









 本文介绍了一种求解带障碍物的网格中从起点到终点的不同路径数量的方法。通过动态规划思想,详细阐述了算法的设计过程,包括状态定义、递推公式、初始化及遍历顺序,并给出了两种实现方式及其复杂度分析。
本文介绍了一种求解带障碍物的网格中从起点到终点的不同路径数量的方法。通过动态规划思想,详细阐述了算法的设计过程,包括状态定义、递推公式、初始化及遍历顺序,并给出了两种实现方式及其复杂度分析。
1.题目描述
一个机器人位于一个
m x n网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用
1和0来表示。
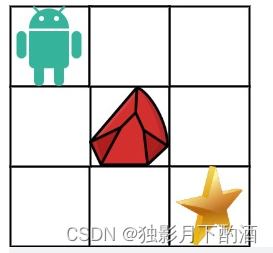
输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
输出:2
解释:3x3 网格的正中间有一个障碍物。
从左上角到右下角一共有 2 条不同的路径:
- 向右 -> 向右 -> 向下 -> 向下
- 向下 -> 向下 -> 向右 -> 向右

输入:obstacleGrid = [[0,1],[0,0]]
输出:1
提示:
- m == obstacleGrid.length
- n == obstacleGrid[i].length
- 1 <= m, n <= 100
- obstacleGrid[i][j] 为 0 或 1
2.思路分析
2.1 动态规划
机器人从(0 , 0) 位置出发,到(m - 1, n - 1)终点。
1.确定dp数组以及下标含义
- dp[i][j] :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。
2.确定递推公式
-
dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
-
注: 有了障碍,(i, j)如果就是障碍的话应该就保持初始状态(初始状态为0)。
if obstacleGrid[i][j] != 1: dp[i][j] = dp[i - 1][j] + dp[i][j - 1] else: dp[i][j] = 0
3.dp数组初始化
- 初始化第一个位置 dp[0][0] = 1 if obstacleGrid[0][0] != 1 else 0
- 初始化第一行 dp[i][0] =1 (遇到障碍物后面的dp值均为0)
- 初始化第一列 dp[0][j] =1 (遇到障碍物下面的dp值均为0)
4.确定遍历顺序
左->右 上->下 这样就可以保证推导dp[i][j]的时候,dp[i - 1][j] 和 dp[i][j - 1]一定是有数值的。
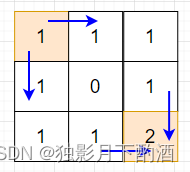
5.举例推导dp数组
以obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]为例
3.代码实现
class Solution:
def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
row = len(obstacleGrid)
col = len(obstacleGrid[0])
dp = [[0 for _ in range(col)] for _ in range(row)]
# 初始化第一个位置
dp[0][0] = 1 if obstacleGrid[0][0] != 1 else 0
if dp[0][0] == 0:
return 0
# 初始化第一行
for i in range(1, col):
if obstacleGrid[0][i] != 1:
dp[0][i] = dp[0][i - 1]
# 初始化第一列
for j in range(1, row):
if obstacleGrid[j][0] != 1:
dp[j][0] = dp[j - 1][0]
for i in range(1, row):
for j in range(1, col):
if obstacleGrid[i][j] != 1:
dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
else:
dp[i][j] = 0
return dp[row - 1][col - 1]
复杂度分析
- 时间复杂度:O(nm),其中 n 为网格的行数,m 为网格的列数。我们只需要遍历所有网格一次即可。
- 空间复杂度:O(mn)。利用滚动数组优化,我们可以只用 O(m) 大小的空间来记录当前行的 f 值
class Solution:
def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
#使用一维dp数组
m, n = len(obstacleGrid), len(obstacleGrid[0])
# 初始化dp数组
# 该数组缓存当前行
curr = [0] * n
for j in range(n):
if obstacleGrid[0][j] == 1:
break
curr[j] = 1
for i in range(1, m): # 从第二行开始
for j in range(n): # 从第一列开始,因为第一列可能有障碍物
# 有障碍物处无法通行,状态就设成0
if obstacleGrid[i][j] == 1:
curr[j] = 0
elif j > 0:
# 等价于
# dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
curr[j] = curr[j] + curr[j - 1]
# 隐含的状态更新
# dp[i][0] = dp[i - 1][0]
return curr[n - 1
复杂度分析
- 时间复杂度:O(nm),其中 n 为网格的行数,m 为网格的列数。我们只需要遍历所有网格一次即可。
- 空间复杂度:O(m)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









