







数据结构
1
需要修改或者免费资料请联系QQ: 50766489.
数据项最小单位

数据元素数据基本单位

数据是信息载体

数据按逻辑结构划分一:
1.线性结构
线性表、栈、队列、串。
2.非线性结构
数组、广义表、树、图。
*数据按逻辑结构划分二:
1.集合结构
2.线性结构
3.树结构
4.图结构
什么是数据结构?
数据结构就是数据之间的相互关系。
数据结构的包括内容
1.逻辑结构
指数据元素之间的逻辑关系,是从逻辑关系上描述算法,跟存储无关,独立于计算机。
2.存储结构
概念:数据元素及其关系在计算机的表示。
存储结构=逻辑结构+计算机语言
(1)顺序存储
用数组
(2)链接存储
用指针
(3)索引存储
(4)散列存储
3.运算
对数据施加的操作(插入、删除、排序…)
算法:是对数据运算的描述
算法+数据结构=程序
算法特性:
1.一个或多个输入
2.至少一个输出
3.确定性
4.可行性
5.有穷性
算法规模:
算法求解问题的输入量
时间复杂度
空间复杂度
第二章线性表
一、数据结构之顺序表
顺序表笔记
顺序表优缺点
优点:
1.存储密度大(结点本身存储量/结点结构所占存储量)
2.可以随机存取
缺点:
1.在插入、删除元素困难
2.浪费存储空间
3.属于静态存储元素个数不能自由扩充
注意
1.无头结点
*考点
1.既然顺序表是随机存取,他取第i个时间跟i无关。
定义
#define NodeSize 100//100个大小
typedef struct Lnode* link;
typedef struct Lnode//顺序表一个结点
{
int *data;//指针即数组
int length;//指针域
//栈中使用多了一个int top;
}LNode;
操作
(1)初始化
void init(link head)//初始化
{
head->data=(link)malloc((sizeof(LNode))*Nodesize);//强制转换成指针类型并赋值给data数组
if(head->data==NULL)
{
printf("申请空间失败\n");
}else
{
printf("申请空间成功\n");
}
head->length=0;
}
(2)销毁
void Distory(link head)
{
if(head->data)//如果表存在
{
free(head->data);
}
}
(3)清空
void clear(link head)
{
head->length=0;
}
(4)判断是否为空
void empty(link head)
{
if(head->length==0)
{
printf("该表为空");
}
}
(5)求表长
int len(link head)
{
int n;//不包括头结点
n=head->length;
printf("%d",n);
return n;
}
(3)取第i个位置的结点元素
int get(link head,int i)
{
if(i<1||i>head->length)
{
printf("容错保护");
}else
{
printf("位置为 %d 的为%d",i,head->data[i]);
return head->data[i];
}
}
(4)获取值为x的位置
int located(link head,int x)
{
int i;
for(i=0;i<head->length,i++)
{
if(head->data[i]==x)
{
printf("数值为 %d 的位置为 %d",x,i);
return i;
}
}
return printf("没找到");
}
(5)插入

*插入最后和插入中间
先后挪,再赋值
*插入前面
直接插入
void insert(link head,int i,int e)//i是位置不是下标
{
int j;
if((i<1||i>head->length+1)||head->length==NodeSize)//注意这里的i不是下标
{
printf("容错保护");
}
else{
for(j=head->length-1;j>i-1;j--)//由于是从最后一个开始挪
{
head->data[j+1]=head->data[j];
}
head->data[i-1]=e;
(head->length)++;
}
}
(4)删除

*删除最前和删除中间
先前挪,再删除
*删除后面
直接删除
void detele(link head,int i)
{
int j;
if(i<1||i>head->length)
{
printf("容错保护");
}
for(j=i;j<head->length;j++)
{
head->data[j-1]=head->data[j];
}
(head->length)++;
}
主函数
void main()
{
link head;
init(&head);
insert(&head,1,1);
Delete(&head,1);
len(&head);
}
二、数据结构之单链表
单链表笔记
注意:
1.什么是线性表?
结点只有一个指针域的链表叫线性表,同理有两个指针域叫双链表。首尾相接的链表叫循环链表。
2 头结点的好处?
1.便于【头结点后的第一个元素结点(首元结点)】的处理。
这样对链表好操作,如果没有头结点插入删除都要考虑是否是插入到链表的 头部。
这就是为什么链栈没有头结点的原因,因为栈都在栈顶插入删除。
2.便于空表非空表的处理。
3.头指针和头结点与首元结点
头指针: 表名即头指针名,link head;
头结点: 数据域一般不带数据,便于首元结点的操作
首元结点:非头结点的第一个元素的结点
eg:
ink head;//头指针
head=(link)malloc(sizeof(Node));//头结点
head->next=NULL;//首元结点为空
头指针与头结点(头结点可以没有,头指针不能,没有头指针就没有了整个表。)
操作
定义
typedef struct Lode *link
typedef struct Lnode{
int data;//数据
link *next;
}LNode;
初始化
void init(link head)
{
head=(link)malloc(sizeof(LNode));
if(head==NULL)
{
printf("申请空间失败");
}
head->next=NULL;
}
遍历
void print(link k)
{
while(k->next!=NULL)
{
k=k->next;
printf("%d\n",k->data);
}
}
判断是否为空
void empty(link head)
{
if(head->next==NULL)
{
printf("该表为空");
}
}
销毁操作
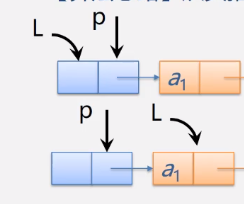
void Destory(link head)
{
//相当于灵魂脱壳还改了名
//有没有发现p指向head,head指向head->next,以此循环
//销毁后没有头指针,没有头结点,没有首元结点
link p;//指针p作为载体
while(head)
{
p=head;
head=head->next;//head结点指向下一个结点
free(p);
}
}
清空操作
void cleer(link head)
{
//头指针,头结点还在
link p;//删除首个的载体
link q;//删除下一个结点的载体
while(head->next)
{
//从首元结点开始清空,头结点的指针域储存着首元结点地址
p=head->next;
q=p->next;
free(p);
}
head->next=NULL;
}
求长
int len(link head)
{
int n;
n=0;
while(head->next )
{
n++;
head->next=head->next->next;
}
printf("表长 %d",n);
return n;
}
**获取第i个元素 **
link get(link head,int i)
{
link Head;
int j;
j=1;//指向了首元结点head->next
Head=head->next;//Head是头结点head指向的首元结点
while(Head&&j<i)
{
Head=Head->next;
++j;
}
if(!Head||j>i)
{
printf("容错保护");
}
return Head->data;
}
**按值查找 **
link look(link head,int n)
{
link Head;
Head=head->next;//Head是头结点head指向的首元结点
while(Head&&Head->data!=e)
{
Head=Head->next;
}
return head;
}
插入
//关键代码
void inverst(link head,int i,int e)
{
j=0;
while(head&&j<i-1)//寻找i-1的位置作为头指针开始插入
{
head=head->next;
++j;
}
link s;//1.新结点s
s=(link)malloc(sizeof(Node));
s->data=e;
//新结点插入其中
s->next=head->next;//新结点s指向头结点的下一个
head->next=s;//顺序不能乱因为顺序对换此时对象会变动
}
删除
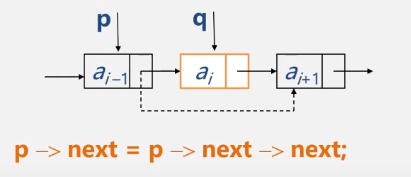
//删除
void Delete(link head,int i)//从头结点开始删
{
link tool;
link Head;
int j=0;
Head=head->next;
while(Head&&j<i-1)//除头结点所以-1.查找i-1位置作为头结点开始删除
{
j++;
head=Head;
}
tool=Head;//把原本指向的那个结点赋值给deletedata
Head=tool->next;//这里的L->next不是原本指向的那个原结点,而是指向新结点即(deletedata的原来指向的那个结点的下一个结点)
free(tool);
}
头插法(逆序)

//头插法
link CreateList_H(link head,int n)
//逆位序输入n个元素的值,建立带表头结点的单链线性表L。
{
int i;
//先建立一个带头结点的单链表
for (i=0;i<n;i++)
{
//指针为P
link p;
//生成新结点
p= (link)malloc(sizeof(Node));
printf("请输入该位置的数值\n");
scanf("%d",&(p->data));
//插入到表头
p->next=head->next;//p的指针域指向头结点指针域指向的首元结点
head->next=p; //头结点head指向p
}
}
尾插法(正序)

//尾插法
link CreateList_T(link L,int n)
//顺位序输入n个元素的值,建立带表头结点的单链线性表L。
{
int i;
//先建立一个带头结点的单链表
for (i=0;i<n;i++)
{
link p;
p= NewNode();
printf("请输入该位置的数值\n");
scanf("%d",&(p->data));
L->next=p;//插入到头结点后就是说此时的head的指针域不为空而是指向P
L=p;//这里的作用就是下一次循环的L是指这次的结点P,那么下次的下次的L就是指下次的P1,同...。
}
return L;
}
主函数
来源 代码片.
void main()
{
//初始化
link head;//定义一个头指针叫head
head=(link)malloc(sizeof(Node));//创建一个头指针head指向的头结点
head->next=NULL;
//操作
CreateList_T(head,3);
//CreateList_H(head,3);
Delete(head,2);//下标为2
print(head);//把头指针传进区遍历打印
}
---------------------------------------单循环链表
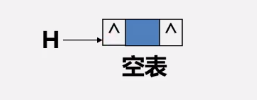
注意:
单链表的尾结点是空
循环链表中尾结点是指向头结点,所以空表就是指向自己
优点:
从表中的任一节点出发都可以找到表中其他节点
(次)头指针型单循环链表
找最后一个不方便
(主)尾指针型单循环链表
找最后一个和最前面一个方便
操作
两个尾结点的单循环链表合并

1.先把存在表尾的头结点Ta存在P中
P=Ta->next;
2.把Tb首元结点接在Ta表尾
Ta->next=Tb->next->next;
3.释放Tb表头结点
free(Tb);
4.修改表尾指向P
Tb->next=P;
link union(link Ta,link Tb)
{
P=Ta->next;
Ta->next=Tb->next->next;
free(Tb);
Tb->next=P;
return Tb;//合并后返回尾指针Tb
}
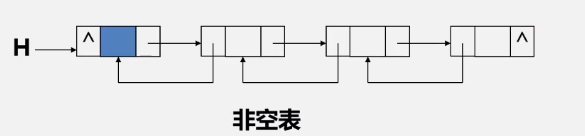
---------------------------------------双链表
1、单链表(一个指针域)

找前驱结点难
2、双链表(两个指针域)

找前驱结点简单
双向链表
---------------------------------------双循环链表

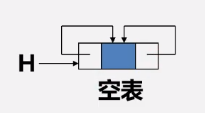
操作
定义
typedef struct doublelink *link;
typedef struct doublelink{
int data;
link prior;
link next;
}Doublelink;
查找
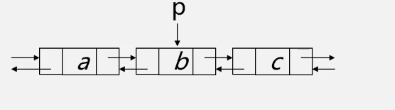
通过前驱查找:
p->prior->next=p;
通过后继查找
p=p->next->prior;
计算长度(用一条链即可)
1.用前驱
2.用后继
3.用单链
插入

步骤与之前相同
1.找到对应位置等待插入get函数
2.生成新结点s
1.开辟空间
2.赋值
3.连接
图中四步
void insert(link head,int i,int e)
{
int j;
j=0;
head=(link)malloc(sizeof(Doublelink));
Head=head->next;
while(Head&j<i-i)//1
{
j++;
Head=Head->next;
}
link s;
s=(link)malloc(sizeof(Doublelink));//2
s->data=e;
s->prior=p->prior;
p->prior->next=s;
s->next=p;
p->prior=s;
}
删除

步骤
删除用两步即可把P结点前后连起来
void Deletelink(link head,int i,int e)
{
int j;
j=0;
head=(link)malloc(sizeof(Doublelink));
Head=head->next;
while(Head&j<i-i)//1
{
j++;
Head=Head->next;
}
link s;
s=(link)malloc(sizeof(Doublelink));//2
s->data=e;
p->prior->next=p->next;
p->next->prior=p->prior;
}
各链表时间复杂度


顺序表VS链表
链表:
优点
----结点空间动态申请和释放,顺序表会出现闲置或者溢出
----插入删除不需要移动数据元素o(1)
----随机存储o(1).
缺点
----存储密度小,顺序存储密度大为100%

----插入删除不需要移动数据元素
-----------------------线性表的应用
一、线性表合并
方法:判断Lb中的第一个元素La有没有,没有就插入La,反之则不插入

void union(link La,link Lb)
{
A_len=len(&La);
B_len=len(&Lb);
for(int i=1;i<B_len;i++)//将B表中的元素依次插入A表
{
int e;
e=get(&Lb,i);//返回Lb的值
if(!look(&La,e))//在A表中查找元素,若无就插入,反之则否
{
insert(&La,A_len++,e);//插入到A表+1位置,把B中元素值插入
}
}
}
二、有序表的合并

方法
1.创建空表Lc
2.比较L和Lb哪个小就插入到Lc表的最后
3.继续La或者Lb其中一个表的剩余结点插入到Lc表的最后
顺序表的实现

void union_sq(link La,link Lb,link Lc)
{
A=La.data;
B=Lb.data;//指针LB指向Lb第一个元素
Lc.length=La.length+Lb.length;
Lc.data=(link)malloc(sizeof(Node)*MAXSIZE);//为合并后的表分配空间
C=Lc.data;//指针Lc指向新表Lc第一个元素
A_last=La.data+La.length-1;//A_last指向LA表的最后一个元素
B_last=Lb.data+Lb.length-1;
while(A<A_last&&B<B_last)//都非空
{
if(*A<=*B)//摘取两个表较小的结点
{
*C++=*A++;
}
else
{
*C++=*B++;
}
}
while(A<A_last)//LB已经到达表尾,LA剩下元素加入Lc
{
*C++=*A++;
}
while(B<B_last)//LA已经到达表尾,LB剩下元素加入Lc
{
*C++=*B++;
}
}
链表表的实现
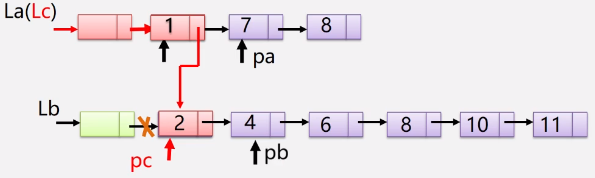
void MergeList_L(LinkList &La,LinkList &Lb,LinkList &Lc)
{
pa=La->next;
pb=Lb->next;
pc=Lc=La;//用La的头结点作为Lc的头结点
while(pa&&pb)//pa和pb都不为空
{
if(pa-> data< =pb->data)//pa小,pa为当前结点.
{
pc->next=pa;
pc=pa;
pa= pa-> next;
}
else
{
pc->next=pb;
pc=pb;
pb=pb-> next;
}
}
pc->next=pa?pa:pb; //当有其中一个指针为空,就将插入剩余段
free(Lb);
//释放Lb的头结点
}
一元多项式的运算
实现两个多项式的加、减、乘运算。
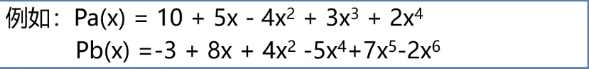
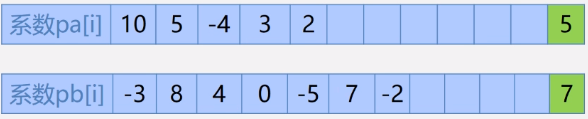

稀疏多项式的运算

就是说上一节中的多项式跟下标有关,而稀疏的话,如果直接存到数组,,如上图的A(x),就会出现第二项直到第七项都是0…这就很浪费空间了,此时就应该先把每一项提取出来。
方案一数组

补充
如果指数相加为0,直接抵消比加入到数组C
存储空间分配不灵活
运算的空间复杂度高
方案二链表





图书管理系统


第三章
栈和队列
线性表的儿子们
栈

队列
第五章树
树

树是n个结点的有限集
0个结点叫空树

每个子树又是一个树(跟递归有关)
树的表示
(1)嵌套集合
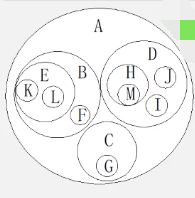
(2)广义表

(3)凹入表示
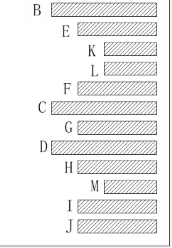
术语
1.结点

2.根结点(看有无前驱)
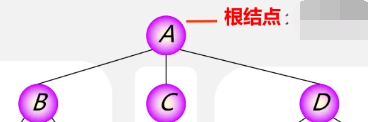
3.结点的度(看线数)
0度的结点即无后继叫叶子(外部节点),终端结点。
不是0度则称非终端结点,分支结点。
4.树的度(结点度的最大值)
5.树的深度(高度):树中结点的最大层次
6.内部节点
就是除了根结点和0度的叶子结点
关系
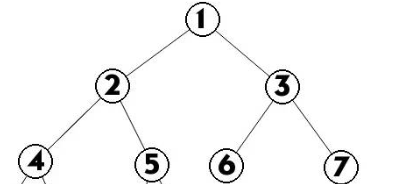
双亲是1
孩子是1或者2
共同的双亲
兄弟结点是1和2
共同的双亲
堂兄弟结点是4和6,孩子之间的关系
祖先和祖孙,4和6与1的关系
有序树

有序树:子树位置改变都是这棵树也改变
无序树:无论子树在什么位置都是这棵树
森林
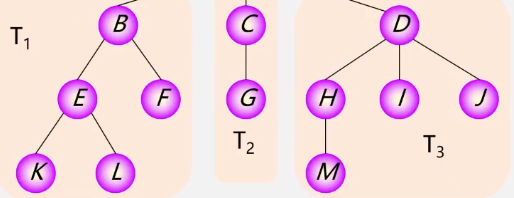
m>=0棵互不相交的树的集合
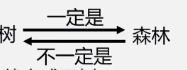
1棵是特殊的森林
若给森林(除特殊森林)加双亲结点就成了树
二叉树
概念:
每个结点只有两个叉的树由(0个)即空集或者一个根结点及两棵互不相交的
为什么学二叉树?
普通树叫多叉树,难运算,转二叉树运算便于实现。
特点:
1、每个结点最多两个孩子(二胎政策)
2、子树有左右之分,次序不能颠倒。
3、二叉树可以是空集,根可以有空的左子树或空的右子树
注:
二叉树:
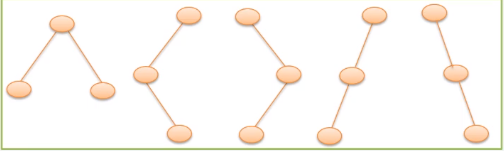
(3结点二叉树5形态)
二叉树不是树的特殊情况,是两个概念
二叉树要区分左子树和右子树,即使只有一棵子树也要区分他是左子树还是右子树。
树:
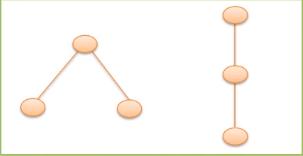
(3结点树2形态)
而树中,当树结点只有一个孩子的时候,就无需区分左右次序,两者不同,这就是树和二叉树的最主要的区别。
二叉树的基本形态

树的应用案例
1.数据压缩问题
将数据文件转成0和1的二进制串称为编码
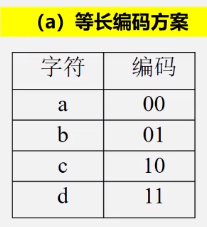
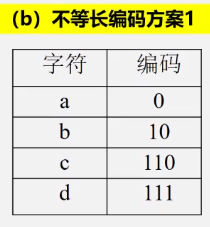
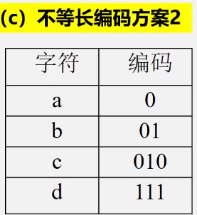
2.利用二叉树求解表达式的值
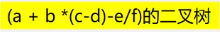
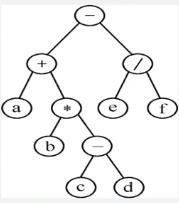
从后往前算

性质1:
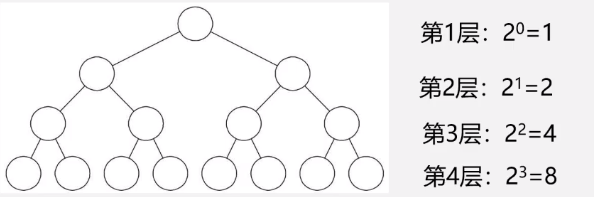
注
第i层至少一个结点。
性质2:


由性质1推导性质2:
注
K层至少K个结点

性质3

叶子数即无后继的0度结点:6个
度为2的结点:5个
n0=n2+1;
从下往上
总边数=(有前驱)总结点个数-根结点无前驱即无边数
n是结点个数
n0是0度结点数
n1是1度结点数
n2是2度结点数
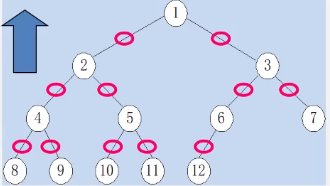
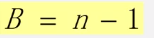
从上往下看
每个0度结点0条边
每个1度结点1条边
每个2两结点2条边
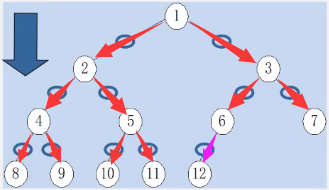
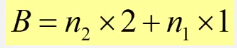
(1)
B总=B上+B下->总结点数n
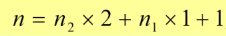
总结点数不就是
(2)
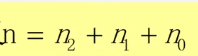
由(1)-(2)证得,由边边证明结点关系。
总结二叉树性质3:
n0-n2=1。
研究二叉树两种特殊形式是为什么?
因为他们在顺序存储方式下可以复原
满二叉树
概念:
性质二中,当深度为K最大可以有2^k个结点我们叫满二叉树
特点:
1.每一层结点树都是最大结点数(结合性质一每层都是满的)
2.叶子结点全部在最底层
编号规则
自上而下,自左向右,每个结点都有元素

判断是否满二叉树?
满足2^k-1
同深度的二叉树结点个数最多
同深度的二叉树的叶子结点个数(最底层)最多
完全二叉树
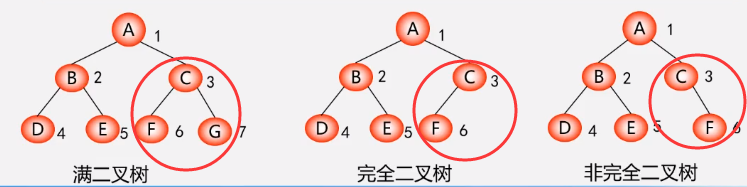
位置要对应,在满二叉树中最后一个结点开始,连续去掉任意的结点那么:

存储结构
顺序存储
------------------------------------------------------
编号方式

为了可以恢复,或者说不改变数的形态在下图中特殊的编号规则是,空的结点标出,依然按满二叉树的规则进行编号。


------------------------------------------------------
二叉树的顺序存储缺点
空间不能动态分配,一些叶子结点占用空间
如下图即为浪费空间
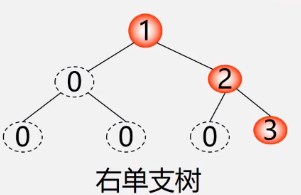
(左单支树同理)
#define MAXSIZE 100
Typedef int Sqbtree[MAXSIZE];//Sqbtree二叉树
Sqbree sbtree;//数组更名
链式存储
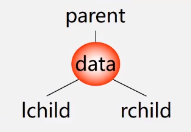

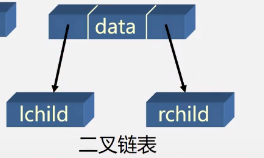

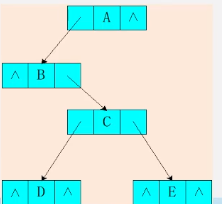
逻辑结构(a)
存储结构(b)
typedef struct BNode *blink;
typedef struct bnode{
int data;
link lchild;
link rchild;
}Bnode;
二叉链表
三叉链表
操作:
遍历化
要求
每个结点访问一次且仅 访问一次
结果
产生一个关于结点的线性序列

加一种按层遍历的方法,一共七种
1、先序(前缀表达式)


按照根左右的方法
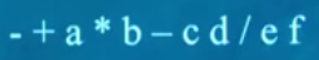
算法:递归

根据算法写程序

2、中序(中缀表达式)


按左根右
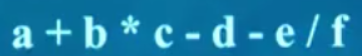
算法:递归

3、后序(后缀表达式)

按左右根

举个例子他程序的流程
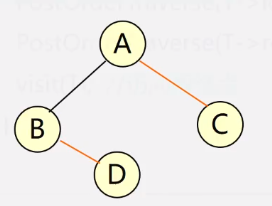

算法:递归

来个大合照

例题
根据先序和(必须)中序可以恢复二叉 树
综上:必须要有中序和(前或后序其一)才可恢复






有没有非递归算法实现?
以中序为例


层次遍历




应用
以先序建树
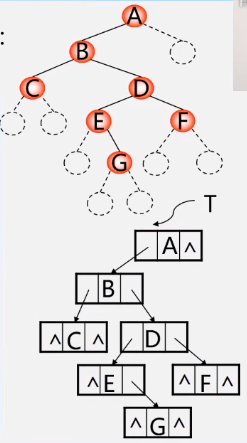

复制

计算二叉树的深度


计算结点总数


计算叶子结点树


线索化
线索化的由来








练习


树和森林的结构


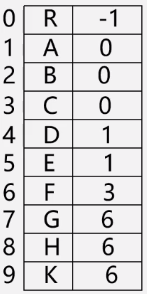

#define MAX 100
//结点
typedef struct PTNode{
int data;
int parent;
}PTNode;
//树
typedef struct {
PTNode node[MAX];
int parent;
int r,n;
}PTree;
可以多一个成员存双亲解决这个问题

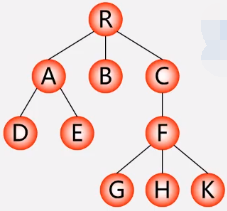










利用树之间关系发现规律转化成二叉树,其中一端存孩子结点,一端存兄弟结点。



















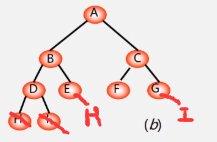
其实没这么复杂,不用分3部分,如果先序那就把第一棵树看做根,在根左右算出来。



本来应该没有中序的可能转化成为二叉树


操作次数很明显,所以哈夫曼解决的问题





eg:
(a)是二叉树,(b)是完全二叉树
eg:
与(b)路径长度一致却不是完全二叉树





根到结点路径乘以权(值)
比较相同度才有意义

















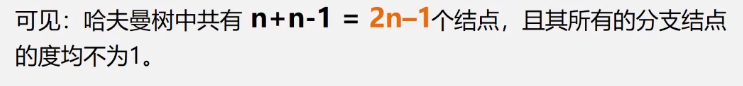
缺点:占用空间
缺点:编译回去的时候,不能准确的重码。
当重码时:
比如T不是;的父类。
这种时从根开始,算法不好实现


























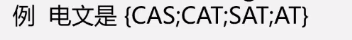








所以从表中从后往前找,再倒过来
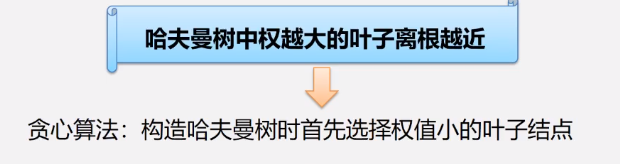
最优化
转换化
第六章
堆之优先队列
第七章
查找之散列表
第 章
并查集

点击回到原文 ↩︎
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









