







前言
在测试工程师的日常工作中,清理 docx 格式的需求文档是一项关键任务,尤其是为了去除无用内容(如页眉、页脚、目录、模板文字等),保留有价值的信息。然而,需求文档中可能包含图片等非文本内容,而之前的代码未对图片的处理进行优化,这会导致 GUI 闪退或程序崩溃。此外,针对大文档的处理,性能优化也至关重要。
本文将解决以下问题:
- 处理包含图片的需求文档:避免因图片导致 GUI 闪退或程序崩溃。
- 优化性能:针对大文档,提高清理和处理效率。
- 详细阐述使用场景:解释工具适用的具体场景及用户体验。
- 可扩展方向:提出未来功能扩展的具体建议。
问题分析
1. 图片导致 GUI 闪退的原因
在之前的代码中,仅处理了 docx 中的文本内容(段落和表格),而未正确处理嵌入的图片。当文档中有图片时:
- 如果图片未被正确忽略或解析,
python-docx在读取时可能会抛出异常。 - GUI 的文本框试图显示图片数据时,由于其仅支持文本,导致程序崩溃或闪退。
2. 性能问题
在处理大文档时:
- 文本分割、正则匹配和模板内容过滤可能耗费较多时间。
- 每次操作都需要重新从
docx文件中提取内容,缺少缓存或优化机制。
解决方案与优化
1. 处理图片问题
- 忽略图片:在提取段落和表格时,跳过图片,保证程序的稳定性。
- 支持图片提取(可选):如果需要,可以将图片提取到本地文件夹或以占位符形式保存。
2. 性能优化
- 文件解析优化:将
docx文件的读取和解析分离,仅在首次加载时解析文档,后续操作基于内存数据。 - 并行处理:对于大文档中的段落分割和清理任务,采用多线程或多进程处理。
- 实时预览优化:在 GUI 中引入分页加载或异步渲染,避免一次性加载大文档导致卡顿。
优化后的代码实现
以下是针对图片问题和性能优化后的代码实现。
1. 提取文档内容(处理图片)
修改 extract_content 方法,增加对图片的处理逻辑。
from docx import Document
import os
def extract_content(file_path, image_folder="extracted_images"):
"""
提取需求文档内容,包括段落、表格,并处理图片。
:param file_path: docx 文件路径
:param image_folder: 图片保存路径(可选)
:return: dict, 包括段落、表格、页眉和页脚
"""
doc = Document(file_path)
content = {"paragraphs": [], "tables": [], "images": []}
# 创建图片保存文件夹
if not os.path.exists(image_folder):
os.makedirs(image_folder)
# 提取段落内容
for paragraph in doc.paragraphs:
if paragraph.text.strip():
content["paragraphs"].append(paragraph.text.strip())
# 提取表格内容
for table in doc.tables:
table_data = []
for row in table.rows:
row_data = [cell.text.strip() for cell in row.cells]
table_data.append(row_data)
content["tables"].append(table_data)
# 提取图片内容(保存到本地)
for rel in doc.part.rels.values():
if "image" in rel.target_ref:
image_data = rel.target_part.blob
image_name = os.path.join(image_folder, os.path.basename(rel.target_ref))
with open(image_name, "wb") as img_file:
img_file.write(image_data)
content["images"].append(image_name)
return content
2. GUI 优化
修改 PyQt5 GUI 代码,增加对图片的处理,避免因图片导致闪退。
(1) 增加图片显示选项
在 GUI 中,新增一个列表用于显示提取到的图片路径,用户可以选择是否预览图片。
from PyQt5.QtWidgets import (
QApplication, QMainWindow, QFileDialog, QVBoxLayout, QLabel, QTextEdit,
QPushButton, QListWidget, QWidget, QMessageBox
)
from PyQt5.QtGui import QPixmap
from PyQt5.QtCore import Qt
class DocxCleanerGUI(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("智能清理需求文档工具")
self.setGeometry(200, 200, 900, 700)
self.initUI()
def initUI(self):
layout = QVBoxLayout()
# 文件选择按钮
self.select_file_btn = QPushButton("选择需求文档")
self.select_file_btn.clicked.connect(self.select_file)
layout.addWidget(self.select_file_btn)
# 文件内容预览
self.file_content_preview = QTextEdit()
self.file_content_preview.setReadOnly(True)
layout.addWidget(QLabel("原始文档内容:"))
layout.addWidget(self.file_content_preview)
# 图片列表与预览
self.image_list = QListWidget()
self.image_list.itemClicked.connect(self.preview_image)
layout.addWidget(QLabel("文档中的图片:"))
layout.addWidget(self.image_list)
self.image_preview = QLabel()
self.image_preview.setAlignment(Qt.AlignCenter)
layout.addWidget(self.image_preview)
# 清理按钮
self.clean_btn = QPushButton("清理文档")
self.clean_btn.clicked.connect(self.clean_file)
layout.addWidget(self.clean_btn)
# 保存按钮
self.save_btn = QPushButton("保存清理结果")
self.save_btn.clicked.connect(self.save_file)
layout.addWidget(self.save_btn)
# 设置中心布局
container = QWidget()
container.setLayout(layout)
self.setCentralWidget(container)
def select_file(self):
file_path, _ = QFileDialog.getOpenFileName(self, "选择DOCX文件", "", "Word文件 (*.docx)")
if file_path:
self.file_path = file_path
content = extract_content(file_path)
self.file_content_preview.setText("\n".join(content["paragraphs"]))
self.image_list.clear()
for image_path in content["images"]:
self.image_list.addItem(image_path)
def preview_image(self, item):
pixmap = QPixmap(item.text())
if pixmap.isNull():
QMessageBox.warning(self, "图片预览失败", "无法加载图片!")
else:
self.image_preview.setPixmap(pixmap.scaled(400, 300, Qt.KeepAspectRatio))
def clean_file(self):
if hasattr(self, "file_path"):
content = extract_content(self.file_path)
cleaned_content = clean_headers_footers(content)
cleaned_content = remove_template_phrases(cleaned_content)
self.file_content_preview.setText("\n".join(cleaned_content["paragraphs"]))
def save_file(self):
if hasattr(self, "file_path"):
output_path, _ = QFileDialog.getSaveFileName(self, "保存清理结果", "", "JSON文件 (*.json)")
if output_path:
content = {"paragraphs": self.file_content_preview.toPlainText().split("\n")}
save_to_json(content, output_path)
if __name__ == "__main__":
app = QApplication([])
window = DocxCleanerGUI()
window.show()
app.exec_()
3. 使用场景详细阐述
适用场景
-
需求文档清理:
- 去除无用内容(页眉、页脚、模板注释等),提取关键需求。
- 处理带有图片的文档,保证清理结果的完整性。
-
测试用例设计:
- 从清理后的文档中提取测试用例所需的业务逻辑。
-
缺陷报告生成:
- 提供清晰的需求上下文,辅助 Bug 定位及报告撰写。
-
文档归档:
- 将清理后的文档和提取的图片归档,便于后续检索和分析。
4. 可扩展方向
(1) 支持更多文档格式
- 增加对 PDF、Markdown、Excel 等格式的支持,扩展工具的适用范围。
(2) 智能清理规则
- 使用自然语言处理(NLP)技术自动识别重要段落和非关键内容,提升清理准确性。
(3) 文档检索功能
- 将清理后的文档存入向量数据库(如 Milvus)中,结合 RAG 技术实现智能检索。
(4) 自动化报告生成
- 根据清理后的结果,自动生成测试用例或缺陷分析报告。
(5) 图像分析
- 对文档中的图片进行 OCR(文字识别),提取图片中的信息并与文本结合。
以下是 clean_headers_footers 和 remove_template_phrases 函数的代码,这些函数用于清理文档中的页眉、页脚内容以及模板固有的无用内容。
1. clean_headers_footers 函数
该函数用于清理文档中的页眉、页脚和目录内容。
功能说明:
- 过滤页眉和页脚:从提取的内容中删除页眉和页脚内容。
- 剔除目录:通过正则表达式匹配目录条目(如 “第x章”、“1.1.1” 等)并移除。
代码实现:
import re
def clean_headers_footers(content):
"""
清理文档中的页眉、页脚和目录内容。
:param content: 文档内容字典,包含段落(paragraphs)和表格(tables)
:return: 清理后的文档内容字典
"""
cleaned_content = {"paragraphs": [], "tables": content["tables"]}
# 页眉和页脚内容
headers_footers = content.get("headers", []) + content.get("footers", [])
for paragraph in content["paragraphs"]:
# 如果段落在页眉或页脚中,过滤掉
if paragraph in headers_footers:
continue
# 过滤掉可能是目录的内容
if re.match(r"^\s*(第[\d一二三四五六七八九十]+章|\d+(\.\d+)*).*", paragraph):
continue
# 如果段落不是空内容,将其保留
if paragraph.strip():
cleaned_content["paragraphs"].append(paragraph)
return cleaned_content
2. remove_template_phrases 函数
该函数用于删除文档中的模板固有内容,例如 “请填写”、“此处为模板” 等无用信息。
功能说明:
- 自定义模板短语:允许用户配置需要过滤的特定短语。
- 逐段检查:遍历段落内容,检查是否包含模板短语,若包含则剔除。
代码实现:
def remove_template_phrases(content):
"""
删除文档中的模板固有内容。
:param content: 文档内容字典,包含段落(paragraphs)和表格(tables)
:return: 清理后的文档内容字典
"""
# 模板固有短语列表,可以扩展
template_phrases = [
"请填写", "此处为模板", "模板内容", "示例", "举例",
"请参考以下格式", "本段用于描述", "请参照", "示意图"
]
cleaned_paragraphs = []
for paragraph in content["paragraphs"]:
# 如果段落包含模板短语,则跳过
if any(phrase in paragraph for phrase in template_phrases):
continue
cleaned_paragraphs.append(paragraph)
return {"paragraphs": cleaned_paragraphs, "tables": content["tables"]}
*3. save_to_json 函数
目的:将清理后的内容统一存储为 JSON 格式,以便后续的检索或进一步加工。
实现逻辑:
- 将段落和表格内容存储为键值对。
- 保证 JSON 的格式化输出,便于人工验收。
验收标准:
- 清理后的文档内容以 JSON 格式输出,结构清晰。
代码实现:
import json
def save_to_json(content, output_path):
"""
将清理后的文档内容保存为 JSON 格式
:param content: 清理后的文档内容
:param output_path: 输出文件路径
"""
with open(output_path, "w", encoding="utf-8") as f:
json.dump(content, f, ensure_ascii=False, indent=4)
效果展示
整体界面:
-
选取需求文档后,若文档中包含图片,则会同步展示图片。点击图片,会预览图片。
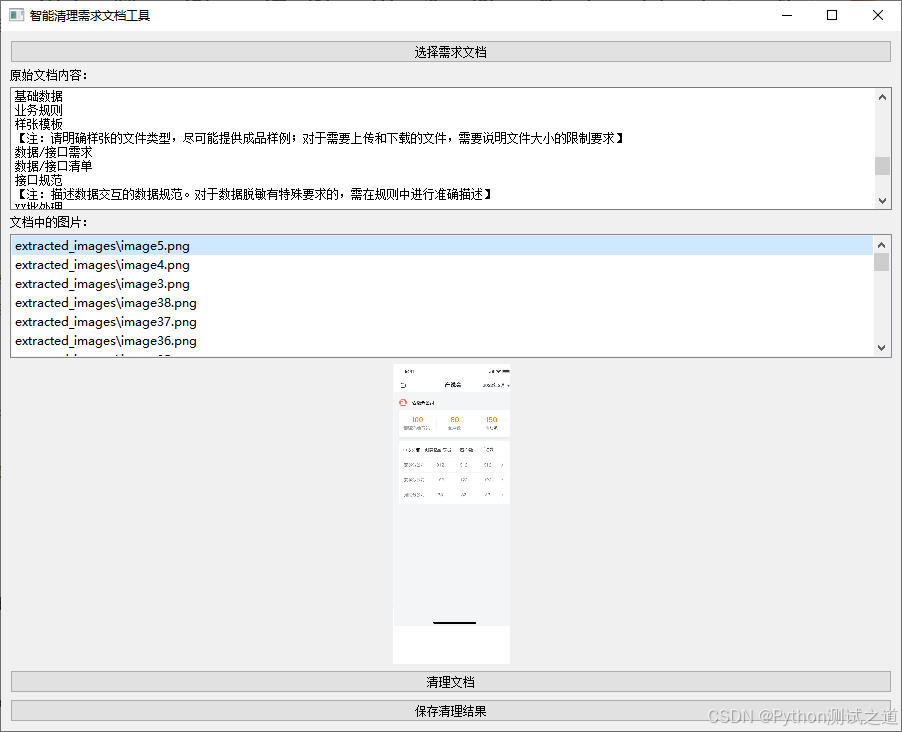
-
清理文档:
- 点击清理文档,内容会按照设定的规则进行清理。
-
保存清理结果:
- 点击后,弹框输入文件名,点击确定保存成功。图片也会一并保存,目录结果如下图所示。
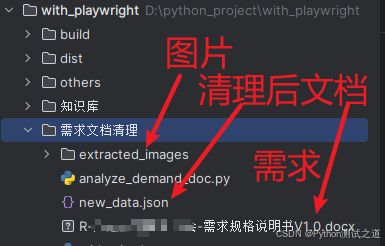
扩展性建议
-
动态模板短语:
- 允许用户通过配置文件或界面动态添加或修改模板短语,增强灵活性。
-
正则表达式增强:
- 针对模板固有内容,支持更多复杂的正则匹配(如多行注释、格式化段落)。
-
多语言支持:
- 针对不同语言的文档(如英文需求文档),提供相应的短语列表。
-
智能内容识别:
- 使用 NLP 技术自动分类段落是否为无用内容,减少误删。
总结
通过 clean_headers_footers 和 remove_template_phrases 函数,能够高效清理需求文档中的页眉、页脚、目录和模板内容,并为后续的测试资产提取和自动化测试用例设计提供高质量的输入数据。这些函数设计灵活,易于扩展,能够适配不同测试场景和业务需求。
本文解决了之前代码在处理带图片的需求文档时导致 GUI 闪退的问题,并通过优化性能提升了大文档处理效率。同时,我们详细阐述了工具的使用场景和扩展方向。通过进一步的功能扩展,该工具可以成为测试工程师在需求分析、测试设计和文档管理中的强大助手。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











