







正则表达式的概念





re库的基本使用













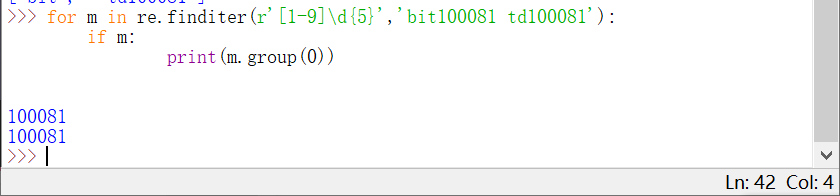





re库的match对象
type(match)可以查看match的类型




re库的贪婪匹配和最小匹配




淘宝商品信息定向爬虫
实例一:
 https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200216&ie=utf8
https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200216&ie=utf8
https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200216&ie=utf8&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=44
https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200216&ie=utf8&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=88
发现search?q=书包,书包是我们搜索的关键词,q就是引进关键词的变量.前面这一部分就是向淘宝提交关键词的链接接口.
在看看第二页,第三页,提交相关的链接,有一点不同.就是最后s这个变量.第二页s=44,第三页s=88.如果细心数一下每页淘宝展示的商品数量,恰好是44个商品.因此我们可以得出这样的猜测变量s是第二页,第三页,甚至更多下一页的起始商品的编号.
通过这样的基本分析,可以得到淘宝提交搜索的接口以及对应每一页翻页的url的参数变量.可以确立向淘宝商品提交商品相关的url接口.
查看robots协议
 说明淘宝的搜索页面不允许爬虫进行爬取
说明淘宝的搜索页面不允许爬虫进行爬取
 爬取淘宝信息的源代码
爬取淘宝信息的源代码
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(":")[1])
title = eval(tlt[i].split(":")[1])
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
tilt = "{:4}\t{:8}\t{:16}"
print(tilt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tilt.format(count, g[0], g[1]))
def main():
goods = "书包"
depth = 2
start_url = "https://s.taobao.com/search?q=" + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44 * i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
但是上面代码因为反爬虫爬不出来,目前淘宝要求登陆才能进行商品查询,因此可以使用你的账号cookies和user-agent模拟浏览器来爬取,后面参看大佬的代码如下
#参考代码
import requests
import re
def get_html_text(url):
#user-agent:
# Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36
#User-Agent 为cookis再下拉的内容,chorm浏览器按F12键
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
try:
# coo后面 为自己登陆淘宝后。输入搜索后的cookies
coo = ''
cookies = {}
for line in coo.split(';'): # 浏览器伪装
name, value = line.strip().split('=', 1)//strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
cookies[name] = value
r = requests.get(url, cookies=cookies, headers=headers, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
# 步骤2:对于每个页面,提取商品名称和价格信息
def parse_page(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) # findall搜索全部字符串,viex_price是源代码中表价格的值,后面的字符串为数字和点组成的字符串
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) # 找到该字符串和后面符合正则表达式的字符串
for i in range(len(plt)):
price = eval(plt[i].split(':')[1]) # re.split() 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
title = eval(tlt[i].split(':')[1]) # 将re获得的字符串以:为界限分为两个字符串,并取第二个字符串
ilt.append([price, title])
except:
print('')
# 步骤3:将信息输出到屏幕上
def print_goods_list(ilt):
tplt = "{:4}\t{:8}\t{:16}" # 长度为多少
print(tplt.format('序号', '价格', '名称'))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = ''
depth = 3 # 要爬取几页
start_url = 'https://s.taobao.com/search?q=' + goods
info_list = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i) # 44是淘宝每个页面呈现的宝贝数量
html = get_html_text(url)
parse_page(info_list, html)
except:
continue
print_goods_list(info_list)
main()















 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









