







判断自己是否很大程度理解了所学的知识点,最好的方式就是按照自己的理解给别人讲解,对于我而言,用文字的形式记录,更加合适。这是费曼学习法的精髓。我以前学习知识,看完之后总是觉得自己懂了,但是实际操作的时候,却发现不知道如何下手。这也许就是所谓的“眼高手低”。 也许有人会说,给别人讲解和再操作一遍,不是很花费时间吗,还不如多花点时间去学习其他东西。我想说,多花点时间学习和理解一样东西,和只是学习每样东西,都花一点时间,带给我们的收益,是绝对不一样的。也许从当前看,好像自己花了特别多时间来学习和理解,但是从长远看,当你完全理解了知识后,以后几乎都不需要怎么回顾,就能够理解知识的核心内容。而且,古人说:“温故而知新”,当学了知识后,再去讲解出来,不就是“温故而知新”吗?所以以后学习每个觉得有意义和价值的算法时,我都将自己的学习成果记录下来!
讲了前面一堆“废话”,既是自己的反思和想法,也是给看这篇文章的人,能够带来启发和激励。
好了,废话不多说。今天的主题缓存淘汰算法之LRU。
本文会按照3个步骤来讲解 1. 目的 2.原理讲解 3.代码剖析
1. 目的
任何算法产生的背后一定是存在某种需求。对于LRU算法,同样也是存在需求。现在微博十分火爆,每天都有好多人访问和浏览,尤其是每小时更新的“新闻头条”,比如前面一段时间“某某代孕”和“某某突然当爹”事件的发生。很多群众都喜欢吃瓜,一时间一群人疯狂点击此新闻。如果按照普通的存储方式,将信息都存储在mysql数据库当中,那么数据库根本承受不足如此高强度的访问,并可能导致服务器宕机。为了应对这种情况发生,引入了内存型数据库Redis,据官方称读写速度每秒高达10万条记录,这样就可以避免高并发事件引发的事故了。但随之也出现了一个问题,热点是会不断地更新,总不能一直存在缓存当中,那么就需要按照某种规则去淘汰。redis当中有许多淘汰机制,其中就有一个缓存淘汰算法(LRU)。所以,LRU就是为了淘汰缓存中存储的数据。
2. 原理讲解
LRU全称(Least Recentey Used)。LRU淘汰缓存数据的规则就是将很久没有使用过的缓存数据删除,这句话就是LRU算法的中心思想。接下来,我们就需要分析这句话------“很久没使用过的数据”。你会想如何知道这个数据是不是很久没有使用过的数据。这也是我们要解决的重点,解决办法就是使缓存的数据满足时序性。
一般的缓存都是采用K-V键值对存储,也就是HashMap数据结构。显然HashMap结构不满足时序性。那么哪些数据结构满足“时序性”,很容易想到链表这种结构。链表就是从头到尾按照顺序添加,先添加的可以放在前面,后添加的放在后面。但是还有一个问题,从链表中找到某个元素,时间复杂度高。
HashMap访问数据快,但是存储数据不具有时序性。
LinkedList数据结构具有时序性,而且增加结构和删除节点的时间复杂度为O(1),但是查找某个节点时间复杂高。
为了解决上述问题,于是提出了LInkedHashMap数据结构,这也是LRU中核心的数据结构,如下图所示。
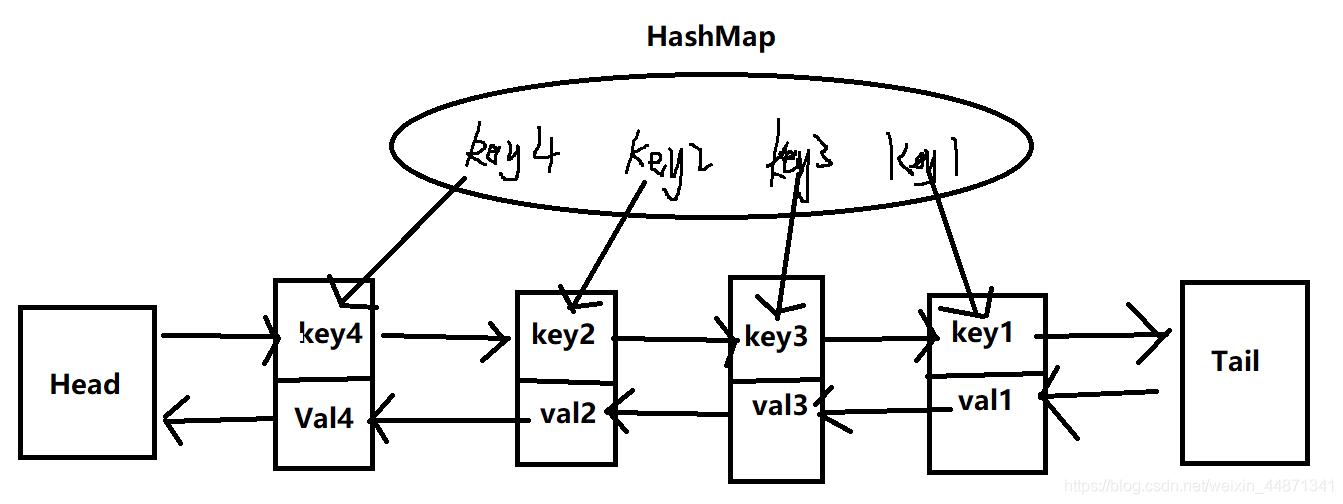
上面就是通过HashMap映射到LinkedlLIst当中的节点,并使用双向链表。
我们可以假设,链表的节点从左到右越新,第一个最旧。也就是当缓存需要删除数据时,就优先删除第一个节点,因为其很久没有被使用过了。
另外,我们还需要注意几点:
- 从缓存中获取数据时,要使当前数据移到链表最右端,表示最近使用过
- 给缓存中添加数据时,考虑的情况多一点,见下图:
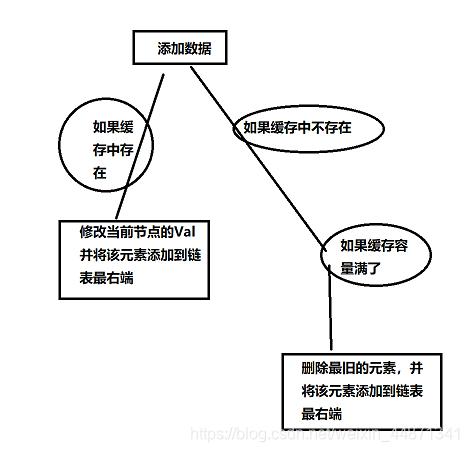
在操作链表的过程中, 也要注意Hashmap是否需要修改。
接下来,通过代码的形式,来实现上述所说的功能。
3. 代码剖析
阅读完以上信息,对LRU原理有了大致的了解,但是对其实现,还是懵懵懂懂。接下来,我们就来从头到尾来剖析代码。
首先声明链表中节点类:
class Node{
public Node pre, next;
public int key, val;
public Node(int k, int v){
this.key = k;
this.val = v;
}
}
接下来使双向链表:
class DoubleList{
// 头尾 虚节点(无实际意义)
private Node head, tail;
private int size ; // 链中存储的元素
public DoubleList(){ // 构造器,初始化
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.pre = head;
size = 0;
}
//链表尾部,添加数据
public void addLast(Node e){
tail.pre.next = e;
e.pre = tail.pre;
e.next = tail;
tail.pre = x;
size ++;
}
//删除链表中的节点,假设此节点一定存在
public void remove(node e){
e.pre.next = e.next;
e.next.pre = e.pre;
size --;
}
//删除链表中的头结点, 并返回该节点
public Node removefirst(){
if(this.size == 0){
return null;
}
Node first = head.next;
remove(first);
return first;
}
}
经过前面很有必要的重复造轮子,接下来,实现LRUcache类
class LRUcache{
private HashMap<Integer, Node> map;
private Doublelist cache;
private int cap; // 容量
public LRUcache(int capcaity){ // 初始化
map = new HashMap<Integer, Integer>();
cache = new Doublelist();
this.cap = capcaity;
}
}
上面还只是个开始,还没有写方法。
在LRU中很重要的两个方法put() 和 get()方法还没写。此时要注意,这两个方法都需要操作链表和hashmap,为了整体代码耦合度比较低,不让这两个方法直接操作链表和hashmap。
接下来的每个方法,都是为了完成内存淘汰所需要的操作:
// 将某个key提升为最近使用
public void makeRecently(int key){
Node node = map.get(key);
cache.remove(node);
cache.addlast(node);
}
上面这段代码就是为了保证,当你从缓存中使用某个数据时,使该缓存数据的使用时间为最新。
//添加最近使用的元素
public void addRecently(int key, int val){
Node x = new Node(key, val);
cache.add(x);
map.put(key, val);
}
以上代码是保证添加新元素时的操作
// 删除某一个key
public void deletekey(int key){
Node x = map.get(key);
cache.remove(x);
map.remove(key);
}
注意从缓存中删除数据时,也要将map中的数据删除
// 删除很久没有使用的key
public void removeleastRenctely(){
Node e = cache.removeFirst();
int delete = e.key;
map.remove(delete);
}
至此,全部准备工作以及完成,只需要完成最后两个方法,Put() 和 get()
由于get方法实现简单一点,先完成get()方法
Node get(int key){
Node e = map.get(key);
makeRecently(e); // 重点
return e;
}
注意,当获取该缓存数据时,对时间性需要修改
接下来,就是put()方法的实现。
put方法考虑的内容比较多,在前面讲过需要考虑的内容,可能大家看到这已经忘记了,那么我把上面的图拿下来
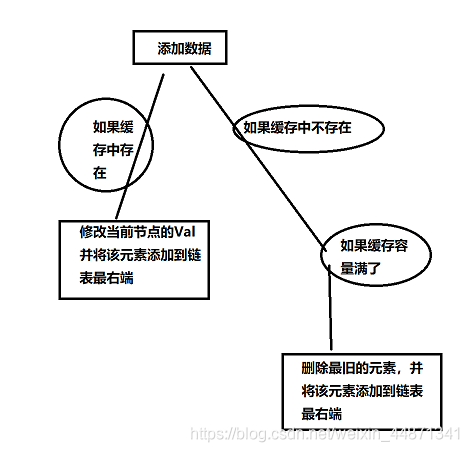
void put(int key, int val){
// 判断缓存中是否存在
if(map.contains(key)){
Node e = new Node(key, val);
map.add(key, val); // 修改原先的值
makeRenctly(e);
return
}
// 如果缓存中没有
//首先判断缓存数据是否存满
if(cache.size == cap){
removeleastRenctely(); // 删除旧的缓存
addRecently(key, val);
return
}
//如果缓存没有满
addRecently(key, val);
}
现在全部代码已经完成,给大家从头到尾撸了一遍,相信大家对LRU的实现有了非常直观的感受!!!
备注: 由于写作经验比较少, 在描述问题时难免存在模糊或者难懂,请大家多多指教和批评。我会不断地提升自己。














 1433
1433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









