









after all,..Multi-modal Fusion Functions
摘要
从物体分割到词向量表示,场景图形生成(SGG)成为一项建立在众多研究成果之上的复杂任务。在本文中,我们重点讨论这个模型的最后一个模块:融合功能。后者的作用是结合三种隐藏状态。我们进行了一个消融测试,以比较不同的实现方式。首先,我们重现了最先进的使用SUM和GATE函数的结果。然后,我们通过添加更多的模型诊断功能来扩展原始解决方案:一个适应的DIST版本和一个MFB和GATE的混合物。在最先进的配置的基础上,DIST表现出最好的召回率@K,这使得它现在成为最先进的一部分。
1 INTRODUCTION AND MOTIVATION
让我们把图1作为输入的基本例子,图2作为模型预测的例子。一个SGG模型的工作流程如下:首先,检测图像中的物体(例如使用预先训练好的神经网)。同时,定义它们各自的边界框。其次,该模型提取连接每一对物体的谓词。为此,该模型依赖于物体标签、代表每个物体的两个隐藏状态以及代表两个物体之间的联合体的一个隐藏状态。第三,通过应用总直接效应(TDE)来消除语言中的偏差,后面会解释。
促使我们研究融合函数的原因是,最近发表了最先进的SGG模型[13].而改进融合函数的工作仍有待进行。
在这项研究中,我们研究了用于合并所有获得的隐藏状态的融合函数。首先,我们重现了用SUM和GATE函数得出的最先进的结果。然后,我们引入了受视觉问题回答领域启发的新函数。这使我们能够确定最重要的规则,以获得最佳的融合函数,从而获得最佳的SGG模型1我们首先在第3节描述SUM和GATE方法。然后,我们在第4节中介绍了新函数,在第6节中介绍了结果,最后在第7节中得出结论。
2 BASELINE SGG
融合函数接收3个隐藏状态作为输入。为了更好地理解融合函数的重要性,让我们在基线神经网络中开始一段漫长的旅程。
Image segmentation
方程式1。第一个模块识别图像中的候选对象标签(𝑙𝑖)和它们各自的边界框(𝑏𝑖)。我们依靠 "Faster RCNN "算法[12],该算法本身相当复杂(ConvNet + Region proposal network + MLP)。
Visual contexts
方程式2。对于每个物体𝑖,初始图像围绕其边界盒𝑏𝑖进行处理。因此,提取的隐藏状态𝑥代表了目标对象。
Object detection
方程3。这个模块从上一个节点获得输入。其目标是识别最终的对象标签{𝑧𝑖}𝑛
Object feature
方程4。从这个模块开始,隐藏状态被成对处理,以便推断出连接它们的谓词。例如,这个模块得到的输入是一对(𝑥𝑖,𝑥𝑗),即两个物体的视觉环境。它输出一个描述连接表示的隐藏状态。它是融合函数的第一个输入。
Object Class
方程5。这个模块只用主语和宾语标签来预测谓语标签。如果对象1是一个人,对象2是一把椅子,连接这两个人的谓词是什么?人们会说 "人1坐在椅子1上 "是最有可能的解决方案,与图像无关。这种推断并不取决于计算机视觉算法,而只是取决于语言中的偏见。这种偏见将在以后使用TDE来消除。
Visual Context
方程6。这个隐藏的状态编码了一个边界框的视觉背景,也就是围绕着两个目标物体的那个边界框。相反,{𝑥𝑖𝑗}并不编码两个物体之间的区域。
Biased predicate prediction
方程7。两个物体之间的关系是通过合并获得的三个隐藏状态来预测的。融合函数被用于这种预测。它们的实现将在后面详述。输出{𝑝𝑖𝑗}是谓词的概率分布。
Final predicate prediction
方程8和9应用了总直率效应(TDE)。这些最后的操作消除了由于语言造成的偏差。通过计算谓词的概率分布𝑝𝑖和𝑝𝑖𝑗| ̄𝑥没有视觉语境下的谓词的概率分布𝑖和𝑥𝑗之间的差异来消除偏差。事实上,如果没有视觉语境,𝑧𝑖和𝑧𝑗将只代表偏见。因此,预测𝑝𝑖𝑗| ̄𝑥将只基于偏见。在实践中,𝑥被替换成̄𝑥,即平均隐藏状态。此外,我们还可以用零来代替它。
。。。
在本节中,我们解释了与融合功能相互作用的算法。3个神经网络提供了该函数的3个输入。之后,TDE在一个数学运算中被计算出来。最后的输出是一组主体-客体-谓词组(𝑧𝑖,𝑝𝑖𝑗TDE,𝑧𝑗)。最后,读者应该知道,上述框架并不适用于所有的SGG。例如,有些是基于注意力模型[1]的,如[8, 16]。
3 BACKGROUND
从物体检测到图像说明,机器学习和计算机视觉证明了它们在解决完整任务方面的独特潜力。在这项研究中,我们处理了一个更加人性化的任务:场景图的生成,这是一个当今非常流行的任务[3,9,13,18]。SGG是一个多模态的框架。本文的重点是最后的融合功能,因为它被证明对SGG相关任务的性能影响很大[16]。
本研究中使用的基线SGG模型是由Tang等人[13]在2020年3月实施的,因为它代表了最新的先进配置。后者的研究已经测试了两个融合函数SUM和GATE,如公式10和公式11所述:
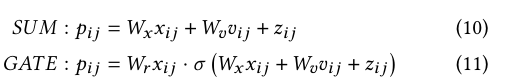
SUM是基于总和操作和线性投影(乘以系数矩阵)。GATE使用与SUM相同的术语,并使用Sigmoid函数对其进行处理。GATE还应用了adot乘积,它是两个项之间的明智的乘法。这个算子在其他论文中也被称为Hadamard算子[11])。) 主要来说,SUM和GATE在SGG模型中非常流行[8, 11, 13, 21] 。
改进融合函数的一个方法是增加一个衡量投影之间差异的项。例如,我们可以使用两个隐藏状态之间的平方欧几里得距离[20]。我们把这个融合函数称为DIST,它在数学上的形式化为方程12。一个更先进的方法实现了多模态因子双线性集合(MFB)[16]。与前一种方法相比,MFB是唯一的融合函数,它在使用总和集合之前扩展了维数。这种方法涉及到更多的权重和对连接每个输入点的共同关注模式的彻底学习。公式13总结了MFB的实施。MFB模块的级联被命名为多模态因子高阶池化(MFH)[17]。这个MFB的扩展显示了更好的结果。最后,后三种方法的目标是视觉问题回答(VQA)。因此,所有函数都只有两个输入:问题和图像。
4 METHODS
除了现有的融合函数–SUM和GATE之外,我们还提出了受[20]启发的DIST函数的修改版本。方程14代表我们的实现。请注意,主要区别在于输入的数量:我们的实现强调𝑥𝑖𝑗(主体𝑖和客体𝑗的联合特征表示)和𝑣𝑖𝑗(视觉环境)之间的区别。从理论上讲,从𝑥𝑖𝑗或𝑗𝑖𝑗中减去𝑧𝑖𝑗的效率较低,因为𝑧𝑖𝑗是从物体类别中推断出来的,而其他两种状态则是从图像中推断的。
此外,我们提出另一个融合函数。它是MFB和GATE的组合,如公式15所示。第一项代表MFB的共同关注模块。它也使用𝑥𝑖𝑗和𝑣𝑖𝑗,如DIST。第二个项代表了融合函数的核心,因为它合并了三个隐藏状态。最后,lement-wise dot product代表在背景中看到的GATE函数。
5 EXPERIMENTS
5.1 Experimental setup
所用的SGG模型是建立在许多其他模块之上的,有自己的参数集。表1浓缩了最重要的参数,以便重现结果。2将任务指定为 "预置分类 "意味着模型将获得地面真实物体标签和边界框作为额外的输入。请注意,批量大小比原始论文中的要高,这可能解释了为什么结果略有改善。关于最大的迭代次数,请注意,训练是用早期停止法监控的。因此,训练通常会在达到这个阈值之前停止。
该实现是用Pytorch进行的,它与并行计算兼容。因此,批次分布在8个RTX 2080 ti型的GPU上。每个GPU的批量大小为8个。分布式计算使我们能够在7到10小时内完成模型的训练。
5.2 Dataset
所用的数据集在2017年以VisualGenome(VG)的名义发布[5]。该数据集包括超过10万张图像。平均每张图片有18个谓词,VG是SGG的最密集和最大的数据集。当然,我们可以考虑MS-COCO[6],它有30万张带标题的图像。但是,每张图片有五个标题的格式并不适合谓词分类任务。然而,这个数据集的格式适合句子到图形的检索任务。对于图像的预处理,我们遵循与基线实现[13]相同的步骤:将每张图像的最长一面缩放为1000像素。
关于VG数据集,我们必须关注的主要问题是对象和谓语类别的不平衡。事实上,{on, has, wearing, of, in}是最频繁的五个谓语。它们几乎占了所使用的谓词的75%。由于这个原因,许多研究,如[2,13-15,18],将基础真理图限制在150个最频繁的对象和50个最频繁的谓词上。
5.3 Metrics
SGG是一项复杂的任务。每个提议的解决方案都有其自身的优点和缺点。希望我们能用以下的指标来衡量不同的优势
5.3.1 mAP.
mAP只评估物体检测和精确地评估边界框的质量。在这项研究工作中,我们将实验限制在谓词检测上,即物体标签和边界框是输入的一部分。因此,这个指标是不相关的。
…
还可以探索许多其他的指标–比如每个谓词的Recall@K、Zero-Shot Recall@K(zR@K)[7]和Sentence-to-Graph Retrieval(S2G)[13]–但这些指标与本文不太相关。总之,每个指标都评估了SGG工作流程中的一个具体步骤,使我们能够确定每个模型的优点和缺点。
6 RESULTS AND DISCUSSION
图3显示了使用所有5个指标的每个融合函数的性能。首先,我们注意到再现的结果(SUM和GATE)与源文件[13]中的报告略有不同。这主要是由两个原因造成的:如上所述,批量大小的增加,以及作者在发表源论文后报告的实施优化。
根据真实的文字应用,人们可以选择能更好地描述最终目标的指标。DIST在R@K和ngR@K上表现最好。SUM,最简单的函数,在zR@K上表现最好。最后,MFB和GATE的混合物获得了最好的A@K。
这项研究有潜在的局限性。首先,我们没有提供任何关于结果的统计数据(分数的平均值和标准差)。这是由于训练时间太长:我们每次运行和每个融合函数需要大约7到10小时的训练。第二,我们使用了一些预训练的组件,如Faster R-CNN,以加速训练。在每次运行过程中对模型进行端对端训练,以获得对融合函数影响的更准确的测量,这将是更可靠的。第三,我们提供了物体类别和边界框作为模型的输入。因此,这项工作集中在一个特定的任务上:谓词分类
7 CONCLUSIONS
我们研究了使用TDE的SGG问题。TDE操作需要计算特定的隐藏状态。因此,有必要实现一个融合函数,负责合并三个隐藏状态的流动。我们复制了SUM和GATE函数的结果。然后,我们调整了VQA领域的DIST融合函数。得到的模型达到了最佳的Recall @ K和ng-Recall @ Kscore。最后,我们在MFB和GATE函数之间建立了一个混合模型。总而言之,根据SGG模型的最终应用,每个测试的融合函数都表现得更好。
未来,我们希望证明DIST在类似的任务上也能取得最先进的结果,如场景图分类和场景图检测。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









