









1、表之间的关系
一对一
一夫一妻
一对多
一个人可以拥有多辆汽车
创建person表
CREATE TABLE person(id int PRIMARY KEY auto_increment,name VARCHAR(50));
创建car表
CREATE TABLE car ( cid INT PRIMARY KEY ,
cname VARCHAR ( 50 ),
color VARCHAR(25),
pid INT,
CONSTRAINT c_p_fk FOREIGN key(pid) REFERENCES person(id)
);
多对多
一个老师可以对应多个学生,一个学生也可以对应多个老师
创建老师表
CREATE TABLE teacher(
tid int PRIMARY KEY auto_increment,
name VARCHAR(50),
age int,
gender char(1) DEFAULT '男');
创建学生表
CREATE TABLE student(
sid int PRIMARY KEY auto_increment,
name VARCHAR(50)not null,
age int,
gender char(1) DEFAULT '男');
创建学生与老师的关系表
CREATE TABLE tea_stu_rel(
tid int,
sid int);
添加外键
将tid与老师表关联,sid与学生表关联
ALTER TABLE tea_stu_rel
add CONSTRAINT fk_tid FOREIGN key(tid) REFERENCES teacher(tid);
ALTER TABLE tea_stu_rel add CONSTRAINT fk_sid FOREIGN key(sid)
REFERENCES student(sid);
创建学生分数表
CREATE TABLE score (
id int(8) auto_increment PRIMARY key,
socre int(8),km VARCHAR(50),sid int(8)
);
为什么要拆分表?
- 避免大量冗余数据的出现
2、多表查询
合并结果集
合并结果集就是把两个select语句的查询结果合并到一起
合并结果集的两种方式
- UNION:合并时去除重复记录
- UNION ALL:合并时不去除重复记录
SELECT * FROM表1 UNION SELECT *FROM 表2;
SELECT * FROM表1 UNION ALL SELECT* FROM 表2;
注意事项
被合并的两个结果:列数、列类型必须相同。
示例

3、连接查询
什么是连接查询?
也可以叫跨表查询,需要关联多个表进行查询
3.1、笛卡尔集
什么是笛卡尔集?
- 假设集合A={a,b},集合B={0,1,2}
则两个集合的笛卡尔积为{(a,0),(a,1),(a.2),(b,0),(b,1),(b,2)}。
可以扩展到多个集合的情况 - 同时查询两张表,出现的就是笛卡尔集结果
SELECT * FROM teacher,student;
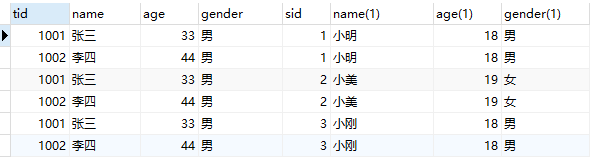
去除笛卡尔集
在查询时要把主键和外键保持一致
SELECT * FROM student st,score sc where st.sid=sc.sid;
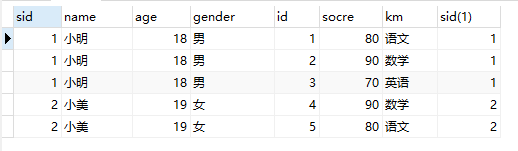
主表当中的数据参照子表当中的数据
其原理是逐行判断,相等的留下,不相等的全不要
3.2、根据连接方式分类查询
3.2.1、内连接
等值连接
-- INNER 可以省略不写
SELECT * FROM student st INNER JOIN score sc on st.sid = sc.sid;
- 两个表同时出现的id号(值)才显示
- 与多表联查约束主外键是一样,只是写法改变了
- ON后面只写主外键
- 如果还有条件直接在后面写where
- 多表联查后面还有条件就直接写and
多表连接
建立科目表并插入一些数据
CREATE TABLE course(cid int PRIMARY KEY,name VARCHAR(50));
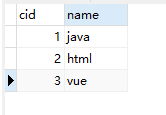
使用99连接法
SELECT st.name,sc.socre,c.`name` FROM student st,score sc,course c
where st.sid=sc.sid and sc.sid=c.cid;
使用内联查询
SELECT st.`name`,sc.socre,c.`name` FROM student st
JOIN score sc on st.sid=sc.sid
JOIN course c on sc.sid=c.cid;
非等值连接
先准备几张表
员工表
CREATE TABLE `emp` (
`empno` int(11) NOT NULL,
`ename` varchar(255) DEFAULT NULL,
`job` varchar(255) DEFAULT NULL,
`mgr` varchar(255) DEFAULT NULL,
`hiredate` date DEFAULT NULL,
`salary` decimal(10,0) DEFAULT NULL,
`comm` double DEFAULT NULL,
`deptno` int(11) DEFAULT NULL,
PRIMARY KEY (`empno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
薪资级别表(800在第一级)
CREATE TABLE `salgrade` (
`grade` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '工资等级',
`lowSalary` int(11) DEFAULT NULL COMMENT '此等级的最低工资',
`highSalary` int(11) DEFAULT NULL COMMENT '此等级的最高工资',
PRIMARY KEY (`grade`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
部门表
CREATE TABLE `dept` (
`deptno` bigint(2) NOT NULL AUTO_INCREMENT COMMENT '表示部门编号,由两位数字所组成',
`dname` varchar(14) DEFAULT NULL COMMENT '部门名称,最多由14个字符所组成',
`local` varchar(13) DEFAULT NULL COMMENT '部门所在的位置',
PRIMARY KEY (`deptno`)
) ENGINE=InnoDB AUTO_INCREMENT=41 DEFAULT CHARSET=utf8;
插入数据
INSERT INTO `emp` VALUES (7369, '孙悟空', '职员', '7902', '2010-12-17', 800, NULL, 20);
INSERT INTO `emp` VALUES (7499, '孙尚香', '销售人员', '7698', '2011-2-20', 1600, 300, 30);
INSERT INTO `emp` VALUES (7521, '李白', '销售人员', '7698', '2011-2-22', 1250, 500, 30);
INSERT INTO `emp` VALUES (7566, '程咬金', '经理', '7839', '2011-4-2', 2975, NULL, 20);
INSERT INTO `emp` VALUES (7654, '妲己', '销售人员', '7698', '2011-9-28', 1250, 1400, 30);
INSERT INTO `emp` VALUES (7698, '兰陵王', '经理', '7839', '2011-5-1', 2854, NULL, 30);
INSERT INTO `emp` VALUES (7782, '虞姬', '经理', '7839', '2011-6-9', 2450, NULL, 10);
INSERT INTO `emp` VALUES (7788, '项羽', '检查员', '7566', '2017-4-19', 3000, NULL, 20);
INSERT INTO `emp` VALUES (7839, '张飞', '总裁', NULL, '2010-6-12', 5000, NULL, 10);
INSERT INTO `emp` VALUES (7844, '蔡文姬', '销售人员', '7698', '2011-9-8', 1500, 0, 30);
INSERT INTO `emp` VALUES (7876, '阿珂', '职员', '7788', '2017-5-23', 1100, NULL, 20);
INSERT INTO `emp` VALUES (7900, '刘备', '职员', '7698', '2011-12-3', 950, NULL, 30);
INSERT INTO `emp` VALUES (7902, '诸葛亮', '检查员', '7566', '2011-12-3', 3000, NULL, 20);
INSERT INTO `emp` VALUES (7934, '鲁班', '职员', '7782', '2012-1-23', 1300, NULL, 10);
INSERT INTO `dept` VALUES (10, '财务部', '北京');
INSERT INTO `dept` VALUES (20, '调研部', '上海');
INSERT INTO `dept` VALUES (30, '销售部', '王者峡谷');
INSERT INTO `dept` VALUES (40, '运营部', '腾讯大楼');
INSERT INTO `salgrade` VALUES (1, 700, 1200);
INSERT INTO `salgrade` VALUES (2, 1201, 1400);
INSERT INTO `salgrade` VALUES (3, 1401, 2000);
INSERT INTO `salgrade` VALUES (4, 2001, 3000);
INSERT INTO `salgrade` VALUES (5, 3001, 9999);
示例:查询所有员工的姓名,工资,所在部门的名称以及工资的等级
解题思路:分为三步
- 查询所有员工的姓名,工资

- 查询所有员工的姓名,工资和所有部门

- 查询所有员工的姓名,工资和所在部门及

3.2.2、外连接
左外连接(左连接)
- 左连接会把左表当中的数据全部查出,右表当中只查出满足条件的数据
- 比如左表是学生表,有表是分数表,若有学生缺考,使用内连接则只会查询除有分数的学生,使用外连接则可以将缺考的学生也查出。
- 查询时,两个表可以不需要建立外键约束
关键字:LEFT JOING
-- OUTER 可以省略不写
SELECT * FROM student st LEFT OUTER JOIN score sc on st.sid = sc.sid;
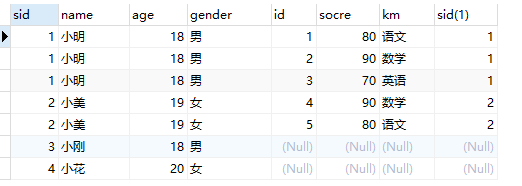
右外连接(右连接)
- 右连接会把右当中的数据全部查出,左表当中只查出满足条件的数据
- 站在表的角度去看,使用左连接就把左边表当中的内容全部查出,右边查出满足条件的。使用右连接,就把右边表当中的数据全部查出。左边查出满足条件的。
3.2.3、自然连接
- 连接查询会产生无用笛卡尔集,我们通常使用主外键关系等式来去除它
- 而自然连接无需你去给出主外键等式,它会自动找到这一等式,也就是说不用去写条件
要求:
- 两张连接的表中列名称和类型完全一致的列作为条件
- 会去除相同的列
示例:查询学生表与分数表所有信息
-- 原本我们需要这样写
SELECT * from student,score WHERE student.sid=score.sid;
可以发现查询结果有两个sid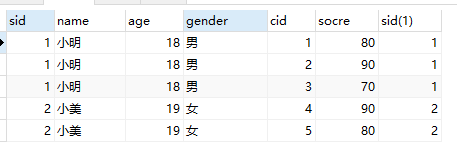
-- 自然连接只需要这样写
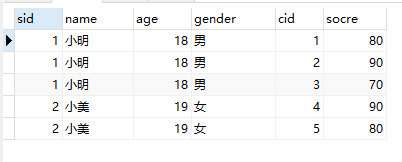
SELECT * FROM student NATURAL JOIN score;
自然连接去掉了重复列
4、子查询
4.1、定义
什么是子查询?
一个select语句中包含另一个完整的select语句或两个以上SELECT,那么就是子查询语句了。
子查询出现的位置
- 若出现在where后,把select查询出的结果当作另一个select的条件值
- 若出现在from后,把查询出的结果当作一个新表;
4.2、使用
示例表

具体创建SQL语句点击连接里面有:https://blog.csdn.net/weixin_44894962/article/details/121754614
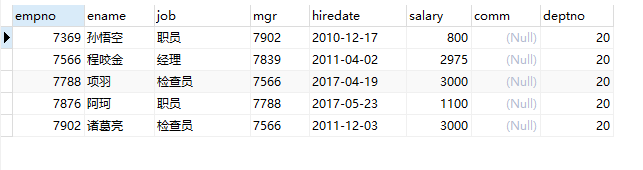
- 查询与项羽同一个部门人员工
-- 先查出项羽所在的部门编号
SELECT deptno from emp where ename='项羽'
-- 再根据编号查同一部门的员工
SELECT * FROM emp where deptno=(SELECT deptno from emp where ename='项羽');
查询结果
- 查询工资高于程咬金的员工
-- 先查出程咬金的工资
SELECT salary FROM emp where ename='程咬金';
-- 再去根据查出的结果查询出大于该值的记录员工名称
SELECT ename FROM emp WHERE salary>(SELECT salary FROM emp where ename='程咬金');
查询结果
3. 工资高于30号部门所有人的员工信息
-- 先查出30号部门工资最高的那个人
SELECT MAX(salary) FROM emp where deptno=30;
-- 再到整个表中查询大于30号部门工资最高的人
SELECT ename,salary FROM emp
WHERE salary>(SELECT MAX(salary) FROM emp where deptno=30);
- 查询工作和工资与妲己完全相同的员工信息
-- 先查出妲已的工作和工资
SELECT job,salary FROM emp where ename='妲己';
-- 根据查询结果当作条件再去查询工作和工资相同的员工
-- 由于是两个条件,使用 IN进行判断
SELECT ename,job FROM emp WHERE
(job,salary) in
(SELECT job,salary FROM emp where ename='妲己');
- 有2个以上直接下属的员工信息
-- 对所有的上级编号进行分组
SELECT mgr,GROUP_CONCAT(mgr) FROM emp GROUP BY mgr;
-- 找出大于2个的,大于2个说明有两个下属
SELECT mgr,GROUP_CONCAT(mgr) FROM emp GROUP BY mgr HAVING COUNT(*)>=2;
-- 把上条的结果当作员工编号时行查询
SELECT ename FROM emp WHERE empno in(
SELECT mgr FROM emp GROUP BY mgr
HAVING COUNT(*)>=2);
5、自连接
求7369员工编号、姓名、经理编号和经理姓名
SELECT * FROM emp
WHERE empno= (SELECT mgr FROM emp WHERE empno=7369);
以上这种方法只能查询出一个经理的名称
自连接:自己连接自己,起别名
SELECT * FROM emp e1,emp e2 WHERE e1.mgr=e2.empno and e1.empno=7369;















 9104
9104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









