







写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除!
背景
为了满足各种AI应用对检测精度的要求,深度神经网络结构的宽度、层数、深度以及各类参数等数量急速上升,导致深度学习模型占用了更大的存储空间,需要更长的推理时延,不利于工业化部署。此外,深度学习模型在GPU等高性能计算设备上进行推理时,虽然能够得到高性能的模型,但这些模型一般较为复杂,并不适合在边缘设备进行推理。
其次,随着商业对模型应用越来越倾向于从云端部署到边缘侧,如移动设备、IoT设备等,这些设备在处理、内存、耗电量、网络连接和模型存储空间等方面存在限制。
因此,需要考虑如何在保证精度的同时,降低模型的存储需求和推理时延,以便更好地在边缘设备上部署深度学习模型。
量化作为通用的深度学习优化的手段之一,模型量化通过某种方法将浮点模型转为定点模型,以显著减小模型的尺寸,提高推理速度,并且几乎不会有精度损失。同时,量化还可以提高模型的鲁棒性,使其对噪声和扰动具有更强的抵抗能力。
综上所述,深度学习模型量化的背景主要源于现代AI应用对检测精度的追求以及边缘设备部署的需求。通过模型量化,我们可以得到更小、更快、更鲁棒的深度学习模型,以便更好地满足各种应用场景的需求。
PyTorch 量化
量化:使用位宽低于浮点精度的张量用于执行计算和存储的技术,是一种加快推理速度技术 ,仅支持量化前向传递。
量化模型:以降低的精度对张量执行部分或全部操作,允许更紧凑的模型表示以在许多硬件平台上使用高性能矢量化操作。
从 PyTorch 1.3 开始,提供了量化功能,随着 PyTorch 1.4 的发布,在 PyTorch torchvision 0.5 库中发布了 ResNet、ResNext、MobileNetV2、GoogleNet、InceptionV3 和 ShuffleNetV2 的量化模型。
PyTorch 支持 INT8 量化,相较于FP32,可实现模型大小减小 4 倍,内存带宽减小 2~4 倍。通常 INT8 计算速度 比FP32 快 2 ~ 4 倍(确切的加速速度因硬件、运行时和型号而异)。量化并非没有额外的成本。从根本上说,量化意味着引入近似值,由此产生的网络的精度略低,试图最小化全浮点精度和量化精度之间的差距。
PyTorch 支持多种量化深度学习模型的方法。大多数情况下,模型在 FP32 中训练,然后将模型转换为 INT8 。此外,PyTorch 还支持量化感知训练,对正向和后向传递中的量化误差进行建模。整个计算过程是在 浮点,在量化感知训练结束时,PyTorch 提供 转换函数,将训练的模型转换为较低的精度。
PyTorch 提供三种不同的量化模式:Eager Mode Quantization、FX Graph Mode Quantization 和 PyTorch 2 Export Quantization。
-
Eager Mode Quantization: 用户需要手动进行融合并指定量化和反量化发生的位置,而且它只支持模块而不是功能。
-
FX Graph Mode Quantization: PyTorch 中的自动量化工作流程,通过添加对泛函的支持和自动化量化过程来改进 Eager Mode Quantization,尽管人们可能需要重构模型以使模型与 FX Graph Mode Quantization 兼容(符号可追溯)
注意:FX Graph Mode Quantization 预计不适用于任意模型,因为该模型可能无法符号可追溯,PyTorch 会将其集成到 torchvision 等域库中,用户将能够使用 FX Graph Mode Quantization 量化类似于支持的域库中的模型。对于任意模型,将提供一般指南,但要使其实际工作,用户可能需要熟悉,尤其是如何使模型具有符号可追溯性,如
torch.fxtorch.fx -
PyTorch 2 导出量化:是新的全图模式量化工作流,是为 torch.export 捕获的模型构建的,考虑到建模用户和后端开发人员的灵活性和生产力。主要特点有
- 可编程 API,用于配置模型的量化方式,可以扩展到更多用例 。
- 简化了建模用户和后端开发人员的用户体验,只需要与单个对象(Quantizer)进行交互,以表达用户对如何量化模型以及后端支持的内容的意图。
- 可选的参考量化模型表示,可以表示具有整数运算的量化计算,以更接近于硬件中发生的实际量化计算。
支持三种类型的量化:
动态量化(dynamic quantization)(使用读取/存储的激活量化权重、浮点数和量化计算)
静态量化(static quantization)(权重量化、激活量化、校准训练)
静态量化感知训练(static quantization aware training)(权重量化、激活量化、 训练期间建模的量化数值)
量化流程
一般来说,流程如下
- 准备
- 根据用户指定的 qconfig 插入 Observer/FakeQuantize 模块
- 校准/训练(取决于训练后量化或量化感知训练)
- 允许观察者收集统计数据或 FakeQuantize 模块来学习量化参数
- 转换
- 将校准/训练的模型转换为量化模型
有不同的量化模式,它们可以通过两种方式进行分类:
就应用量化流程的位置而言,分为:
- 训练后量化(训练后应用量化,根据样本校准数据计算量化参数)
- 量化感知训练(在训练期间模拟量化,以便可以使用训练数据与模型一起学习量化参数)
就如何量化运算符而言,分为:
- 仅权重量化(仅静态量化重量)
- 动态量化(重量静态量化,激活动态量化)
- 静态量化(权重和激活都是静态量化的)
并且可以在同一量化流程中混合使用不同的量化运算符方法。例如,可以进行训练后量化,该量化同时具有静态和动态量化的运算符。
| 操作 | 静态量化 | 动态量化 |
|---|---|---|
| nn.Linear | Y | Y |
| nn.Conv1d/2d/3d | Y | N |
| nn.LSTM | Y (通过自定义) | Y |
| nn.GRU | N | Y |
| nn.RNNCell | N | Y |
| nn.GRUCell | N | Y |
| nn.LSTMCell | N | Y |
| nn.EmbeddingBag | Y (激活fp32) | Y |
| nn.Embedding | Y | Y |
| nn.MultiheadAttention | Y (通过自定义) | 不支持 |
| nn.LSTMCell | N | Y |
| nn.LSTMCell | N | Y |
| nn.LSTMCell | N | Y |
动态量化
最简单的量化方法称为动态量化。不仅涉及将权重转换为 int8,而且还涉及在进行计算之前将激活转换为 int8(。因此,计算将使用高效的 int8 矩阵乘法和卷积实现来执行,从而实现更快的计算速度。但是,激活以浮点格式读取和写入内存。
API:
PyTorch 中有一个简单的动态量化 API。 采用一个模型,以及其他几个参数,并生成一个量化的模型!端到端教程针对 BERT 模型说明了这一点;虽然本教程很长,并且包含有关加载预训练模型和其他与量化无关的概念的部分,但量化 BERT 模型的部分很简单:torch.quantization.quantize_dynamic
import torch.quantization
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
训练后量化
通过将网络转换为使用整数算术和 int8 内存访问,可以进一步提高性能。静态量化执行额外的步骤,即首先通过网络输入批次数据并计算不同激活的结果分布。此信息用于确定在推理时应如何具体量化不同的激活。重要的是,这个额外的步骤允许我们在操作之间传递量化值,而不是在每次操作之间将这些值转换为浮点数,然后再转换回整数,从而显着加快速度。
支持多项功能,允许用户优化其静态量化:
- 观察者:可以自定义观察者模块,这些模块指定在量化之前如何收集统计数据,以尝试更高级的方法来量化数据。
- 算子融合:可以将多个操作融合为单个操作,从而节省内存访问,同时提高操作的数值精度。
- 通道量化:可以独立量化卷积/线性层中每个输出通道的权重,在几乎相同的速度下获得更高的精度。
API:
- 融合算子:
torch.quantization.fuse_modules - 观察者 :
torch.quantization.prepare - 量化 :
torch.quantization.convert
代码示例:
# set quantization config for server (x86)
deploymentmyModel.qconfig = torch.quantization.get_default_config('fbgemm')
# insert observers
torch.quantization.prepare(myModel, inplace=True)
# Calibrate the model and collect statistics
# convert to quantized version
torch.quantization.convert(myModel, inplace=True)
量化感知训练
量化感知训练 (QAT) 通常是精度最高的方法。使用 QAT,在训练的前向和后向传递过程中,所有权重和激活都是“假量化的”:也就是说,浮点值被舍入以模拟 int8 值,但所有计算仍然使用浮点数完成。因此,训练期间的所有权重调整都是在“意识到”模型最终将被量化这一事实的情况下进行的;因此,在量化后,这种方法通常比其他两种方法产生更高的准确性。
API:
- 插入假量化模块以对量化进行建模 :
torch.quantization.prepare_qat - 模拟静态量化 API,在训练完成后实际量化模型:
torch.quantization.convert
代码示例:
# specify quantization config for QAT
qat_model.qconfig=torch.quantization.get_default_qat_qconfig('fbgemm')
# prepare QAT
torch.quantization.prepare_qat(qat_model, inplace=True)
# convert to quantized version, removing dropout, to check for accuracy on each
epochquantized_model=torch.quantization.convert(qat_model.eval(), inplace=False)
Eager 模式量化
训练后动态量化
在推理过程中,权重为提前量化,但激活是动态量化的。模型执行时间主要是从内存中加载权重,而不是计算矩阵 乘法。对于具有小批量 LSTM 和 Transformer 类型型号也是如此 。<PyTorch动态量化教程>
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32
/
linear_weight_fp32
# dynamically quantized model
# linear and LSTM weights are in int8
previous_layer_fp32 -- linear_int8_w_fp32_inp -- activation_fp32 -- next_layer_fp32
/
linear_weight_int8
代码示例:
import torch
# define a floating point model
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(4, 4)
def forward(self, x):
x = self.fc(x)
return x
# create a model instance
model_fp32 = M()
# create a quantized model instance
model_int8 = torch.ao.quantization.quantize_dynamic(
model_fp32, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8) # the target dtype for quantized weights
# run the model
input_fp32 = torch.randn(4, 4, 4, 4)
res = model_int8(input_fp32)
训练后静态量化
量化模型的权重和激活。在可能的情况,会将激活融合到前面的层中,并需要使用具有代表性的数据集进行校准,以确定最佳量化激活的参数。训练后静态量化通常用于以下情况 内存带宽和计算节省都很重要,CNN 是 典型用例。<PyTorch静态量化教程>
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32
/
linear_weight_fp32
# statically quantized model
# weights and activations are in int8
previous_layer_int8 -- linear_with_activation_int8 -- next_layer_int8
/
linear_weight_int8
代码示例:
import torch
# define a floating point model where some layers could be statically quantized
class M(torch.nn.Module):
def __init__(self):
super().__init__()
# QuantStub converts tensors from floating point to quantized
self.quant = torch.ao.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
self.relu = torch.nn.ReLU()
# DeQuantStub converts tensors from quantized to floating point
self.dequant = torch.ao.quantization.DeQuantStub()
def forward(self, x):
# manually specify where tensors will be converted from floating
# point to quantized in the quantized model
x = self.quant(x)
x = self.conv(x)
x = self.relu(x)
# manually specify where tensors will be converted from quantized
# to floating point in the quantized model
x = self.dequant(x)
return x
# create a model instance
model_fp32 = M()
# model must be set to eval mode for static quantization logic to work
model_fp32.eval()
# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'x86' for server inference and 'qnnpack'
# for mobile inference. Other quantization configurations such as selecting
# symmetric or asymmetric quantization and MinMax or L2Norm calibration techniques
# can be specified here.
# Note: the old 'fbgemm' is still available but 'x86' is the recommended default
# for server inference.
# model_fp32.qconfig = torch.ao.quantization.get_default_qconfig('fbgemm')
model_fp32.qconfig = torch.ao.quantization.get_default_qconfig('x86')
# Fuse the activations to preceding layers, where applicable.
# This needs to be done manually depending on the model architecture.
# Common fusions include `conv + relu` and `conv + batchnorm + relu`
model_fp32_fused = torch.ao.quantization.fuse_modules(model_fp32, [['conv', 'relu']])
# Prepare the model for static quantization. This inserts observers in
# the model that will observe activation tensors during calibration.
model_fp32_prepared = torch.ao.quantization.prepare(model_fp32_fused)
# calibrate the prepared model to determine quantization parameters for activations
# in a real world setting, the calibration would be done with a representative dataset
input_fp32 = torch.randn(4, 1, 4, 4)
model_fp32_prepared(input_fp32)
# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be
# used with each activation tensor, and replaces key operators with quantized
# implementations.
model_int8 = torch.ao.quantization.convert(model_fp32_prepared)
# run the model, relevant calculations will happen in int8
res = model_int8(input_fp32)
静态量化的量化感知训练
量化感知训练 (QAT) 对训练期间量化的效果进行建模 与其他量化方法相比,具有更高的准确性。我们可以对静态、动态或仅权重量化进行 QAT。在 训练,所有计算均以浮点数完成,fake_quant模块 通过钳位和舍入对量化的影响进行建模,以模拟 INT8 的影响。模型转换后,权重和 激活被量化,激活被融合到前一层 在可能的情况下。它通常与 CNN 一起使用,并产生更高的准确性 与静态量化相比。。<PyTorch静态量化的准备> 、<PyTorch量化感知训练教程>
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32
/
linear_weight_fp32
# model with fake_quants for modeling quantization numerics during training
previous_layer_fp32 -- fq -- linear_fp32 -- activation_fp32 -- fq -- next_layer_fp32
/
linear_weight_fp32 -- fq
# quantized model
# weights and activations are in int8
previous_layer_int8 -- linear_with_activation_int8 -- next_layer_int8
/
linear_weight_int8
代码示例:
import torch
# define a floating point model where some layers could benefit from QAT
class M(torch.nn.Module):
def __init__(self):
super().__init__()
# QuantStub converts tensors from floating point to quantized
self.quant = torch.ao.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
self.bn = torch.nn.BatchNorm2d(1)
self.relu = torch.nn.ReLU()
# DeQuantStub converts tensors from quantized to floating point
self.dequant = torch.ao.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
x = self.dequant(x)
return x
# create a model instance
model_fp32 = M()
# model must be set to eval for fusion to work
model_fp32.eval()
# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'x86' for server inference and 'qnnpack'
# for mobile inference. Other quantization configurations such as selecting
# symmetric or asymmetric quantization and MinMax or L2Norm calibration techniques
# can be specified here.
# Note: the old 'fbgemm' is still available but 'x86' is the recommended default
# for server inference.
# model_fp32.qconfig = torch.ao.quantization.get_default_qconfig('fbgemm')
model_fp32.qconfig = torch.ao.quantization.get_default_qat_qconfig('x86')
# fuse the activations to preceding layers, where applicable
# this needs to be done manually depending on the model architecture
model_fp32_fused = torch.ao.quantization.fuse_modules(model_fp32,
[['conv', 'bn', 'relu']])
# Prepare the model for QAT. This inserts observers and fake_quants in
# the model needs to be set to train for QAT logic to work
# the model that will observe weight and activation tensors during calibration.
model_fp32_prepared = torch.ao.quantization.prepare_qat(model_fp32_fused.train())
# run the training loop (not shown)
training_loop(model_fp32_prepared)
# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be
# used with each activation tensor, fuses modules where appropriate,
# and replaces key operators with quantized implementations.
model_fp32_prepared.eval()
model_int8 = torch.ao.quantization.convert(model_fp32_prepared)
# run the model, relevant calculations will happen in int8
res = model_int8(input_fp32)
目前有必要对模型定义进行一些修改 在 Eager 模式量化之前。这是因为目前量化适用于模块 以模块为基础。具体而言,对于所有量化技术,用户需要:
-
转换任何需要输出重新量化的操作从函数到模块形式(如使用
torch.nn.functional.relu代替torch.nn.ReLU)。 -
通过在子模块上分配属性或指定 来指定需要量化的模型的哪些部分。 例如,设置表示图层不会被量化,设置意味着量化 的设置将改用 的全局 qconfig。如
.qconfig_mappingmodel.conv1.qconfig = None、model.convmodel.linear1.qconfig = custom_qconfigmodel.linear1custom_qconfig
对于量化激活的静态量化技术,用户需要此外,还要执行以下操作:
-
指定激活量化和取消量化的位置,使用 QuantStub 和 DeQuantStub模块完成的。
-
使用 FloatFunctional 包装张量运算 需要特殊处理才能量化为模块。如需要特殊处理的操作 确定输出量化参数。比如
add、cat -
融合模块:将操作/模块组合成一个模块以获得得更高的精度和性能。这是使用 fuse_modules()API 完成的,该 API 接收模块列表 要融合,目前支持以下融合:
[Conv, Relu],[Conv, BN],[Conv, BN, Relu],[Linear, Relu]
PSFR-GAN训练后静态量化
PSFR-GAN的论文和代码复现可移步PSFR-GAN:一种结合几何先验的渐进式复原网络、PSFR-GAN复现,其中对网络的进行详细说明。
PSFR-GAN的网络略大,参数达到了45M,权重文件约175M,同时推理速度较慢。由于提供了预训练的权重,因此可以考虑训练后量化。
训练后量化(静态量化)的步骤:
-
模型加载:创建网络实例,并加载预训练权重
-
模型准备:使用
torch.quantization.prepare准备模型,模型中会被插入模拟量化操作,用于记录数据分布,此时模型仍在浮点精度下运行。 -
校准数据:通过遍历校准数据集并执行模型的前向传播,即在校准循环中调用原模型,收集激活值的统计信息。
-
量化转换:在完成校准之后,利用收集到的统计信息对模型进行实际的量化,使用
torch.quantization.convert将其转换为低精度整数运算的模型。 -
保存量化模型:保存量化后的模型状态字典以适用于量化后的模型。
-
验证量化模型:使用量化模型进行前向传播验证量化模型。
模型加载
此处以PSFR-GAN代码中的示例说明模型的定义,加载以及前向传播的流程,方便后续对量化的理解。
'''
本脚本使用PSFR-GAN增强图像中的所有人脸,并将增强后的人脸贴回原图中的对应位置。
'''
import dlib
import os
import cv2
import numpy as np
from tqdm import tqdm
from skimage import transform as trans
from skimage import io
import torch
from utils import utils
from options.test_options import TestOptions
from models import create_model
#检测人脸并对齐,返回仿射变换的参数
def detect_and_align_faces(img, face_detector, lmk_predictor, template_path, template_scale=2, size_threshold=999):
align_out_size = (512, 512)
ref_points = np.load(template_path) / template_scale
face_dets = face_detector(img, 1)
assert len(face_dets) > 0, 'No faces detected'
aligned_faces = []
tform_params = []
for det in face_dets:
if isinstance(face_detector, dlib.cnn_face_detection_model_v1):
rec = det.rect # for cnn detector
else:
rec = det
if rec.width() > size_threshold or rec.height() > size_threshold:
break
landmark_points = lmk_predictor(img, rec)
single_points = []
for i in range(5):
single_points.append([landmark_points.part(i).x, landmark_points.part(i).y])
single_points = np.array(single_points)
tform = trans.SimilarityTransform()
tform.estimate(single_points, ref_points)
tmp_face = trans.warp(img, tform.inverse, output_shape=align_out_size, order=3)
aligned_faces.append(tmp_face*255)
tform_params.append(tform)
return [aligned_faces, tform_params]
#定义模型和加载预训练权重,并返回模型类,主要是生成器和先验获取网络
def def_models(opt):
model = create_model(opt)
model.load_pretrain_models()
model.netP.to(opt.device)
model.netG.to(opt.device)
return model
# 先验获取网络获取人脸解析图像,随后生成器进行复原
def enhance_faces(LQ_faces, model):
hq_faces = []
lq_parse_maps = []
for lq_face in tqdm(LQ_faces):
with torch.no_grad():
lq_tensor = torch.tensor(lq_face.transpose(2, 0, 1)) / 255. * 2 - 1
lq_tensor = lq_tensor.unsqueeze(0).float().to(model.device)
parse_map, _ = model.netP(lq_tensor)
parse_map_onehot = (parse_map == parse_map.max(dim=1, keepdim=True)[0]).float()
output_SR = model.netG(lq_tensor, parse_map_onehot)
hq_faces.append(utils.tensor_to_img(output_SR))
lq_parse_maps.append(utils.color_parse_map(parse_map_onehot)[0])
return hq_faces, lq_parse_maps
# 将复原后结果贴合原图
def past_faces_back(img, hq_faces, tform_params, upscale=1):
h, w = img.shape[:2]
img = cv2.resize(img, (int(w*upscale), int(h*upscale)), interpolation=cv2.INTER_CUBIC)
for hq_img, tform in tqdm(zip(hq_faces, tform_params), total=len(hq_faces)):
tform.params[0:2,0:2] /= upscale
back_img = trans.warp(hq_img/255., tform, output_shape=[int(h*upscale), int(w*upscale)], order=3) * 255
mask = (back_img == 0)
mask = cv2.blur(mask.astype(np.float32), (5,5))
mask = (mask > 0)
img = img * mask + (1 - mask) * back_img
return img.astype(np.uint8)
# 保存图像
def save_imgs(img_list, save_dir):
for idx, img in enumerate(img_list):
save_path = os.path.join(save_dir, '{:03d}.jpg'.format(idx))
io.imsave(save_path, img.astype(np.uint8))
if __name__ == '__main__':
opt = TestOptions().parse()
face_detector = dlib.cnn_face_detection_model_v1('./pretrain_models/mmod_human_face_detector.dat')
lmk_predictor = dlib.shape_predictor('./pretrain_models/shape_predictor_5_face_landmarks.dat')
template_path = './pretrain_models/FFHQ_template.npy'
# Loading images, crop and align faces.
img_path = opt.test_img_path
img = dlib.load_rgb_image(img_path)
aligned_faces, tform_params = detect_and_align_faces(img, face_detector, lmk_predictor, template_path)
# Save aligned LQ faces
save_lq_dir = os.path.join(opt.results_dir, 'LQ_faces')
os.makedirs(save_lq_dir, exist_ok=True)
save_imgs(aligned_faces, save_lq_dir)
# 复原图像
enhance_model = def_models(opt)
hq_faces, lq_parse_maps = enhance_faces(aligned_faces, enhance_model)
# 保存解析图和复原结果
save_parse_dir = os.path.join(opt.results_dir, 'ParseMaps')
save_hq_dir = os.path.join(opt.results_dir, 'HQ')
os.makedirs(save_parse_dir, exist_ok=True)
os.makedirs(save_hq_dir, exist_ok=True)
save_imgs(lq_parse_maps, save_parse_dir)
save_imgs(hq_faces, save_hq_dir)
hq_img = past_faces_back(img, hq_faces, tform_params, upscale=opt.test_upscale)
final_save_path = os.path.join(opt.results_dir, 'hq_final.jpg')
io.imsave(final_save_path, hq_img)
静态量化
按照上述的量化的过程:模型加载、模型准备、校准数据、量化转换、保存量化模型、验证量化模型。
模型定义
模型的定义需要解析测试的选项,调用上述的函数,如下:
def def_models(opt):
# 定义模型,最后返回原模型和量化后的图像
model = create_model(opt)
# 加载预训练权重,其中以及确定了eval()
model.load_pretrain_models()
# 获取生成器网络
model_fp32 = model.netG
# 预定义的量化配置,使用FBGEMM作为后端的静态量化,适合于Intel x86架构的CPU。
model_fp32.qconfig = torch.quantization.get_default_qconfig('fbgemm')
# 模型准备,部分pytorch不具有torch.ao.quantization.prepare
model_fp32_prepared = torch.quantization.prepare(model_fp32, inplace=False)
# 模型校准,遍历校准文件,input_fp32 是低质量图像,input_fp32_2 是人脸解析图
path = 'Calibrate_data'
pics = os.listdir(path)
for i, name in enumerate(tqdm(pics)):
input_fp32 = cv2.imread(os.path.join(path, name))
with torch.no_grad():
input_fp32 = torch.tensor(input_fp32.transpose(2, 0, 1)) / 255. * 2 - 1
input_fp32 = input_fp32.unsqueeze(0).float().to(model.device)
input_fp32_2, _ = model.netP(input_fp32)
input_fp32_2 = (input_fp32_2 == input_fp32_2.max(dim=1, keepdim=True)[0]).float()
model_fp32_prepared(input_fp32, input_fp32_2)
# 量化转换
model_int8 = torch.ao.quantization.convert(model_fp32_prepared, inplace=True)
# 保存量化模型
torch.save(model_int8.state_dict(), 'quantized_model.pth')
# 验证量化模型
res = model_int8(input_fp32, input_fp32_2)
return model, model_int8
后续复原时候调用量化后的模型即可,如下:
def enhance_faces(LQ_faces, model, model_int8):
hq_faces = []
lq_parse_maps = []
for lq_face in tqdm(LQ_faces):
with torch.no_grad():
lq_tensor = torch.tensor(lq_face.transpose(2, 0, 1)) / 255. * 2 - 1
lq_tensor = lq_tensor.unsqueeze(0).float().to(model.device)
parse_map, _ = model.netP(lq_tensor)
parse_map_onehot = (parse_map == parse_map.max(dim=1, keepdim=True)[0]).float()
# 调用model_int8
output_SR = model_int8(lq_tensor, parse_map_onehot)
hq_faces.append(utils.tensor_to_img(output_SR))
lq_parse_maps.append(utils.color_parse_map(parse_map_onehot)[0])
return hq_faces, lq_parse_maps
QuantStub 和 DeQuantStub
此外,静态量化还需要在网络中手动插入torch.quantization.QuantStub 和 torch.quantization.DeQuantStub用于在模型的输入和输出端桥接浮点运算与量化运算。
torch.quantization.QuantStub: 用作模型输入端的占位符,用于将浮点张量量化为固定精度的张量(通常是8位整数)。当模型开始执行前向传播时,QuantStub会接收浮点输入,并根据预先设定的量化参数(如scale和zero_point)对其进行量化。减少模型输入数据的精度和内存占用,为后续的量化层做准备。torch.quantization.DeQuantStub: DeQuantStub用在模型的输出端,负责将量化后的张量转换回浮点张量。这意味着在模型的最后,量化结果会被转换回更高的精度,以便于后续的处理、评估或进一步的计算,尤其是在需要浮点精度的场景下。
PSFR-GAN不同于其他的单输入网络,有两个输入退化图像和人脸解析图,同时复原过程起源于一个可学习的常向量,因此需要对上述内容进行输入量化,即需要多个QuantStub,当然网络输出只需一个DeQuantStub。如下:
class PSFRGenerator(nn.Module):
def __init__(self, input_nc, output_nc, in_size=512, out_size=512, min_feat_size=16, ngf=64, n_blocks=9, parse_ch=19, relu_type='relu',
ch_range=[32, 1024], norm_type='spade'):
super().__init__()
self.quant_x_ref = torch.quantization.QuantStub()
self.quant_const = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()
....略略略
def forward(self, x, ref):
b, c, h, w = x.shape
const_input = nn.Parameter(self.const_input.repeat(b, 1, 1, 1))
ref_input = torch.cat((x, ref), dim=1)
# 这里插入两个量化接口
ref_input = self.quant_x_ref(ref_input)
const_input = self.quant_const(const_input)
feat = self.forward_spade(self.head, const_input, ref_input)
for idx, m in enumerate(self.body):
feat = self.forward_spade(m, feat, ref_input)
feat = self.img_out(feat)
# 反量化接口
feat = self.dequant(feat)
return feat
运算改写
PSFR-GAN自定义了SPADENorm、SPADEResBlock类,继承于nn.Module,理论上是支持量化操作的。但是在调制和残差结构中引入乘法和加法,无法对量化后的参数进行运算,需要改写。
主要使用torch.ao.nn.quantized.FloatFunctional 进行改写以适配量化的数据。根据所及的torch的版本来实现,不同版本可能API接口不一致。
修改前:
class SPADENorm(nn.Module):
def __init__(self, norm_nc, ref_nc, norm_type='spade', ksz=3):
super().__init__()
...略
def forward(self, x, ref):
normalized_input = self.param_free_norm(x)
if x.shape[-1] != ref.shape[-1]:
ref = nn.functional.interpolate(ref, x.shape[2:], mode='bilinear', align_corners=False)
if self.norm_type == 'spade':
gamma, beta = self.get_gamma_beta(ref, self.conv1, self.gamma_conv, self.beta_conv)
# 这里会有问题
return normalized_input*gamma + beta
elif self.norm_type == 'in':
return normalized_input
修改后:
class SPADENorm(nn.Module):
def __init__(self, norm_nc, ref_nc, norm_type='spade', ksz=3):
super().__init__()
self.Float_act = nn.quantized.FloatFunctional()
...略
def forward(self, x, ref):
normalized_input = self.param_free_norm(x)
if x.shape[-1] != ref.shape[-1]:
ref = nn.functional.interpolate(ref, x.shape[2:], mode='bilinear', align_corners=False)
if self.norm_type == 'spade':
gamma, beta = self.get_gamma_beta(ref, self.conv1, self.gamma_conv, self.beta_conv)
# Float_act 的子函数替代*、+
return self.Float_act .add(self.Float_act .mul(normalized_input, gamma), beta)
elif self.norm_type == 'in':
return normalized_input
同理,对于SPADEResBlock,也只是需要这样进行替换。
修改前:
class SPADEResBlock(nn.Module):
def __init__(self, fin, fout, ref_nc, relu_type, norm_type='spade'):
super().__init__()
...略
def forward(self, x, ref):
out = self.norm_0(x, ref)
out = self.relu(out)
out = self.conv_0(out)
res = self.norm_1(out, ref)
res = self.relu(res)
res = self.conv_1(res)
# 需要替换 +
out = x + res
return out
修改后:
class SPADEResBlock(nn.Module):
def __init__(self, fin, fout, ref_nc, relu_type, norm_type='spade'):
super().__init__()
...略
self.skip_add = nn.quantized.FloatFunctional()
def forward(self, x, ref):
out = self.norm_0(x, ref)
out = self.relu(out)
out = self.conv_0(out)
res = self.norm_1(out, ref)
res = self.relu(res)
res = self.conv_1(res)
# 需要替换 +
out = self.skip_add.add(x, res)
return out
量化踩坑记录
1. get_default_qconfig缺失
在PyTorch中多是使用torch.ao.quantization.get_default_qconfig函数获取量化配置,在一些版本中移动到其他的路径。
在 PyTorch 1.10.2 中,确实存在
get_default_qconfig函数,但该函数位于torch.quantization模块中,而不是torch.ao.quantization。
从 PyTorch 1.8 开始,量化 API 已经发生了一些变化,因此建议使用 torch.quantization 而不是 torch.ao.quantization。
2. Only Tensors created explicitly by the user support the deepcopy protocol at the moment
convert函数拥有参数inplace,即是否原地修改,默认是不会原地修改,才是会将 module深拷贝,再进行转换,保留原始模块不变。convert函数如下:
def convert(
module, mapping=None, inplace=False, remove_qconfig=True,
convert_custom_config_dict=None):
torch._C._log_api_usage_once("quantization_api.quantize.convert")
if not inplace:
module = copy.deepcopy(module)
_convert(
module, mapping, inplace=True,
convert_custom_config_dict=convert_custom_config_dict)
if remove_qconfig:
_remove_qconfig(module)
return module
因此需要检查不是由用户直接创建的Tensor。在PyTorch中,Tensor通常是计算图的一部分,它们的值是由其他Tensor的操作计算得到的。由于这些Tensor的值是通过计算得到的,所以直接对它们进行深拷贝可能会导致不可预期的行为或者错误。其次需要确定转化前是否都插入的量化和去量化,静态量化往往需要手动插入。另外对于自定义类封装了Tensor对象,需要正确实现深拷贝所需的特殊方法(如__deepcopy__)。
3. AttributeError: ‘Conv2d’ object has no attribute ‘weight_orig’
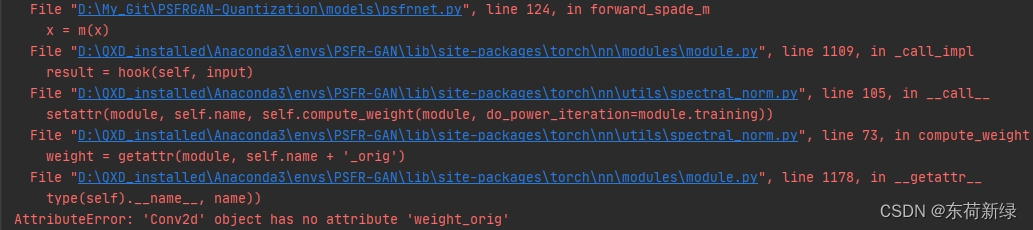
报错截图如上,其中很明显的可定位到频谱归一化中,根据以下代码发现,针对nn.Conv2d进行了归一化。
def apply_norm(net, weight_norm_type):
for m in net.modules():
if isinstance(m, nn.Conv2d):
if weight_norm_type.lower() == 'spectral_norm':
tutils.spectral_norm(m)
m.weight_orig = nn.Parameter(m.weight.data.clone())
elif weight_norm_type.lower() == 'weight_norm':
tutils.weight_norm(m)
else:
pass
其频谱归一化的实现如下,其中并未直接分配权重,而是需要将权重重新分配为fn.name,因为各种事情都可能假设它存在,例如,在初始化权重时可能是一个nn.Parameter,并作为参数添加。相反,将weight.data注册为常规属性,并注册了"weight_orig"。归一化后,量化后导致了nn.Conv2d缺失该属性。
@staticmethod
def apply(module: Module, name: str, n_power_iterations: int, dim: int, eps: float) -> 'SpectralNorm':
for k, hook in module._forward_pre_hooks.items():
if isinstance(hook, SpectralNorm) and hook.name == name:
raise RuntimeError("Cannot register two spectral_norm hooks on "
"the same parameter {}".format(name))
fn = SpectralNorm(name, n_power_iterations, dim, eps)
weight = module._parameters[name]
if weight is None:
raise ValueError(f'`SpectralNorm` cannot be applied as parameter `{name}` is None')
if isinstance(weight, torch.nn.parameter.UninitializedParameter):
raise ValueError(
'The module passed to `SpectralNorm` can\'t have uninitialized parameters. '
'Make sure to run the dummy forward before applying spectral normalization')
with torch.no_grad():
weight_mat = fn.reshape_weight_to_matrix(weight)
h, w = weight_mat.size()
# randomly initialize `u` and `v`
u = normalize(weight.new_empty(h).normal_(0, 1), dim=0, eps=fn.eps)
v = normalize(weight.new_empty(w).normal_(0, 1), dim=0, eps=fn.eps)
delattr(module, fn.name)
module.register_parameter(fn.name + "_orig", weight)
setattr(module, fn.name, weight.data)
module.register_buffer(fn.name + "_u", u)
module.register_buffer(fn.name + "_v", v)
module.register_forward_pre_hook(fn)
module._register_state_dict_hook(SpectralNormStateDictHook(fn))
module._register_load_state_dict_pre_hook(SpectralNormLoadStateDictPreHook(fn))
return fn
因此在定义生成器的时候不做频谱归一化,在量化后再进行频谱归一化。如下:
def define_G(opt, isTrain=True, use_norm='none', relu_type='LeakyReLU'):
net = psfrnet.PSFRGenerator(3, 3, in_size=opt.Gin_size, out_size=opt.Gout_size, relu_type=relu_type, parse_ch=19, norm_type=opt.Gnorm)
# apply_norm(net, use_norm)
# 量化转换
model_int8 = torch.ao.quantization.convert(model_fp32_prepared, inplace=True)
apply_qnorm(model_int8, 'spectral_norm')
4. 运算改写
相对深一点的网络,几乎都会使用残差结构。对于一些注意力或自定义类,难免会使用四则运算,甚至更多的数学运算方法。但是很可惜,他们均不支持直接量化。因此需要对上述运算进行修改。
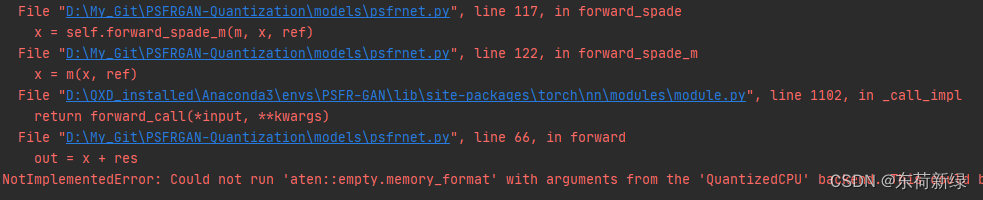
引用 一次失败的Pytorch模型量化尝试:加减乘除都是不支持量化的,要想放在量化里,需要先dequant,计算完再 quant。
尽管这样可以工作,但是我认为这样并不好,dequant,quant通常只会出现在模型的输入与输出位置,再次添加这个量化算子,只是为了确保操作的可运算。
因此建议使用nn.quantized.FloatFunctional。像这样 使用其中的函数(add、cat、mul、add_relu、add_scalar、mul_scalar)
修改内容:
self.skip_add = nn.quantized.FloatFunctional()
out = self.skip_add.add(x, res)
5. 上采样模式
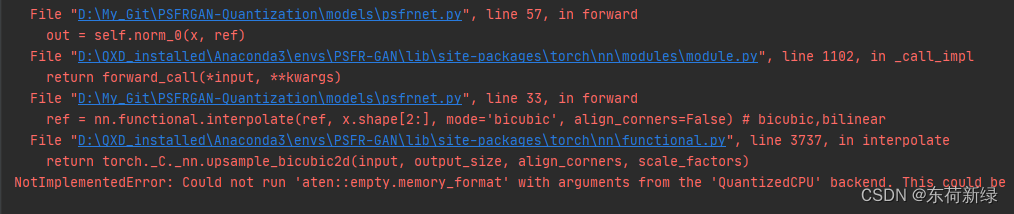
报错定位:
ref = nn.functional.interpolate(ref, x.shape[2:], mode=‘bicubic’, align_corners=False)
顺便贴下源码,bicubic双三次插值会调用torch._C._nn.upsample_bicubic2d(input, output_size, align_corners, scale_factors),然而其不支持量化。原因不明,退而求其次,将其替换为双线性插值。并在原模型上做过测试,对最后的结果几乎没有影响。
def interpolate(input: Tensor, size: Optional[int] = None, scale_factor: Optional[List[float]] = None, mode: str = 'nearest', align_corners: Optional[bool] = None, recompute_scale_factor: Optional[bool] = None) -> Tensor:
if has_torch_function_unary(input):
return handle_torch_function(
interpolate,
(input,),
input,
size=size,
scale_factor=scale_factor,
mode=mode,
align_corners=align_corners,
recompute_scale_factor=recompute_scale_factor,
)
if mode in ("nearest", "area"):
if align_corners is not None:
raise ValueError(
"align_corners option can only be set with the "
"interpolating modes: linear | bilinear | bicubic | trilinear"
)
else:
if align_corners is None:
warnings.warn(
"Default upsampling behavior when mode={} is changed "
"to align_corners=False since 0.4.0. Please specify "
"align_corners=True if the old behavior is desired. "
"See the documentation of nn.Upsample for details.".format(mode)
)
align_corners = False
dim = input.dim() - 2 # Number of spatial dimensions.
if size is not None and scale_factor is not None:
raise ValueError("only one of size or scale_factor should be defined")
elif size is not None:
assert scale_factor is None
scale_factors = None
if isinstance(size, (list, tuple)):
if len(size) != dim:
raise ValueError(
"size shape must match input shape. " "Input is {}D, size is {}".format(dim, len(size))
)
output_size = size
else:
output_size = [size for _ in range(dim)]
elif scale_factor is not None:
assert size is None
output_size = None
if isinstance(scale_factor, (list, tuple)):
if len(scale_factor) != dim:
raise ValueError(
"scale_factor shape must match input shape. "
"Input is {}D, scale_factor is {}".format(dim, len(scale_factor))
)
scale_factors = scale_factor
else:
scale_factors = [scale_factor for _ in range(dim)]
else:
raise ValueError("either size or scale_factor should be defined")
if recompute_scale_factor is None:
# only warn when the scales have floating values since
# the result for ints is the same with/without recompute_scale_factor
if scale_factors is not None:
for scale in scale_factors:
if math.floor(scale) != scale:
warnings.warn(
"The default behavior for interpolate/upsample with float scale_factor changed "
"in 1.6.0 to align with other frameworks/libraries, and now uses scale_factor directly, "
"instead of relying on the computed output size. "
"If you wish to restore the old behavior, please set recompute_scale_factor=True. "
"See the documentation of nn.Upsample for details. "
)
break
elif recompute_scale_factor and size is not None:
raise ValueError("recompute_scale_factor is not meaningful with an explicit size.")
# "area" mode always requires an explicit size rather than scale factor.
# Re-use the recompute_scale_factor code path.
if mode == "area" and output_size is None:
recompute_scale_factor = True
if recompute_scale_factor is not None and recompute_scale_factor:
# We compute output_size here, then un-set scale_factors.
# The C++ code will recompute it based on the (integer) output size.
if not torch.jit.is_scripting() and torch._C._get_tracing_state():
# make scale_factor a tensor in tracing so constant doesn't get baked in
output_size = [
(torch.floor((input.size(i + 2).float() * torch.tensor(scale_factors[i], dtype=torch.float32)).float()))
for i in range(dim)
]
else:
assert scale_factors is not None
output_size = [int(math.floor(float(input.size(i + 2)) * scale_factors[i])) for i in range(dim)]
scale_factors = None
if input.dim() == 3 and mode == "nearest":
return torch._C._nn.upsample_nearest1d(input, output_size, scale_factors)
if input.dim() == 4 and mode == "nearest":
return torch._C._nn.upsample_nearest2d(input, output_size, scale_factors)
if input.dim() == 5 and mode == "nearest":
return torch._C._nn.upsample_nearest3d(input, output_size, scale_factors)
if input.dim() == 3 and mode == "area":
assert output_size is not None
return adaptive_avg_pool1d(input, output_size)
if input.dim() == 4 and mode == "area":
assert output_size is not None
return adaptive_avg_pool2d(input, output_size)
if input.dim() == 5 and mode == "area":
assert output_size is not None
return adaptive_avg_pool3d(input, output_size)
if input.dim() == 3 and mode == "linear":
assert align_corners is not None
return torch._C._nn.upsample_linear1d(input, output_size, align_corners, scale_factors)
if input.dim() == 4 and mode == "bilinear":
assert align_corners is not None
return torch._C._nn.upsample_bilinear2d(input, output_size, align_corners, scale_factors)
if input.dim() == 5 and mode == "trilinear":
assert align_corners is not None
return torch._C._nn.upsample_trilinear3d(input, output_size, align_corners, scale_factors)
if input.dim() == 4 and mode == "bicubic":
assert align_corners is not None
return torch._C._nn.upsample_bicubic2d(input, output_size, align_corners, scale_factors)
if input.dim() == 3 and mode == "bilinear":
raise NotImplementedError("Got 3D input, but bilinear mode needs 4D input")
if input.dim() == 3 and mode == "trilinear":
raise NotImplementedError("Got 3D input, but trilinear mode needs 5D input")
if input.dim() == 4 and mode == "linear":
raise NotImplementedError("Got 4D input, but linear mode needs 3D input")
if input.dim() == 4 and mode == "trilinear":
raise NotImplementedError("Got 4D input, but trilinear mode needs 5D input")
if input.dim() == 5 and mode == "linear":
raise NotImplementedError("Got 5D input, but linear mode needs 3D input")
if input.dim() == 5 and mode == "bilinear":
raise NotImplementedError("Got 5D input, but bilinear mode needs 4D input")
raise NotImplementedError(
"Input Error: Only 3D, 4D and 5D input Tensors supported"
" (got {}D) for the modes: nearest | linear | bilinear | bicubic | trilinear"
" (got {})".format(input.dim(), mode)
)
修改后:
ref = nn.functional.interpolate(ref, x.shape[2:], mode='bilinear', align_corners=False) # bicubic,bilinear
量化后结果
放个定性结果:
| 效果 | |
|---|---|
| 量化前 |  |
| 量化后 |  |
模型权重大小由175M降到了45M,复原效果可以差别不大。打印量化后的结构,其中并未出现scale=1,zero_point=0的情形,因此量化应该是正常的。
PSFRGenerator(
(quant_x): Quantize(scale=tensor([0.0157]), zero_point=tensor([64]), dtype=torch.quint8)
(quant_ref): Quantize(scale=tensor([0.0079]), zero_point=tensor([0]), dtype=torch.quint8)
(quant_const): Quantize(scale=tensor([0.0648]), zero_point=tensor([61]), dtype=torch.quint8)
(dequant): DeQuantize()
(img_out): QuantizedConv2d(32, 3, kernel_size=(3, 3), stride=(1, 1), scale=0.0037965355440974236, zero_point=89, padding=(1, 1))
(head): Sequential(
(0): QuantizedConv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), scale=0.03470570966601372, zero_point=64, padding=(1, 1))
(1): SPADEResBlock(
(conv_0): QuantizedConv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), scale=0.0030816197395324707, zero_point=68, padding=(1, 1))
(conv_1): QuantizedConv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), scale=0.003961088135838509, zero_point=67, padding=(1, 1))
(norm_0): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(1024, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.011442513205111027, zero_point=62
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.01103975996375084, zero_point=65, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 1024, kernel_size=(3, 3), stride=(1, 1), scale=0.004541737027466297, zero_point=61, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 1024, kernel_size=(3, 3), stride=(1, 1), scale=0.005080984439700842, zero_point=68, padding=(1, 1))
)
(norm_1): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(1024, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.019119564443826675, zero_point=75
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.011305421590805054, zero_point=62, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 1024, kernel_size=(3, 3), stride=(1, 1), scale=0.006097389850765467, zero_point=63, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 1024, kernel_size=(3, 3), stride=(1, 1), scale=0.006074673496186733, zero_point=77, padding=(1, 1))
)
(relu): ReluLayer(
(func): QuantizedLeakyReLU(negative_slope=0.2)
)
(skip_add): QFunctional(
scale=1.0, zero_point=0
(activation_post_process): Identity()
)
)
)
(body): Sequential(
(0): Sequential(
(0): Upsample(scale_factor=2.0, mode=nearest)
(1): QuantizedConv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), scale=0.023008238524198532, zero_point=67, padding=(1, 1))
(2): SPADEResBlock(
(conv_0): QuantizedConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), scale=0.003956107422709465, zero_point=64, padding=(1, 1))
(conv_1): QuantizedConv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), scale=0.005073028150945902, zero_point=61, padding=(1, 1))
(norm_0): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(512, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.012949546799063683, zero_point=71
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.010161954909563065, zero_point=62, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 512, kernel_size=(3, 3), stride=(1, 1), scale=0.005322112701833248, zero_point=60, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 512, kernel_size=(3, 3), stride=(1, 1), scale=0.005141070112586021, zero_point=76, padding=(1, 1))
)
(norm_1): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(512, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.026061255484819412, zero_point=61
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.010233106091618538, zero_point=60, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 512, kernel_size=(3, 3), stride=(1, 1), scale=0.005527239292860031, zero_point=66, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 512, kernel_size=(3, 3), stride=(1, 1), scale=0.006278217304497957, zero_point=80, padding=(1, 1))
)
(relu): ReluLayer(
(func): QuantizedLeakyReLU(negative_slope=0.2)
)
(skip_add): QFunctional(
scale=1.0, zero_point=0
(activation_post_process): Identity()
)
)
)
(1): Sequential(
(0): Upsample(scale_factor=2.0, mode=nearest)
(1): QuantizedConv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), scale=0.0119480537250638, zero_point=62, padding=(1, 1))
(2): SPADEResBlock(
(conv_0): QuantizedConv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), scale=0.00446848152205348, zero_point=64, padding=(1, 1))
(conv_1): QuantizedConv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), scale=0.00437450036406517, zero_point=60, padding=(1, 1))
(norm_0): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(256, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.013236685656011105, zero_point=74
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.010716605000197887, zero_point=76, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), scale=0.004494662396609783, zero_point=70, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), scale=0.005533156450837851, zero_point=80, padding=(1, 1))
)
(norm_1): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(256, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.022021740674972534, zero_point=57
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.01037409994751215, zero_point=73, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), scale=0.005922837648540735, zero_point=65, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), scale=0.005561243277043104, zero_point=67, padding=(1, 1))
)
(relu): ReluLayer(
(func): QuantizedLeakyReLU(negative_slope=0.2)
)
(skip_add): QFunctional(
scale=1.0, zero_point=0
(activation_post_process): Identity()
)
)
)
(2): Sequential(
(0): Upsample(scale_factor=2.0, mode=nearest)
(1): QuantizedConv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), scale=0.007751958444714546, zero_point=63, padding=(1, 1))
(2): SPADEResBlock(
(conv_0): QuantizedConv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), scale=0.004601106978952885, zero_point=61, padding=(1, 1))
(conv_1): QuantizedConv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), scale=0.004787528421729803, zero_point=66, padding=(1, 1))
(norm_0): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(128, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.013313686475157738, zero_point=55
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.009437579661607742, zero_point=70, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), scale=0.004759690724313259, zero_point=70, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), scale=0.004415410105139017, zero_point=68, padding=(1, 1))
)
(norm_1): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(128, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.026812681928277016, zero_point=60
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.01226135715842247, zero_point=74, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), scale=0.0062740035355091095, zero_point=64, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), scale=0.00461485143750906, zero_point=69, padding=(1, 1))
)
(relu): ReluLayer(
(func): QuantizedLeakyReLU(negative_slope=0.2)
)
(skip_add): QFunctional(
scale=1.0, zero_point=0
(activation_post_process): Identity()
)
)
)
(3): Sequential(
(0): Upsample(scale_factor=2.0, mode=nearest)
(1): QuantizedConv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.0053002601489424706, zero_point=62, padding=(1, 1))
(2): SPADEResBlock(
(conv_0): QuantizedConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.005268410313874483, zero_point=67, padding=(1, 1))
(conv_1): QuantizedConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.005959701724350452, zero_point=61, padding=(1, 1))
(norm_0): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(64, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.0186650101095438, zero_point=70
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.011738518252968788, zero_point=60, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.005502034444361925, zero_point=65, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.005726460833102465, zero_point=73, padding=(1, 1))
)
(norm_1): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(64, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.025194190442562103, zero_point=67
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.011793921701610088, zero_point=71, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.006060307379812002, zero_point=67, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.004161233082413673, zero_point=75, padding=(1, 1))
)
(relu): ReluLayer(
(func): QuantizedLeakyReLU(negative_slope=0.2)
)
(skip_add): QFunctional(
scale=1.0, zero_point=0
(activation_post_process): Identity()
)
)
)
(4): Sequential(
(0): Upsample(scale_factor=2.0, mode=nearest)
(1): QuantizedConv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), scale=0.004231343977153301, zero_point=57, padding=(1, 1))
(2): SPADEResBlock(
(conv_0): QuantizedConv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), scale=0.007452615536749363, zero_point=65, padding=(1, 1))
(conv_1): QuantizedConv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), scale=0.006485114339739084, zero_point=68, padding=(1, 1))
(norm_0): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(32, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.025958331301808357, zero_point=68
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.010474645532667637, zero_point=67, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), scale=0.005492656957358122, zero_point=69, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), scale=0.009008409455418587, zero_point=69, padding=(1, 1))
)
(norm_1): SPADENorm(
(param_free_norm): QuantizedInstanceNorm2d(32, eps=1e-05, momentum=False, affine=False, track_running_stats=False)
(add_act): QFunctional(
scale=0.026988424360752106, zero_point=54
(activation_post_process): Identity()
)
(conv1): Sequential(
(0): QuantizedConv2d(22, 64, kernel_size=(3, 3), stride=(1, 1), scale=0.014506259933114052, zero_point=59, padding=(1, 1))
(1): QuantizedLeakyReLU(negative_slope=0.2)
)
(gamma_conv): QuantizedConv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), scale=0.006679795682430267, zero_point=47, padding=(1, 1))
(beta_conv): QuantizedConv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), scale=0.006468005478382111, zero_point=80, padding=(1, 1))
)
(relu): ReluLayer(
(func): QuantizedLeakyReLU(negative_slope=0.2)
)
(skip_add): QFunctional(
scale=1.0, zero_point=0
(activation_post_process): Identity()
)
)
)
)
(upsample): Upsample(scale_factor=2.0, mode=nearest)
)
敲黑板:频谱归一化可能会导致量化异常。即便是量化后再做频谱归一化,也会存在问题。因此只建议对判别器做频谱归一化。
致谢
欲尽善本文,因所视短浅,怎奈所书皆是瞽言蒭议。行文至此,诚向予助与余者致以谢意。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











