







目录
- 下载解压hadoop安装包
- 修改配置文件
- 格式化namenode
- 启动hdfs
- 查看是否启动成功
下载解压hadoop安装包
- 登录hadoop官网下载:Hadoop官网(http://hadoop.apache.org)
- 将下载下来的安装包上传到linux虚拟机(服务器),用tar -zxvf 命令解压安装
修改配置文件
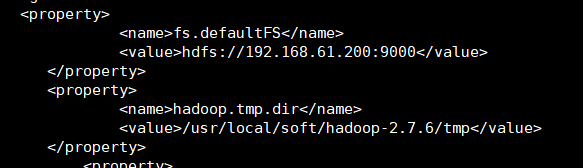
修改配置文件 core-site.xml,hdfs-site.xml,slaves,hadoop-env.sh。hadoop-env.sh配置的是JAVA_HOME,core-site.xml配置的是fs.defaultFS(hdfs访问地址)和hadoop.tem.dir(namenode和datanode工作时存放相关数据的目录)。hdfs-site.xml设置的dfs.namenode.secondary.http-address(secondaryNamenode的搭载节点地址),slaves设置的是dataNode的节点名称。

格式化nameNode
格式化命令:hadoop nameNode -format
格式化原因:生成tmp目录,本质是tmp/dfs/name/current目录下的以下四个文件(
-rw-r–r--. 1 root root 321 1月 1 16:40 fsimage_0000000000000000000(镜像文件)
-rw-r–r--. 1 root root 62 1月 1 16:40 fsimage_0000000000000000000.md5(校验文件,检查镜像文件是否被修改)
-rw-r–r--. 1 root root 2 1月 1 16:40 seen_txid
-rw-r–r--. 1 root root 207 1月 1 16:40 VERSION(包含集群id等信息)
)
启动hdfs
- 手动一个个启动–> hadoop-demon.sh start nameNode 和hadoop-demon.sh start detaNode
- 脚本启动–>start-dfs.sh(前提将sbin路径追加到环境变量里)
查看结果
jps命令,如果主节点出现 NameNode和ScondaryNameNode,从节点出现dataNode
问题分析
如果只有nameNode启动,dataNode没有启动–>解决方法:关闭集群,删除各个节点tmp文件下的所有内容,再格式化namenode,然后重新启动。
















 4106
4106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











