







TEXTFILE
文本文件,默认的文件存储格式,内容是可以直接查看,用来保存非结构化数据;
特点:文本文件的格式一旦定义就无法改变.
除TEXTFILE外,其他文件存储格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中,
然后再从表中用insert导入SequenceFile,RCFile,ORCFile,PARQUET表中;
或者用复制表结果及数据的方式(create table as select * from table).
SEQUENCEFILE
序列文件,包含键值对的二进制的文件存储格式,支持压缩,sequencefile格式的表数据比相同数据的textfile文件还要大,
这是因为sequencefile表在创建时,增加了很多额外信息,在生产中不使用此种类型的文件格式.
RCFile
RCFile文件格式是FaceBook开源的一种Hive的文件存储格式(可压缩),
是列式存储文件格式,适合压缩处理.对于有成百上千字段的表而言,RCFile更合适.
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE ;
如果数据需要压缩,使用 STORED AS SEQUENCEFILE、RCFile、ORC.
因为TextInputFormat对输入的文件行数是有限制的(默认是Integer.max_val),所以如果原始数据的行数过多那么就会导致无法读取的现象,那如果遇到这种行数过多的数据应该如何处理呢?
首先将表分为几个行组,对每个行组内的数据进行按列存储,每一列的数据都是分开存储,正是先水平划分,再垂直划分的理念.
其实表数据的 行 与 列 来看的话,列的个数肯定是有限的,所以我们把列当做行,这样就能确保这个表的行数一定不会太多,
然后把这列的所有行数据转成现在的一行的列数据,这样获取数据的时候纵向获取现在一列的数据其实就是之前的一行数据.
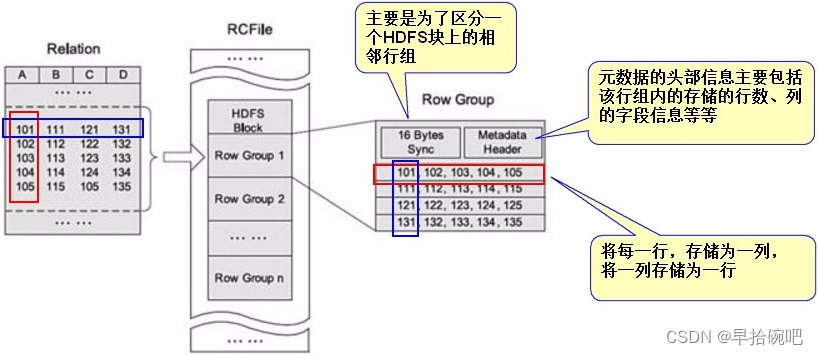
在存储空间上:
RCFile采用游程编码,相同的数据不会重复存储,很大程度上节约了存储空间,尤其是字段中包含大量重复数据的时候.
5555557777733322221111111 游程编码为:(5,6)(7,5)(3,3)(2,4)(1,7).
-- 可见,游程编码的位数远远少于原始字符串的位数.
// TEXTFILE对应的是
org.apache.hadoop.mapred.TextInputFormat 和 org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
// SEQUENCEFILE对应的是
org.apache.hadoop.mapred.SequenceFileInputFormat 和 org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
// RCFILE对应的是
org.apache.hadoop.hive.ql.io.RCFileInputFormat 和 org.apache.hadoop.hive.ql.io.RCFileOutputFormat
/**
INPUTFORMAT 指定输入数据由哪个数据格式化类来处理
OUTPUTFORMAT 指定输出数据由哪个数据格式化类来处理
这两个选项主要配置的是HIVESQL运行期间的MapReduce的输入与输出的格式化.
*/
ORC
1.orc 定义
ORC File,它的全名是Optimized Row Columnar (优化的行列) file,其实就是对RCFile做了一些优化.
降低数据存储空间 : orcfile 默认采用 zlib 格式进行压缩.
使用压缩的优势是可以最小化所需要的磁盘存储空间,以及减少磁盘和网络io操作;
ORC支持三种压缩: ZLIB,SNAPPY,NONE;
最后一种就是不压缩,orc默认采用的是ZLIB压缩.
加速hive查询速度 : orcfile 最主要的优点是在文件中存储了一些轻量级的索引数据,内部采用一个数组存储avro表中的某一列数据供特定开发人员使用.
orcfile 不但解决了查询速度问题,而且也解决了数据存储问题;
运用ORC File可以提高Hive的读、写以及处理数据的性能.
2.orc 文件结构
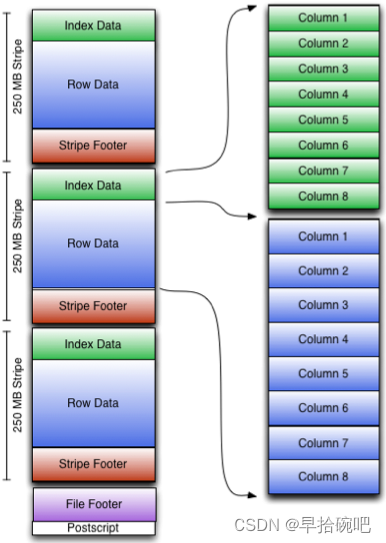
ORC File包含一组组的行数据,称为stripes(带),除此之外,ORC File的file footer还包含一些额外的辅助信息.
在ORC File文件的最后,有一个被称为postscript(后记,附言,补充)的区,它主要是用来存储压缩参数及压缩页脚的大小.
默认情况下,一个stripe的大小为250MB. 大尺寸的stripes使得从HDFS读数据更高效。
下图显示出可ORC File文件结构:
| Postscript | 存储该表的行数,压缩参数,压缩大小,列等信息; |
|---|---|
| FileFooter | 包含该表的统计结果,以及各个Stripe的位置信息; |
| Stripe Footer | 包含该stripe的统计结果,包括Max、Min、count等信息; |
| IndexData | 保存了该stripe上数据的位置信息,总行数等信息; |
| RowData | 以stream的形式保存了数据的具体信息. |
3.Stripe结构
从上图可以看出,每个Stripe都包含index data、row data以及stripe footer.
Row data在表扫描的时候会用到;
Stripe footer包含流位置的目录;
Index data包含每列的最大和最小值以及每列所在的行.
行索引里面提供了偏移量,它可以跳到正确的压缩块位置.
具有相对频繁的行索引,使得在stripe中快速读取的过程中可以跳过很多行,尽管这个stripe的大小很大. 在默认情况下,最大可以跳过10000行.
hive读取数据的时候,根据FileFooter读出Stripe的信息,根据IndexData读出数据的偏移量从而读取出数据.
















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











