






最近在调试HPM6750的项目时,考虑到调试方便需要将一些中间数据上传至PC分析,而且数据量又比较大,准备使用UDP分包发送,在调试的时候发现如下几个问题:
- sdk提供的lwip例程在使用时,分包会出现后一包的数据覆盖前一包数据的情况;
- 分包后,UDP首部校验和错误;
- sdk将lwip内存堆初始化到DLM,实际使用中需要将其更改;
以上三个问题在此文章中都已得到解决,本文将在下面依次对以上三个问题进行分析,并提出与验证解决方法。
一、分包数据覆盖问题
在lwip中使用UDP分包功能前,需要将lwipopts.h中的宏定义 P_REASSEMBLY 与 IP_FRAG 打开,并且根据实际发送数据量配置内存堆的大小。
在配置完成后使用udp发送一3001字节的数据至计算机时,在计算机上通过网络抓包软件(wireshark)抓包结果如下。
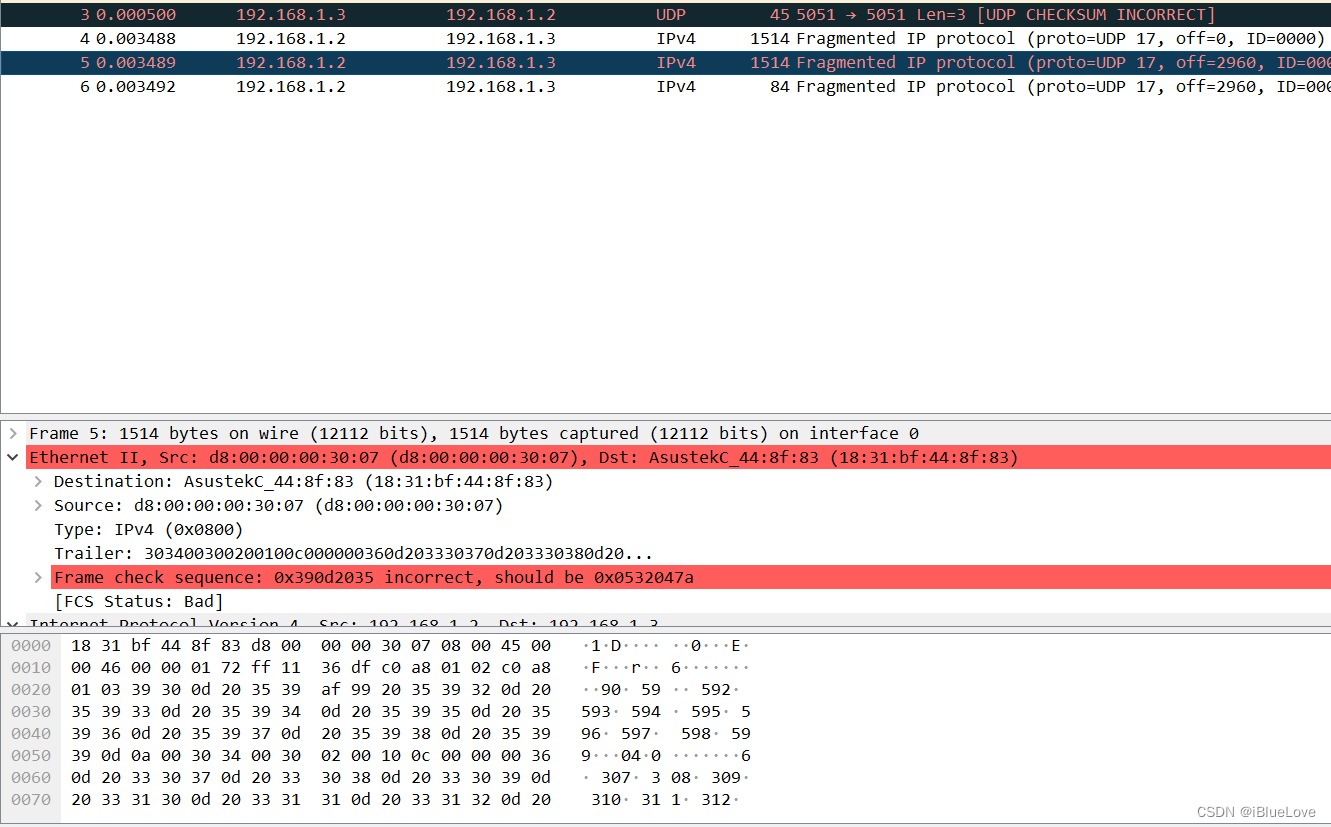
发送数据为0000~0599,图下方显示的是分包的第二包,也就是offset应该等于1480(MTU - IP_Header)才对,而抓到的却是2960的偏置,并且查看数据区发现第二包前一部分数据应该是290至300之间,如上图所示,第二包前一部分数据明显是第三包的。此处忽略数据的第7、8字节的错误,这是我们第二个问题需要解决的。
1.1 分析
初步猜测应该是第三包的IP头与有效数据区将第二包的IP头与有效数据区的前部分覆盖掉了,由于以太网是使用的dma传输的,我们合理怀疑如果每一包存储的内存区域都是相同的,那么有可能第二包dma开始传输之前第三包就已经写入到此缓冲区将第二包的部分数据覆盖掉。
可是从手册上看出HPM6750的以太网dma是链式传输的,与STM32的传输描述符基本一致,而且lwip例程开始就是以二维数组的方式初始化的传输数据的缓冲区,并且以环形单链表的形式将链式描述符连接起来。似乎不太可能是使用同一内存区域的情况。
那么去寻找udp_sendto()接口的分包实现,经过一番包装,在ip_frag.h中ip4_frag()函数中进行IP分包。主要部分如下,具体是将我们内存堆实现的pbuf分片拷贝,添加IP头,将每包数据依次送进下级输出接口,可以看出ip_frag()分包完的数据包是使用同一内存区域实现的(rambuf申请、释放、再申请(pbuf_alloc)到的是与前一次申请相同的一片内存区域)。
err_t
ip4_frag(struct pbuf *p, struct netif *netif, const ip4_addr_t *dest)
{
.......
left = (u16_t)(p->tot_len - IP_HLEN);
while (left) {
/* Fill this fragment */
fragsize = LWIP_MIN(left, (u16_t)(nfb * 8));
rambuf = pbuf_alloc(PBUF_IP, fragsize, PBUF_RAM);
if (rambuf == NULL) {
goto memerr;
}
LWIP_ASSERT("this needs a pbuf in one piece!",
(rambuf->len == rambuf->tot_len) && (rambuf->next == NULL));
poff += pbuf_copy_partial(p, rambuf->payload, fragsize, poff);
/* make room for the IP header */
if (pbuf_add_header(rambuf, IP_HLEN)) {
pbuf_free(rambuf);
goto memerr;
}
/* fill in the IP header */
SMEMCPY(rambuf->payload, original_iphdr, IP_HLEN);
iphdr = (struct ip_hdr *)rambuf->payload;
/* No need for separate header pbuf - we allowed room for it in rambuf
* when allocated.
*/
netif->output(netif, rambuf, dest);
IPFRAG_STATS_INC(ip_frag.xmit);
/* Unfortunately we can't reuse rambuf - the hardware may still be
* using the buffer. Instead we free it (and the ensuing chain) and
* recreate it next time round the loop. If we're lucky the hardware
* will have already sent the packet, the free will really free, and
* there will be zero memory penalty.
*/
pbuf_free(rambuf);
left = (u16_t)(left - fragsize);
ofo = (u16_t)(ofo + nfb);
}
MIB2_STATS_INC(mib2.ipfragoks);
return ERR_OK;
memerr:
MIB2_STATS_INC(mib2.ipfragfails);
return ERR_MEM;
}
在这段代码中有一段lwip作者提醒开发者的话:看起来不幸却是发生了,当然需要继续向下看才能确定
/* Unfortunately we can't reuse rambuf - the hardware may still be
* using the buffer. Instead we free it (and the ensuing chain) and
* recreate it next time round the loop. If we're lucky the hardware
* will have already sent the packet, the free will really free, and
* there will be zero memory penalty.
* /
OK,lwip的分包函数既然一个包一个包的往底层送,那lwip的底层输出应该依次将每个包依次拷贝到初始化的描述符指向的各自缓冲区里了吧(初始化描述符指向的各自缓冲区位置:在hpm_enet_drv.c中enet_dma_tx_desc_chain_init())。
接着我们去查看lwip的底层输出 low_level_output() 的实现,如下所示为基本结构,因为上面是一包一包的传下来的,因此for循环只执行一遍(for是给内存池分配的pbuf使用),while的判断条件不满足,跳过while(),将pbuf中payload存放的数据地址,赋值给发送描述符中存放发送缓冲区地址的位置,然后执行发送。
for (q = p; q != NULL; q = q->next) {
........
/* Check if the length of data to copy is bigger than Tx buffer size*/
while ((bytes_left_to_copy + buffer_offset) > ENET_TX_BUFF_SIZE) {
.......
}
// 直接将pbuf的payload地址,赋值给发送描述符中存放发送缓冲区地址的位置
desc.tx_desc_list_cur -> tdes2_bm.buffer1 = core_local_mem_to_sys_address(BOARD_RUNNING_CORE, (uint32_t)q -> payload);
.......
}
// 在此函数里进行链式描述符指针指向下一描述符
enet_prepare_tx_desc(ENET, &desc.tx_desc_list_cur, &desc.tx_control_config, frame_length, desc.tx_buff_cfg.size);
到这里就容易看出来了,low_level_output() 并未将pbuf的数据部分拷贝到发送缓冲区数组内,而是直接操作指针指向pbuf的数据部分,发送时从pbuf的数据部分直接取值,这就容易引起DMA发送与写缓存不同步的问题。这种写法使得sdk建立的输出缓冲数组失去作用,链式描述符也没有起到应该有的作用。
表述能力有限:上述拷贝pbuf的数据与直接操作pbuf的数据两种方法,在B站正点原子讲lwip的视频中有比较清楚的讲解。
经过调试,到此可以得到分析结果:
由于分包函数各包之间共用同一内存空间,并且底层发射函数直接操作传下来的pbuf的数据部分,导致写缓存与DMA发送不同步,第二包dma开始传输之前第三包就已经写入此缓冲区,将第二包的部分数据覆盖掉了,出现此种情况。
实际这种写法根本没有缓存一说。就是“硬写”。
对此可以做个小实验再次确认,在low_level_output() 里加100us的延时,等待DMA传输完成,经作者实验这样输出已经没有包间数据交叠现象。
1.2 解决
经过以上分析可以看出,由于分包情况下并未用到缓存机制,我们可以分别在ip4_frag()与low_level_output() 解决此问题。比如:
1. 在ip_frag()将pbuf拆包,分别分配空间,链接起来后,以链式向下传;
2. 在ip_frag()为不同包分配不同内存空间,仍然单包向下传;
3. 修改 low_level_output() ,利用链式dma传输的功能,将每包依次拷贝到传输缓冲区。
作者在这里选择方法2,最简单粗暴的开一片最大的空间的方法。如下:(LWIP_NETIF_TX_SINGLE_PBUF 预编译分支作者并未测试,因为这是分成的并不是IP包,直接是链路层的包)
err_t
ip4_frag(struct pbuf *p, struct netif *netif, const ip4_addr_t *dest)
{
struct ip_hdr *original_iphdr;
struct ip_hdr *iphdr;
const u16_t nfb = (u16_t)((netif->mtu - IP_HLEN) / 8);
u16_t left, fragsize;
u16_t ofo;
int last;
u16_t poff = IP_HLEN;
u16_t tmp;
int mf_set;
original_iphdr = (struct ip_hdr *)p->payload;
iphdr = original_iphdr;
if (IPH_HL_BYTES(iphdr) != IP_HLEN) {
/* ip4_frag() does not support IP options */
return ERR_VAL;
}
LWIP_ERROR("ip4_frag(): pbuf too short", p->len >= IP_HLEN, return ERR_VAL);
/* Save original offset */
tmp = lwip_ntohs(IPH_OFFSET(iphdr));
ofo = tmp & IP_OFFMASK;
/* already fragmented? if so, the last fragment we create must have MF, too */
mf_set = tmp & IP_MF;
left = (u16_t)(p->tot_len - IP_HLEN);
struct pbuf *rambuf[45];
u16_t i = 0;
// test
while (left) {
/* Fill this fragment */
fragsize = LWIP_MIN(left, (u16_t)(nfb * 8));
#if LWIP_NETIF_TX_SINGLE_PBUF
rambuf[i] = pbuf_alloc(PBUF_IP, fragsize, PBUF_RAM);
if (rambuf[i] == NULL) {
goto memerr;
}
LWIP_ASSERT("this needs a pbuf in one piece!",
(rambuf[i]->len == rambuf[i]->tot_len) && (rambuf[i]->next == NULL));
poff += pbuf_copy_partial(p, rambuf[i]->payload, fragsize, poff);
/* make room for the IP header */
if (pbuf_add_header(rambuf[i], IP_HLEN)) {
pbuf_free(rambuf[i]);
goto memerr;
}
/* fill in the IP header */
SMEMCPY(rambuf[i]->payload, original_iphdr, IP_HLEN);
iphdr = (struct ip_hdr *)rambuf[i]->payload;
#else /* LWIP_NETIF_TX_SINGLE_PBUF */
/* When not using a static buffer, create a chain of pbufs.
* The first will be a PBUF_RAM holding the link and IP header.
* The rest will be PBUF_REFs mirroring the pbuf chain to be fragged,
* but limited to the size of an mtu.
*/
rambuf[i] = pbuf_alloc(PBUF_LINK, IP_HLEN, PBUF_RAM);
if (rambuf[i] == NULL) {
goto memerr;
}
LWIP_ASSERT("this needs a pbuf in one piece!",
(rambuf[i]->len >= (IP_HLEN)));
SMEMCPY(rambuf[i]->payload, original_iphdr, IP_HLEN);
iphdr = (struct ip_hdr *)rambuf[i]->payload;
left_to_copy = fragsize;
while (left_to_copy) {
struct pbuf_custom_ref *pcr;
u16_t plen = (u16_t)(p->len - poff);
LWIP_ASSERT("p->len >= poff", p->len >= poff);
newpbuflen = LWIP_MIN(left_to_copy, plen);
/* Is this pbuf already empty? */
if (!newpbuflen) {
poff = 0;
p = p->next;
continue;
}
pcr = ip_frag_alloc_pbuf_custom_ref();
if (pcr == NULL) {
pbuf_free(rambuf[i]);
goto memerr;
}
/* Mirror this pbuf, although we might not need all of it. */
newpbuf = pbuf_alloced_custom(PBUF_RAW, newpbuflen, PBUF_REF, &pcr->pc,
(u8_t *)p->payload + poff, newpbuflen);
if (newpbuf == NULL) {
ip_frag_free_pbuf_custom_ref(pcr);
pbuf_free(rambuf[i]);
goto memerr;
}
pbuf_ref(p);
pcr->original = p;
pcr->pc.custom_free_function = ipfrag_free_pbuf_custom;
/* Add it to end of rambuf's chain, but using pbuf_cat, not pbuf_chain
* so that it is removed when pbuf_dechain is later called on rambuf.
*/
pbuf_cat(rambuf[i], newpbuf);
left_to_copy = (u16_t)(left_to_copy - newpbuflen);
if (left_to_copy) {
poff = 0;
p = p->next;
}
}
poff = (u16_t)(poff + newpbuflen);
#endif /* LWIP_NETIF_TX_SINGLE_PBUF */
/* Correct header */
last = (left <= netif->mtu - IP_HLEN);
/* Set new offset and MF flag */
tmp = (IP_OFFMASK & (ofo));
if (!last || mf_set) {
/* the last fragment has MF set if the input frame had it */
tmp = tmp | IP_MF;
}
IPH_OFFSET_SET(iphdr, lwip_htons(tmp));
IPH_LEN_SET(iphdr, lwip_htons((u16_t)(fragsize + IP_HLEN)));
IPH_CHKSUM_SET(iphdr, 0);
#if CHECKSUM_GEN_IP
IF__NETIF_CHECKSUM_ENABLED(netif, NETIF_CHECKSUM_GEN_IP) {
IPH_CHKSUM_SET(iphdr, inet_chksum(iphdr, IP_HLEN));
}
#endif /* CHECKSUM_GEN_IP */
/* No need for separate header pbuf - we allowed room for it in rambuf
* when allocated.
*/
netif->output(netif, rambuf[i], dest);
IPFRAG_STATS_INC(ip_frag.xmit);
//pbuf_free(rambuf[i]);
i++;
left = (u16_t)(left - fragsize);
ofo = (u16_t)(ofo + nfb);
}
for(u16_t j = 0; j < i; j++){
pbuf_free(rambuf[j]);
}
MIB2_STATS_INC(mib2.ipfragoks);
return ERR_OK;
memerr:
MIB2_STATS_INC(mib2.ipfragfails);
return ERR_MEM;
}
在上面代码中结构体数组开45个是因为要保证能对UDP数据报的最大长度64kB进行分包。这里可以参考此博文:https://zhuanlan.zhihu.com/p/468439711。
显然此简单粗暴的方法会导致空间浪费,在发送数据容量s小于64kB时, lwipopts.h中 MEM_SIZE 应大于2*s,发送数据量大于64kB的时候,MEM_SIZE应大于130k。
在工程中,当然并不是分包越多越好,详细可参考《计算机网络》或此博文:https://zhuanlan.zhihu.com/p/301276548
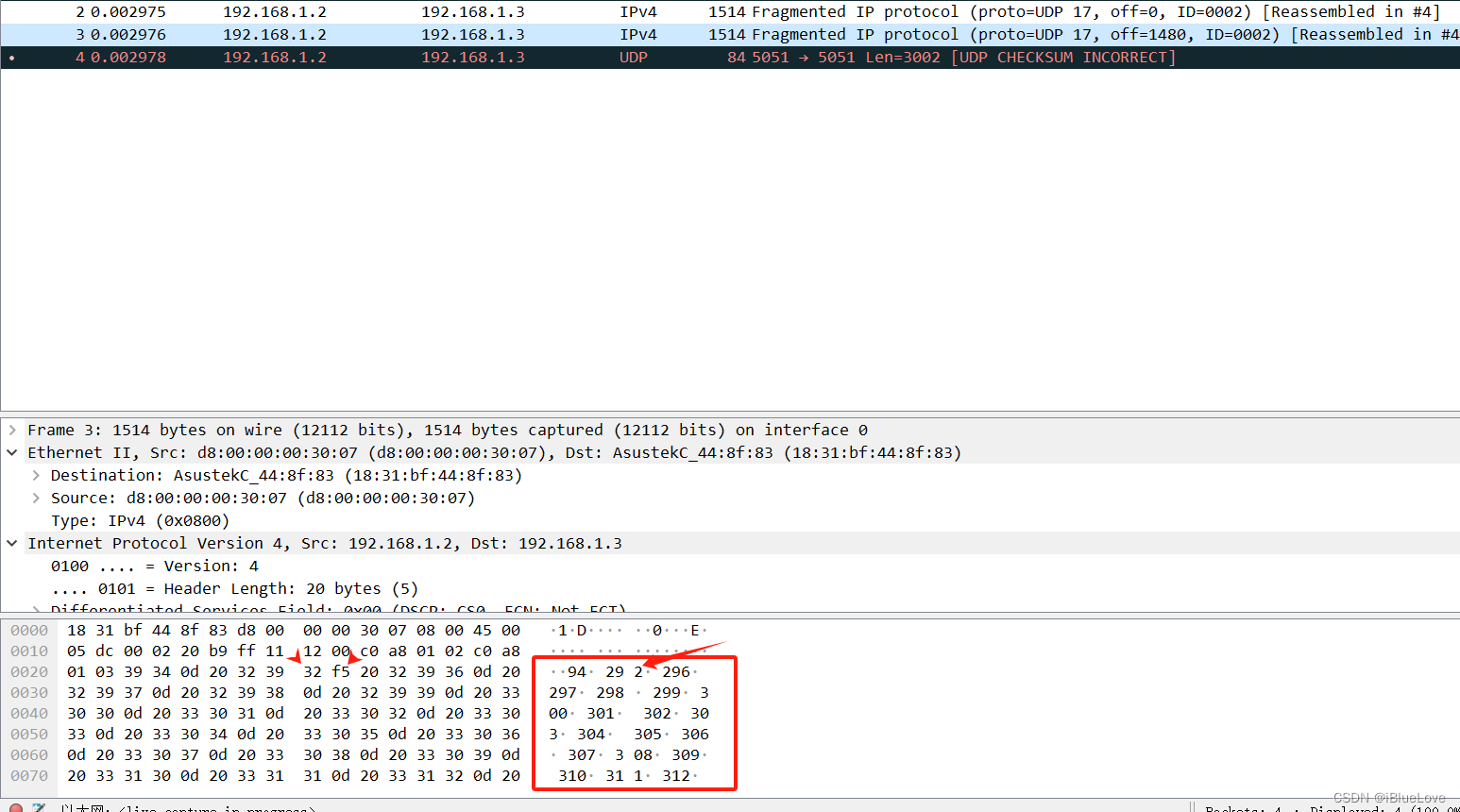
下图为按照以上叙述修改后抓包第二包的结果,可以看到数据交叠的现象已经消失,但是数据出错的问题仍然存在。
1.3 解决方法2 - 2024.04.08更新
使用方法3:修改 low_level_output() ,利用链式dma传输的功能,将每包依次拷贝到传输缓冲区。
更改如下:
memcpy((uint8_t *)((uint8_t *)desc.tx_desc_list_cur -> tdes2_bm.buffer1),(uint8_t *)((uint8_t *)q->payload), bytes_left_to_copy);
// desc.tx_desc_list_cur -> tdes2_bm.buffer1 = core_local_mem_to_sys_address(BOARD_RUNNING_CORE, (uint32_t)q -> payload);
以上方法2与方法3分别在两个地方实现了“缓冲”区的功能,实际测下来,方法2耗时更少(大概是方法3的70%)。
另外:分包个数多的时候,调整 ENET_TX_BUFF_COUNT 的大小大于分包个数,比如50。
二、UDP首部校验和错误问题
2.1 分析
经过抓包分析可以看出,经过分包后,数据出错的都是IP包的数据部分第7、8字节,而且开启wireshark的Validate the UDP checksum if possible功能后,发现分包出来的UDP包中UDP校验位也报错,如下图。这也导致在计算机用网络调试助手也是看不到数据上传,因为一旦校验错误,此包将被丢弃。

**根据以上提示可以看出应该是UDP的校验和计算被分配(offload:卸载)给硬件(MAC)计算了。
这不难理解,因为硬件计算是按照包来计算UDP校验和的,每包都计算UDP校验和然后添加到UDP首部的校验和位置,在IP包中正是第7、8字节。**
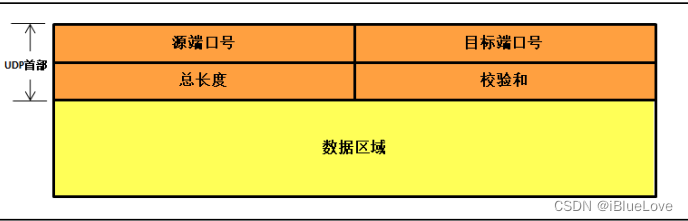
而IP包的IP头后无8字节的UDP首部,只有数据(1480字节),因此分包不能使用硬件计算UDP校验和,否则数据的前8字节会被硬件认为是UDP首部进而计算UDP校验和,覆盖掉数据,进而接收端产生校验错误。
具体UDP校验和与IP校验和计算过程可以查看lwip源码。
虽然UDP校验和不能使用硬件计算,但ip校验和仍然可以使用,不过IP校验和仅校验IP头,计算量小,而UDP则校验整个数据部分,使用软件计算会浪费一定的时间,不过经作者简单测量下来浪费时间较少,估计是因为校验和计算仅是求和取反的过程。具体还请自行测试,tradeoff。
2.2 解决
需要修改的地方有两个:
- lwipopts.h中将硬件计算校验和注释掉
//#define CHECKSUM_BY_HARDWARE 1
- 关闭发送描述符的CIC(checksum insertion control)
作者偷懒在sdk底层驱动 hpm_enet_drv.h 里修改了一下。代码如下。
#include "lwip/opt.h"
void enet_get_default_tx_control_config(ENET_Type *ptr, enet_tx_control_config_t *config)
{
config->enable_ioc = false;
config->disable_crc = true;
config->disable_pad = false;
config->enable_ttse = false;
config->enable_crcr = true;
#ifdef CHECKSUM_BY_HARDWARE
config->cic = enet_cic_ip_pseudoheader;
#else
config->cic = enet_cic_disable;
#endif
config->vlic = enet_vlic_disable;
config->saic = enet_saic_disable;
}
2024.04.08:本着尽量不要改动原厂驱动的原则,直接在 enet_init(ENET_Type *ptr) 做如下更改,注意声明:#include “lwip/opt.h”。
enet_get_default_tx_control_config(ENET, &enet_tx_control_config);
// 是否使用硬件(MAC)计算校验和,当报文需要分包时必须使用软件计算校验和
#ifndef CHECKSUM_BY_HARDWARE
enet_tx_control_config.cic = enet_cic_disable;
#endif
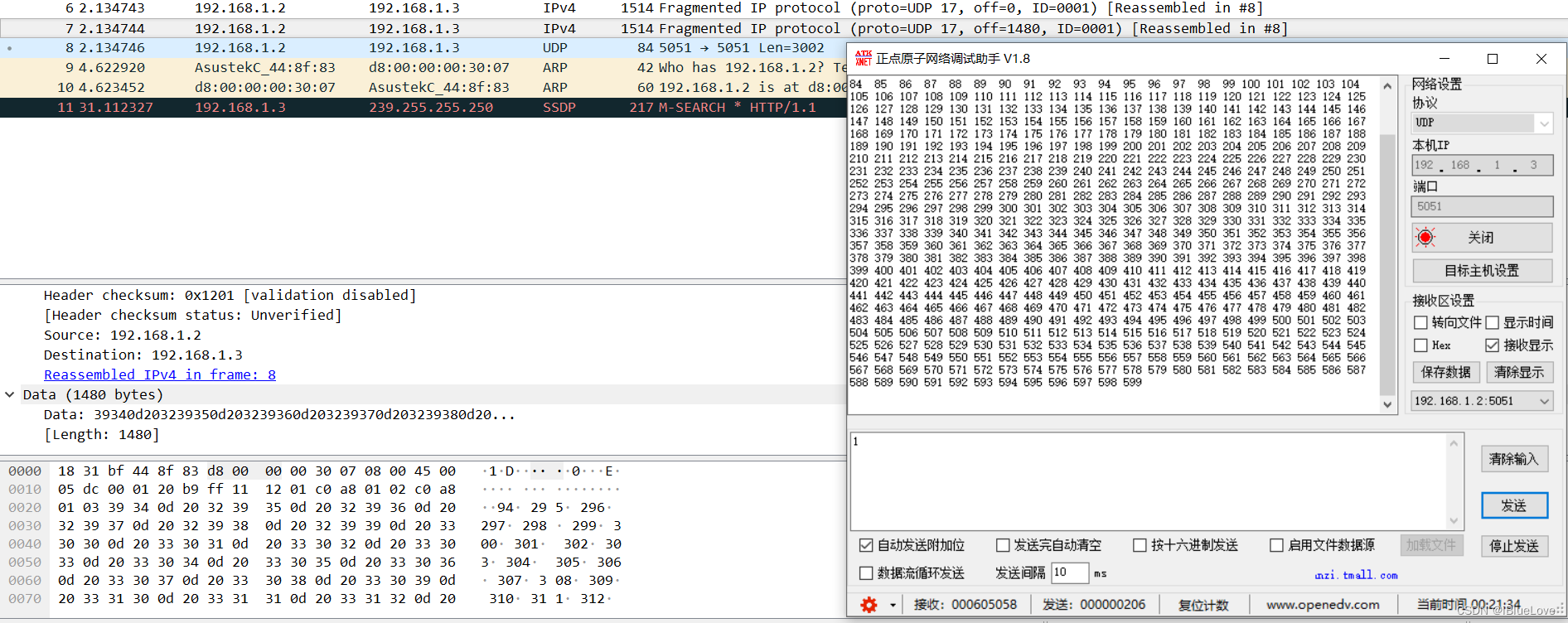
经修改后如下图,校验和正确,网络调试助手接收到数据。
三、内存堆初始化位置问题
在lwip中通常采用内存堆的方式分配pbuf的内存空间,在初始化lwip时会预先向单片机申请一块内存来实现pbuf_alloc/free的操作,这片空间主要由MEM_SIZE控制。
作者进行对60kB数据分包实验,根据第一部分的分析将MEM_SIZE设置为140*1024,debug模式生成的HPM6750程序,内存占比如下。

由于需要用到DLM(数据本地存储器(Data Local Memory))加速计算,加之其空间有限,因此以太网的数据放在DLM里并不经济。考虑将mem开到SRAM里面或外部SDRAM里。
== 经过作者顺藤摸瓜式的一番查找(lwip_init -> mem_init -> ram -> LWIP_DECLARE_MEMORY_ALIGNED -> LWIP_MEM_SECTION),在cc.h中找到了定义mem_heap的存储位置的宏定义 ==。
修改如下:
#ifndef LWIP_MEM_SECTION
#define LWIP_MEM_SECTION ".axi_ram"
//#define LWIP_MEM_SECTION ".fast_ram"
#endif
此处的.axi_ram为作者在linker script中新声明的SRAM区域,如下
place in AXI_SRAM { section .axi_sram}; // Fast access memory
经修改后内存分配如下图,将内存堆分配到SRAM会一定程度上降低处理速度,作者经简单测试,处理时间增加并不多,具体请读者自行测试。
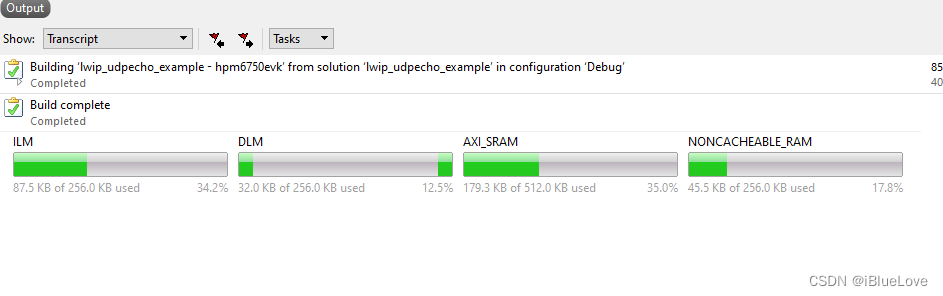
2024.04.08:由于DLM是cache失效的,因此并不需要考虑命中数据在DMA传输前需要从cache写入到内存的问题,而SRAM与SDRAM在cache默认使能的前提下,需要cache的wirte_back。详细可以查看先楫半导体公众号的文章(链接https://mp.weixin.qq.com/s/9kbam5N-CFCCixz1UYc0bQ)或产品的数据手册。
具体可以在 low_level_output() 加入 l1c_dc_writeback_all(),或者 l1c_dc_writeback(…)。如下。
}
/* Prepare transmit descriptors to give to DMA*/
frame_length += 4;
if(l1c_dc_is_enabled()){
l1c_dc_writeback_all();
}
#if defined(LWIP_PTP) && LWIP_PTP
enet_prepare_tx_desc_with_ts_record(ENET, &desc.tx_desc_list_cur, &desc.tx_control_config, frame_length, desc.tx_buff_cfg.size, ×tamp);
/* Get the transimitted timestamp */
p->time_sec = timestamp.sec;
p->time_nsec = timestamp.nsec;
#else
enet_prepare_tx_desc(ENET, &desc.tx_desc_list_cur, &desc.tx_control_config, frame_length, desc.tx_buff_cfg.size);
#endif
四、总结
-
在对代码进行仔细分析前,作者在网上查找方法,发现部分STM32也有前面分析的两种问题,因此将其写在标题中,希望可以帮助更多人降低调试成本,欢迎交流。
-
作者学生一枚,认识与经验有限,以上所述仅为作者浅知薄见,定然有理解与描述不当之处,希望得到指正。















 4135
4135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









