







线程池的组成
1.线程池管理器:用于创建并管理线程池
2.工作线程:线程池中的线程
3.任务接口:每个任务必须实现的接口,用于工作线程调度其运行
4.任务队列:用于存放待处理的任务,提供一种缓冲机制
Java中的线程池是通过Executor框架实现的,该框架用到了Executor,Executors,ExecutorService,ThreadPoolExecutor,Callable和Future,FutureTask这几个类.
关于这几个类之间实现关系的UML图:
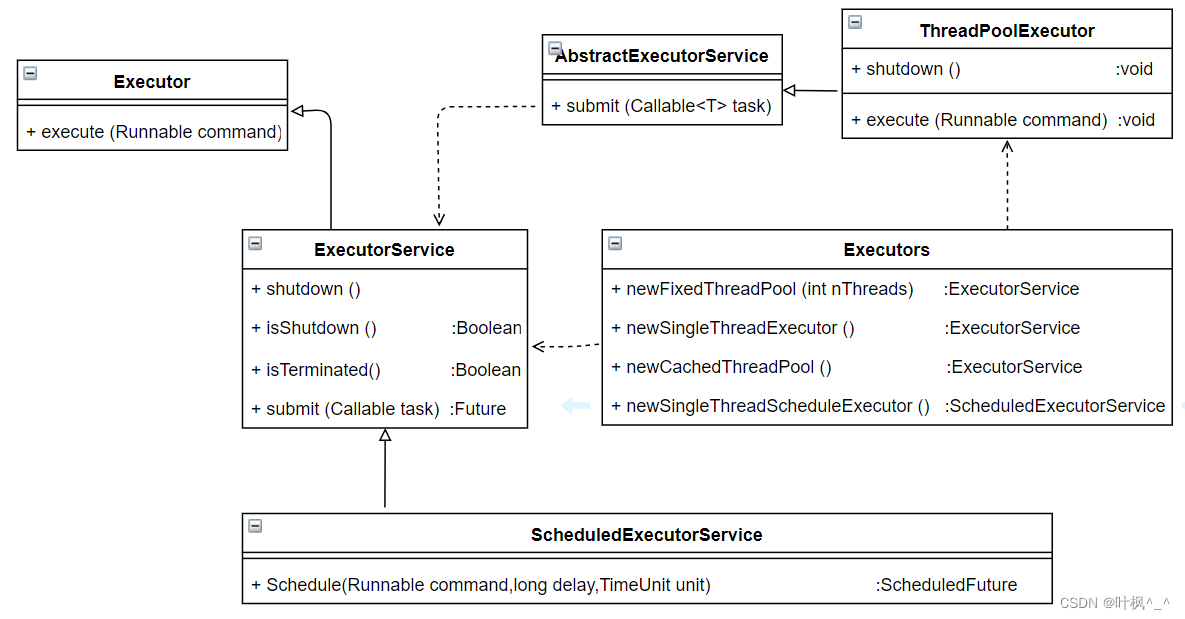
线程池的体系架构
java.util.concurrent.Executor: 负责线程的使用与调度的根接口
|--ExecutorService 子接口: 线程池的主要接口
|--ThreadPoolExecutor 线程池的实现类
|--ScheduledExecutorService 子接口: 负责线程的调度
|--SchediledThreadPoolExecutor: 继承ThreadPoolExecutor,实现ScheduledExecutorService
拒绝策略
线程池中的线程已经用完了,无法继续为新任务服务.同时等待队列也已经排满了,再也塞不下新任务了.这时候我们就需要拒绝策略机制合理的处理这个问题.
JDK内置的拒绝策略如下:
1.AbortPolicy: 直接抛出异常,组织系统正常运行.
2.CallerRunsPolicy: 只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务.显然这样做不会真的丢弃任务,但是,任务提交线程的性能极有可能会急剧下降.
3.DiscardOldestPolicy: 丢弃最老的一个请求,也就是即将被执行的任务,并且尝试再次提交当前任务.
4.DiscardPolicy: 该策略默默地丢弃无法处理的任务,不予任何处理.如果允许任务丢失,这是最好的一种方案.
注:以上内置拒绝策略均实现了RejectedExecutionHandler接口,若以上策略无法满足实际需要,完全可以自己拓展RejectExecutionHandler接口.
线程池创建方式
Java里面线程池的顶级接口是Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具.真正的线程池接口是ExecutorService.
为了便于跨大量上下文使用,此类提供了很多可调整的参数和拓展钩子(hook),.但是,强烈建议使用较为方便的工具类Executors工厂方法:
ExecutorService newFixedThreadPool():创建固定大小的线程池,可以进行自动线程回收.
/**
* @author chenjl
* @date 2022/5/7
* @desc ExecutorService newFixedThreadPool():创建固定大小的线程池,可以进行自动线程回收.
*/
public class NewFixedThreadPool {
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
final int index = i;
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
fixedThreadPool.execute(()-> System.out.println(index));
}
}
}
ExecutorService newCachedThreadPool():缓存线程池,线程数据量不固定,可以根据需求自动的更改数量.
/**
* @author chenjl
* @date 2022/5/7
* @desc ExecutorService newCachedThreadPool():缓存线程池,线程数据量不固定,可以根据需求自动的更改数量
*/
public class NewCachedThreadPool {
public static void main(String[] args) {
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int index = i;
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
cachedThreadPool.execute(()-> System.out.println(index));
}
}
}
ExecutorService newSingleThreadExecutor():创建单个线程池.线程池中只有一个线程.
/**
* @author chenjl
* @date 2022/5/7
* @desc ExecutorService newSingleThreadExecutor():创建单个线程池.线程池中只有一个线程
*/
public class NewSingleThreadExecutor {
public static void main(String[] args) {
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index = i;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
singleThreadExecutor.execute(()-> System.out.println(index));
}
}
}
ScheduledExecutorService newScheduledThreadPool():创建固定大小的线程,可以延迟或定时的执行任务.
/**
* @author chenjl
* @date 2022/5/7
* @desc ScheduledExecutorService newScheduledThreadPool():创建固定大小的线程,可以延迟或定
*/
public class NewScheduledThreadPool {
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
for (int i = 0; i < 10; i++) {
final int index = i;
scheduledThreadPool.schedule(()->System.out.println(index), 3, TimeUnit.SECONDS);
}
}
}
WorkStealingPoll():内部会创建ForkJoinPool,利用working-stealing算法,并行的处理任务,不保证处理的顺序
/**
* @author chenjl
* @date 2022/5/7
* @desc WorkStealingPoll():内部会创建ForkJoinPool,利用working-stealing算法,并行的处理任务,不保证处理的顺序
*/
public class WorkStealingPollTask {
private static Lock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
ExecutorService workStealingPool = Executors.newWorkStealingPool(2);
for (int i = 0; i < 100; i++) {
final int index = i;
workStealingPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + ":" + index);
});
}
//让主线程休眠3秒,保证所有的任务执行完成
TimeUnit.SECONDS.sleep(3);
}
}
6.ForkJoinPool分支/合并框架(工作窃取)
其工作机制,在必要的情况下,将一个大任务,进行拆分(即fork环节)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行join汇总.
其本质是采用Work-Stealing算法,从某个线程池的任务缓冲队列中窃取任务去执行.在fork/join框架实现中,如果某个子任务由于等待另外一个子任务的完成而无法继续执行,那么处理该子任务的线程会主动去寻找其他尚未运行的子任务来执行,这种方式减少了线程的等待时间,提高了性能.图示:
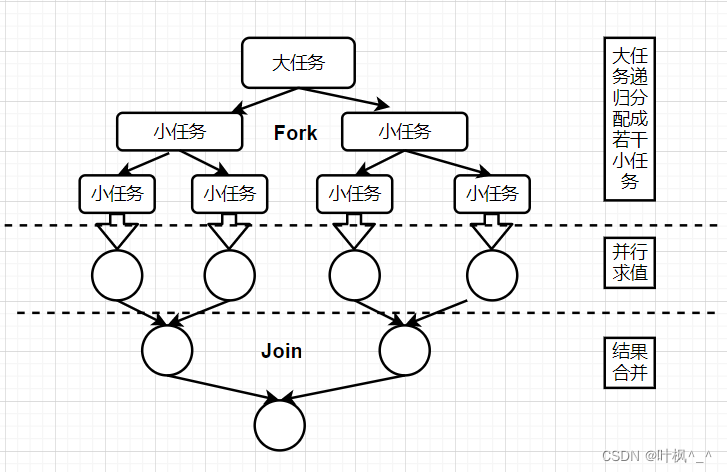
demo由于时间原因暂时缺省.
注:线程池都是通过 ThreadPoolExecutor 创建出来的。而创建参数中有一个队列参数用于存放任务。而这些队列的长度都是Integer的最大值。这就导致在实际应用中会造成内存溢出情况。这也是为什么阿里巴巴 java 手册不允许使用 Executors 创建线程池的原因。建议自定义线程池.
线程池大小的选择
CPU密集型: 线程数=按照核数+1
IO密集型: 线程数=CPU核数*(1+平均等待时间/平均工作时间)
















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











