,5
cookie1,2018-04-12,7
cookie1,2018-04-13,3
cookie1,2018-04-14,2
cookie1,2018-04-15,4
cookie1,2018-04-16,4
-- 开启智能本地模式
SET hive.exec.mode.local.auto=true;
2.2.1 SUM(结果和ORDER BY相关,默认为升序)
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as pv1
from t2;
-- pv1: 分组内从起点到当前行的pv累积,如,11号的pv1=10号的pv+11号的pv, 12号=10号+11号+12号
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from t2;
-- pv2: 同pv1
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid) as pv3
from t2;
-- pv3: 分组内(cookie1)所有的pv累加
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from t2;
-- pv4: 分组内当前行+往前3行,如,11号=10号+11号, 12号=10号+11号+12号,
13号=10号+11号+12号+13号, 14号=11号+12号+13号+14号
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from t2;
-- pv5: 分组内当前行+往前3行+往后1行,如,14号=11号+12号+13号+14号+15号=5+7+3+2+4=21
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from t2;
-- pv6: 分组内当前行+往后所有行,如,13号=13号+14号+15号+16号=3+2+4+4=13,14号=14号+15号+16号=2+4+4=10
- 如果不指定rows between,默认为从起点到当前行;
- 如果不指定order by,则将分组内所有值累加;
- 关键是理解rows between含义,也叫做window子句:
- preceding:往前
- following:往后
- current row:当前行
- unbounded:起点
- unbounded preceding 表示从前面的起点
- unbounded following:表示到后面的终点
2.2.2 AVG,MIN,MAX,用法同SUM
select cookieid,createtime,pv,
avg(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from t2;
select cookieid,createtime,pv,
max(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from t2;
select cookieid,createtime,pv,
min(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from t2;
2.2.3 CUME_DIST,PERCENT_RANK
CUME_DIST,PERCENT_RANK两个序列分析函数不是很常用,注意: 序列函数不支持WINDOW子句
准备数据
-- 原始数据
d1,user1,1000
d1,user2,2000
d1,user3,3000
d2,user4,4000
d2,user5,5000
CREATE EXTERNAL TABLE t3 (
dept STRING,
userid string,
sal INT
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
stored as textfile;
-- 加载数据:
load data local inpath '/root/hivedata/t3.dat' into table t3;
- CUME_DIST 和order by的排序顺序有关系
CUME_DIST 小于等于当前值的行数/分组内总行数 order 默认顺序 正序 升序
比如,统计小于等于当前薪水的人数,所占总人数的比例
SELECT
dept,
userid,
sal,
CUME_DIST() OVER(ORDER BY sal) AS rn1,
CUME_DIST() OVER(PARTITION BY dept ORDER BY sal) AS rn2
FROM t3;
rn1: 没有partition,所有数据均为1组,总行数为5,
第一行:小于等于1000的行数为1,因此,1/5=0.2
第三行:小于等于3000的行数为3,因此,3/5=0.6
rn2: 按照部门分组,dpet=d1的行数为3,
第二行:小于等于2000的行数为2,因此,2/3=0.6666666666666666
-
PERCENT_RANK
PERCENT_RANK 分组内当前行的RANK值-1/分组内总行数-1
SELECT
dept,
userid,
sal,
PERCENT_RANK() OVER(ORDER BY sal) AS rn1, --分组内
RANK() OVER(ORDER BY sal) AS rn11, --分组内RANK值
SUM(1) OVER(PARTITION BY NULL) AS rn12, --分组内总行数
PERCENT_RANK() OVER(PARTITION BY dept ORDER BY sal) AS rn2
FROM t3;
rn1: rn1 = (rn11-1) / (rn12-1)
第一行,(1-1)/(5-1)=0/4=0
第二行,(2-1)/(5-1)=1/4=0.25
第四行,(4-1)/(5-1)=3/4=0.75
rn2: 按照dept分组,
dept=d1的总行数为3
第一行,(1-1)/(3-1)=0
第三行,(3-1)/(3-1)=1
2.3 取值函数(LAG,LEAD,FIRST_VALUE,LAST_VALUE)
注意: 这几个函数不支持WINDOW子句
准备数据
-- 原始数据
cookie1,2018-04-10 10:00:02,url2
cookie1,2018-04-10 10:00:00,url1
cookie1,2018-04-10 10:03:04,1url3
cookie1,2018-04-10 10:50:05,url6
cookie1,2018-04-10 11:00:00,url7
cookie1,2018-04-10 10:10:00,url4
cookie1,2018-04-10 10:50:01,url5
cookie2,2018-04-10 10:00:02,url22
cookie2,2018-04-10 10:00:00,url11
cookie2,2018-04-10 10:03:04,1url33
cookie2,2018-04-10 10:50:05,url66
cookie2,2018-04-10 11:00:00,url77
cookie2,2018-04-10 10:10:00,url44
cookie2,2018-04-10 10:50:01,url55
CREATE TABLE t4 (
cookieid string,
createtime string, -- 页面访问时间
url STRING -- 被访问页面
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
stored as textfile;
-- 加载数据:
load data local inpath '/root/hivedata/t4.dat' into table t4;
2.3.1 LAG
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS last_1_time,
LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_2_time
FROM t4;
last_1_time: 指定了往上第1行的值,default为'1970-01-01 00:00:00'
cookie1第一行,往上1行为NULL,因此取默认值 1970-01-01 00:00:00
cookie1第三行,往上1行值为第二行值,2015-04-10 10:00:02
cookie1第六行,往上1行值为第五行值,2015-04-10 10:50:01
last_2_time: 指定了往上第2行的值,为指定默认值
cookie1第一行,往上2行为NULL
cookie1第二行,往上2行为NULL
cookie1第四行,往上2行为第二行值,2015-04-10 10:00:02
cookie1第七行,往上2行为第五行值,2015-04-10 10:50:01
2.3.2 LEAD(与LAG相反)
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LEAD(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS next_1_time,
LEAD(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_2_time
FROM t4;
2.3.3 FIRST_VALUE
取分组内排序后,截止到当前行,第一个值
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1
FROM t4;
2.3.4 LAST_VALUE
取分组内排序后,截止到当前行,最后一个值
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1
FROM t4;
如果想要取分组内排序后最后一个值,则需要变通一下:
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime DESC) AS last2
FROM t4
ORDER BY cookieid,createtime;
特别注意order by
如果不指定ORDER BY,则进行排序混乱,会出现错误的结果
SELECT cookieid,
createtime,
url,
FIRST_VALUE(url) OVER(PARTITION BY cookieid) AS first2
FROM t4;
2.4 时间函数(GROUPING SETS,GROUPING__ID,CUBE,ROLLUP)
GROUPING SETS,GROUPING__ID,CUBE,ROLLUP通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比如,分小时、天、月的UV数。
准备数据
-- 原始数据
2018-03,2018-03-10,cookie1
2018-03,2018-03-10,cookie5
2018-03,2018-03-12,cookie7
2018-04,2018-04-12,cookie3
2018-04,2018-04-13,cookie2
2018-04,2018-04-13,cookie4
2018-04,2018-04-16,cookie4
2018-03,2018-03-10,cookie2
2018-03,2018-03-10,cookie3
2018-04,2018-04-12,cookie5
2018-04,2018-04-13,cookie6
2018-04,2018-04-15,cookie3
2018-04,2018-04-15,cookie2
2018-04,2018-04-16,cookie1
-- 建表语句
CREATE TABLE t5 (
month STRING,
day STRING,
cookieid STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
stored as textfile;
加载数据:
load data local inpath '/root/hivedata/t5.dat' into table t5;
2.4.1 GROUPING SETS
grouping sets是一种将多个group by 逻辑写在一个sql语句中的便利写法。
等价于将不同维度的GROUP BY结果集进行UNION ALL。
GROUPING__ID,表示结果属于哪一个分组集合。
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY month,day
GROUPING SETS (month,day)
ORDER BY GROUPING__ID;
-- grouping_id表示这一组结果属于哪个分组集合,
-- 根据grouping sets中的分组条件month,day,1是代表month,2是代表day
-- 等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM t5 GROUP BY month UNION ALL
SELECT NULL as month,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM t5 GROUP BY day;
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY month,day
GROUPING SETS (month,day,(month,day))
ORDER BY GROUPING__ID;
-- 等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM t5 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM t5 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM t5 GROUP BY month,day;
2.4.2 CUBE
根据GROUP BY的维度的所有组合进行聚合。
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
-- 等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__ID FROM t5
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM t5 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM t5 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM t5 GROUP BY month,day;
2.4.3 ROLLUP
ROLLUP是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。
-- 比如,以month维度进行层级聚合:
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;
-- 把month和day调换顺序,则以day维度进行层级聚合:
SELECT
day,
month,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;
-- (这里,根据天和月进行聚合,和根据天聚合结果一样,因为有父子关系,如果是其他维度组合的话,就会不一样)
FROM t5 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM t5 GROUP BY month,day;
#### 2.4.3 ROLLUP
ROLLUP是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。
```sql
-- 比如,以month维度进行层级聚合:
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;
-- 把month和day调换顺序,则以day维度进行层级聚合:
SELECT
day,
month,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;
-- (这里,根据天和月进行聚合,和根据天聚合结果一样,因为有父子关系,如果是其他维度组合的话,就会不一样)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









