







引言
在现代软件开发过程中,测试工程师经常需要处理大量的文档资料。无论是产品说明书、技术规范还是用户手册,这些文档通常以Word(.docx)格式存储。如何快速准确地从中提取所需信息成为了一个挑战。本文将详细介绍一种基于Python的智能方法,通过解析Word文档来提取指定的正文内容、表格以及嵌入的图片,并结合阿里云百炼deepseek-r1接口进行高级应用开发。基于之前的Deepseek API+Python 测试用例一键生成与导出 V1.0.6(加入分块策略,返回更完整可靠),由于读取文档时,未完全适配同时输入文本标题、表格标题、图片标题的情形,本次主要是调试同时输入三种类型标题时的内容预览情况。实测见下图:
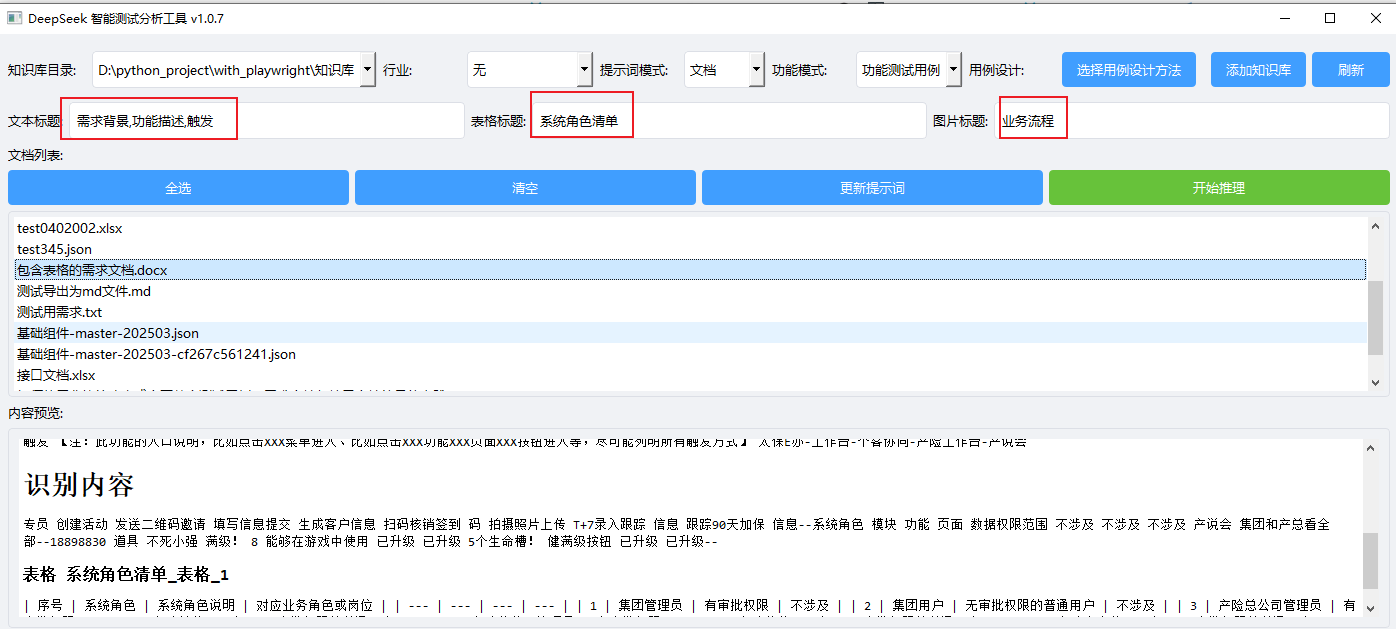
一、准备工作
首先,确保你已经安装了必要的Python库:
pip install python-docx opencv-python paddleocr lxml
这些库分别用于处理.docx文件(python-docx)、图像处理(opencv-python)、OCR文字识别(paddleocr)以及XML解析(lxml)。
二、正文内容提取
代码讲解:
from docx import Document
def extract_content(doc_path, title_keywords):
result = {
}
doc = Document(doc_path)
# 清理目录部分...
for keyword in title_keywords.split(','):
content = []
capture = False
for para in doc.paragraphs:
if keyword in para.text and 'toc' not in para.style.name.lower():
capture = True
content.append(para.text.strip())
continue
if capture:
if re.match(r"^\d+(\.\d+)*\s+.+", para.text.strip()):
break
content.append(para.text.strip())
result[keyword] = "\n".join(content)
return result
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











