







1. 因为池化层不具有参数,所以它们不影响反向传播的计算。
A 正确
B 错误
正确答案是:B, 您的选择是:A
解析:
- (1)max pooling层:对于max pooling,下一层的误差项的值会原封不动的传递到上一层对应区块中的最大值所对应的神经元,而其他神经元的误差项的值都是0;
- (2)mean pooling层:对于mean pooling,下一层的误差项的值会平均分配到上一层对应区块中的所有神经元。
由卷积层->池化层作为一个layer**,在前向传播过程中,池化层里保存着卷积层的各个部分的最大值/平均值,然后由池化层传递给下一层**,在反向传播过程中,由下一层传递梯度过来,“不影响反向传播的计算”意味着池化层到卷积层(反向)没有梯度变化,梯度值就为0,既然梯度值为0,那么例如在 W [ l ] = W [ l ] − α × d W [ l ] W[l]=W[l]−α×dW[l] W[l]=W[l]−α×dW[l]的过程中,参数 W [ l ] = W [ l ] − α × 0 W[l]=W[l]−α×0 W[l]=W[l]−α×0,也就是说它不再更新,那么反向传播到此中断。所以池化层会影响反向传播的计算。
2. 为了构建一个非常深的网络,我们经常在卷积层使用“valid”的填充,只使用池化层来缩小激活值的宽/高度,否则的话就会使得输入迅速的变小。
A 正确
B 错误
正确答案是:B, 您的选择是:A
解析:我们经常使用“SAME”的padding方式。
2.1 卷积的三种模式:full, same, valid
参考:https://blog.csdn.net/leviopku/article/details/80327478
本文清晰展示三种模式的不同之处,其实这三种不同模式是对卷积核移动范围的不同限制。
设 image的大小是7x7,filter的大小是3x3
2.1.1 full模式
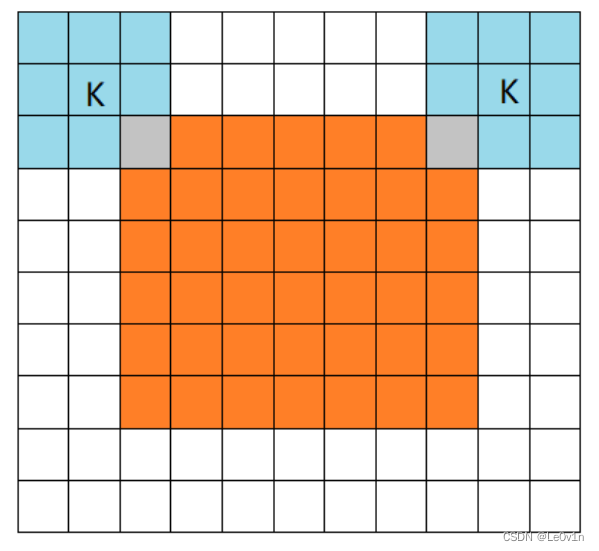
橙色部分为image, 蓝色部分为filter。full模式的意思是,从filter和image刚相交开始做卷积,白色部分为填0。filter的运动范围如图所示。
2.1.2 same模式
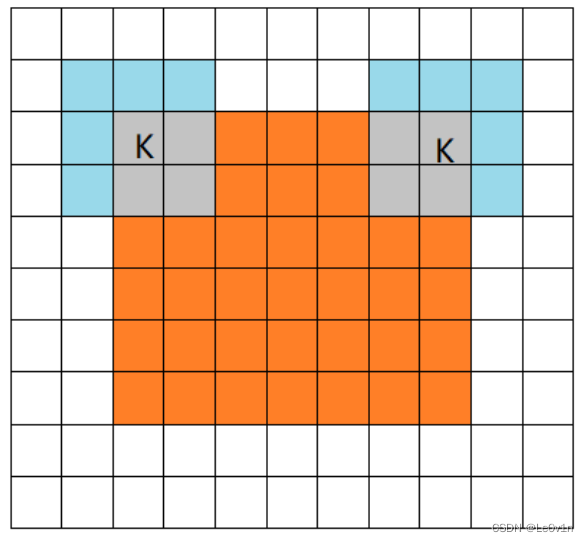
当filter的中心(K)与image的边角重合时,开始做卷积运算,可见filter的运动范围比full模式小了一圈。
Note:
- 这里的same还有一个意思,卷积之后输出的feature map尺寸保持不变(相对于输入图片)。
- 当然,same模式不代表完全输入输出尺寸一样,也跟卷积核的步长有关系。
- same模式也是最常见的模式,因为这种模式可以在前向传播的过程中让特征图的大小保持不变,调参师不需要精准计算其尺寸变化(因为尺寸根本就没变化)。
2.1.3 valid模式
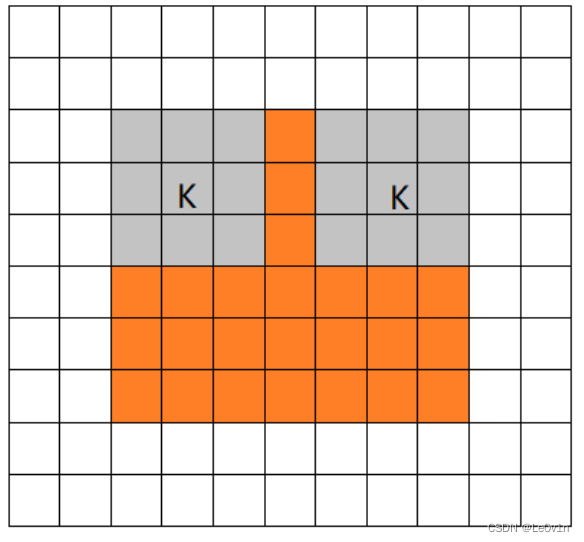
当filter全部在image里面的时候,进行卷积运算,可见filter的移动范围较same更小了。
3. 我们使用普通的网络结构来训练一个很深的网络,要使得网络适应一个很复杂的功能(比如增加层数),总会有更低的训练误差。
A 正确
B 错误
正确答案是:B, 您的选择是:B
解析:在没有残差的普通神经网络中,理论上是误差越来越低的,但是实际上是随着网络层数的加深,先减小再增加;在有残差的ResNet中,即使网络再深,训练误差都会随着网络层数的加深逐渐减小(过拟合风险越高!)。
4. 关于残差网络下面哪个(些)说法是错误的?
A 使用跳越连接能够对反向传播的梯度下降有益且能够帮你对更深的网络进行训练。
B 跳跃连接计算输入的复杂的非线性函数以传递到网络中的更深层。
C 跳跃连接能够使得网络轻松地学习残差块类的输入输出间的身份映射。
正确答案是:A, 您的选择是:B
5. 以下模型中,在数据预处理时,不需要考虑归一化处理的是
A logistic回归
B SVM
C 树形模型
D 神经网络
正确答案是:C, 您的选择是:C
解析:树形模型不需要特征本身的取值运算,不需要归一化。
6. 有关 TensorFlow API,以下说法中正确的是
A tf.Variable和一般编程语言中“变量(Variable)”的含义完全相同。
B tf.placeholder定义的对象,对应于深度神经网络中的“超参数(Hyperparameter)”。
C 通过tf.constant定义的对象,因为是常量,所以,在session.run()运行前就可以用eval()方法获得对象的值。
D session.run()运行一个训练过程时,TensorFlow会使用符号执行(SymbolicExecution)对计算图进行优化。
正确答案是:D, 您的选择是:D
解析:
- A 选项 tf中 变量的定义和初始化是分开的,一般编程语言定义即初始化。如
tf.Varialbe(3, name='x'), 只是定义,或者说"画"好流程图,还需要使用run(tf.global_variables_initializer())初始化图中所有变量或其他初始化变量的方式。 - B 选项
tf.placeholder()通俗讲作用为占位符,先定义好过程,在执行的时候再”喂"具体值(输入数据) - C 选项 可以同A选项一同解释,必须要等到
run之后才能得到具体值。 - D 选项 TensorFlow使用了向量运算的符号图方法,事先定义图,然后使用SymbolicExecuption进行优化。 正确
7. 下面哪些算法模型不可以用来完成命名实体的任务
A LDA
B CRF
C LSTM
D seq2seq
正确答案是:A, 您的选择是:A
解析:LDA是无监督的任务,命名实体需要有标签。
8. 深度学习中,以下哪些方法不可以降低模型过拟合?
A 增加更多的样本
B Dropout
C 增大模型复杂度,提高在训练集上的效果
D 增加参数惩罚
正确答案是:C, 您的选择是:C
解析:增大模型复杂度会提高过拟合。
9. 深度学习中的不同最优化方式,如SGD,ADAM下列说法中正确的是
A 在实际场景下,应尽量使用ADAM,避免使用SGD
B 同样的初始学习率情况下,ADAM的收敛速度总是快于SGD方法
C 相同超参数数量情况下,比起自适应的学习率调整方式,SGD加手动调节通常会取得更好效果
D 同样的初始学习率情况下,ADAM比SGD容易过拟合
正确答案是:C, 您的选择是:D
解析:选择优化方法不存在绝对不绝对,只有适合不适合。
10. 深度学习中,以下哪种方法不能解决过拟合的问题
A 提前停止训练
B 数据增强
C 参数正则化
D 减小学习率
正确答案是:D, 您的选择是:D
解析:减小学习率只是一种调参的方法,不能解决过拟合。
11. 深度学习中,不经常使用的初始化参数W(权重矩阵)的方法是哪种
A 高斯分布初始化
B 常量初始化
C Xavier初始化
D MSRA初始化
正确答案是:B, 您的选择是:B
解析:为了让神经网络在训练过程中学习到有用的信息,需要参数更新时的梯度不为0。在一般的全连接网络中,参数更新的梯度和反向传播得到的状态梯度以及输入激活值有关。那么参数初始化应该满足以下两个条件:
- 初始化必要条件一:各层激活值不会出现饱和现象(对于sigmoid, tanh);
- 初始化必要条件二:各层激活值不为0。
常量初始化很有可能无法满足条件一,因为输出值会很大,通过激活函数后,很容易饱和。
12. 在深度学习网络中, 以下哪种技术不是主要用来做网络正则化的(提升模型泛化能力)
A dropout
B 参数共享
C Early stopping
D Pooling
正确答案是:B, 您的选择是:D
解析:参数共享是一种网络结构,不能用来正则化
Pooling通过减少数据的复杂度从而充当正则项
13. 关于CNN,以下说法错误的是
A CNN可用于解决图像的分类及回归问题
B CNN最初是由Hinton教授提出的
C CNN是一种判别模型
D 第一个经典CNN模型是LeNet
正确答案是:B, 您的选择是:B
解析:Lecun提出
14. 相对于DNN模型,CNN模型做了哪些改变?
A 局部连接、参数共享
B 使用了ReLU激活函数
C 使用了Dropout
D 增加了batch normalization
正确答案是:A, 您的选择是:A
解析:其他三个DNN都有
15. 在CNN网络中,一张图经过核为3x3,步长为2的卷积层,ReLU激活函数层,BN层,以及一个步长为2,核为2*2的池化层后,再经过一个3*3的的卷积层,步长为1,此时的感受野是
A. 10
B. 11
C. 12
D. 13
正确答案是:D, 您的选择是:B
解析:
L
0
=
1
,
L
1
=
1
+
(
3
−
1
)
=
3
,
L
2
=
3
+
(
2
−
1
)
×
2
=
5
,
L
3
=
5
+
(
3
−
1
)
2
×
2
=
13
L_0 = 1, L_1 = 1 + (3-1) = 3, L_2 = 3 + (2-1)\times 2 = 5, L_3 = 5 + (3-1)2\times 2 = 13
L0=1,L1=1+(3−1)=3,L2=3+(2−1)×2=5,L3=5+(3−1)2×2=13
16. LSTM的遗忘门使用的是什么激活函数
A Sigmoid
B tanh
C ReLU
正确答案是:A, 您的选择是:B
解析:看下LSTM结构图就明白了。 可以简单理解0代表全部遗忘,1代表全部保留,所以用的是sigmoid
17. 关于Attention机制里的Attention-based Model,下列说法正确的是
A 相似度度量模型
B 是一种新的深度学习网络
C 是一种输入对输出的比例模型
D 都不对
正确答案是:A, 您的选择是:A
解析:Attention-based Model其实就是一个相似性的度量,当前的输入与目标状态越相似,那么在当前的输入的权重就会越大,说明当前的输出越依赖于当前的输入。严格来说,Attention并算不上是一种新的model,而仅仅是在以往的模型中加入attention的思想,所以Attention-based Model或者Attention Mechanism是比较合理的叫法,而非Attention Model。
18. 请问seq2seq不适用于一下哪些场景的建模
A 翻译
B人机对话
C 文本摘要生成
D 使用AlexNet做图像分类
正确答案是:D, 您的选择是:D
解析:seq2seq属于生成模型,用于生成任务。
19. 在卷积神经网络计算中,已知输入特征层大小为32x32x64, 使用标准卷积计算,带偏置项,卷积核大小为3*3,输出特征层数目为64,请问卷积层的参数个数为?
A 576
B 36928
C 640
D 36864
正确答案是:B, 您的选择是:B
解析:卷积参数:3364*64 = 36864偏置项:64(算出来的每个通道带一个偏置项参数就行)总共:36928


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









