






结构体
1、匿名结构体
2、结构体指针
3、结构体类型重命名
*4、结构体内存对齐
匿名结构体
匿名结构体就是在创建结构体的时候没有给予结构体命名
struct {
int a;
char b;
}x;
这样的结构体,我们称为匿名结构体,匿名结构体在使用时只可以使用一次。
结构体指针
数据结构中经常用到定义和本身结构体命名相同的结构体指针
struct Node{
int data;
struct Node* next;
};
next是类型为(struct Node*)的结构体指针,为什么要这么命名呢,就好像函数的递归一样,函数的递归是调用函数自身,那么在结构体这里就是指向结构体内部类型一样的结构体,这里我用画图表示。

在主函数中创建结构体指针的用法
struct stu{
char name[20];
int age;
};
int main(){
struct stu *p=NULL;
struct stu s;
p=&s;
}把创建的结构体地址赋值给结构体指针p,结构体指针只能指向结构体
下面是如何使用结构体指针的方法
int main(){
struct stu *p=NULL;
struct stu s;
p=&s;
char arr[20]={"zhangsan"};
strcpy(p->name,arr);
printf("%s\n",p->name);
p->age=10;
printf("%d",p->age);
}其中的p->name也可以替换成(*p).name
这里也顺便区分一下' -> '和' . '
这里我们暂且使用上面的结构体:struct stu
创建结构体:struct stu s;
创建结构体指针:struct stu *p=NULL;
使用结构体时通常都是s.name || s.age
但是使用结构体指针时是p->name || p->age || (*p).name || (*p).age
结构体类型重命名(typedef)
typedef struct student{
char name[20];
int age;
}stu;这里我们创建一个结构体,且使用typedef
那么在主函数中使用有什么区别呢
int main(){
student stu;
stu.age=10;
printf("%d",stu.age);
}创建结构体时就不要在前面加上struct了
就可以看成是stu把struct student给替换了
结构体内存对齐
结构体内存对齐就是结构体在内存中的存储方式
特点:浪费了一定的空间,但是提升了读取效率。
首先我给出一个结构体
struct s1{
double a;
char b;
int c;
};在不考虑系统默认对齐数的情况下
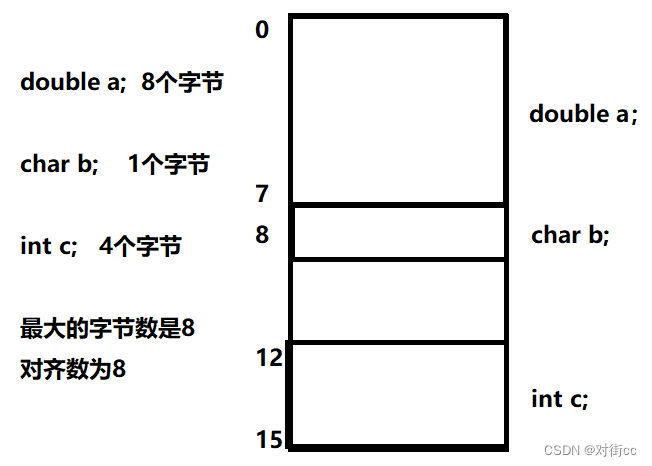
double类型数据占8个字节,占据的空间必须是8的倍数的地址空间,比如0~7、 8~15、16~23
char类型数据大小为1个字节,所以可以任意存放
int类型数据4个字节,必要要存放在4的倍数的地址空间只能存在12~15
所以该结构体大小是16字节
对齐数
对齐数是结构体内存对齐的重要内容,直接影响到结构体的大小
Visual Studio的对齐数默认是8。
没有默认对齐数时取结构体中数据类型最大的:double类型: 8字节 long long: 8字节
结构体的大小必须是对齐数的整数倍。
这里我们简单举一个例子

从上图中我们截取一部分,如果内存对齐数改为4,那么该结构体的大小是12字节
如果对齐数是8,结构体的大小依旧是16。
#pragma pack(4)加入该代码可以修改系统的默认对齐数。
位段
位段的成员名后面必须有一个冒号和数字
数字代表该成员所占的bit位
struct A{
int a:2; //占2个bit位
int b:5; //占5个bit位
int c:10; //占10个bit位
};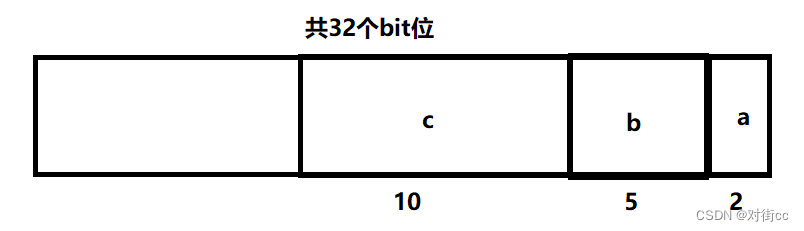
该位段的大小为17个bit位
由于是int类型,开辟空间时开辟了4个字节(32个bit位)
上图是位段成员在内存中的存放方式
下面我们分析这样一个位段:
struct _Record_Struct
{
unsigned char Env_Alarm_ID : 4;
unsigned char Para1 : 2;
unsigned char state;
unsigned char avail : 1;
};unsigned char是大小为一个字节的无符号字符型

该位段占据了3个字节大小的空间
因为state后面没有加上冒号和数字,所以state就是unsigned char类型的成员变量,大小一个字节
且在空间分隔了两个位段空间。
枚举(enum)
枚举简单易懂,看两段代码就能理解
enum S1{
exit,
add,
sub,
mul,
div,
sort
};#define exit 0
#define add 1
#define sub 2
#define mul 3
#define div 4
#define sort 5枚举中的第一个数子默认从0开始,然后不断加1
当其中有一个变量被赋值成其他值时
enum S1{
exit,
add,
sub,
mul=10,
div,
sort
};用define来解释通俗易懂
#define exit 0
#define add 1
#define sub 2
#define mul 10
#define div 11
#define sort 12mul别赋值为10,那么mul下面的变量就在10的基础上+1
*联合体(union)
联合体的大小取决于联合体内成员变量中最大的那个
union un {
int a;
char b;
};这样一个联合体,他的大小取决于int类型的变量;
因为在联合体中,a和b公用一块空间
#include<stdio.h>
union un {
int a;
char b;
};
int main() {
union un n;
printf("%p\n", &(n.b));
printf("%p\n", &(n.a));
n.b = 'a';
printf("%c\n", n.b);
printf("%c\n", n.a);
n.a = 20;
printf("%d\n", n.b);
printf("%d\n", n.a);
}这时候打开调试,我们看一看内存中的变化。
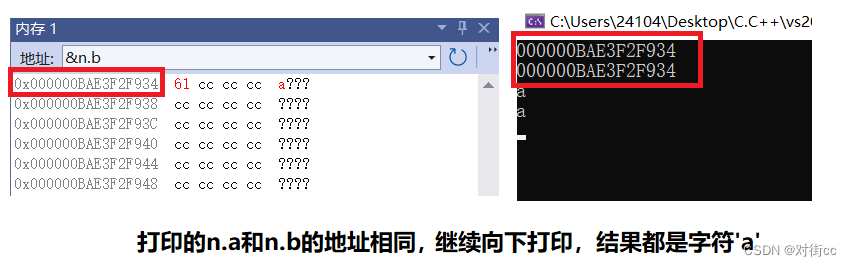
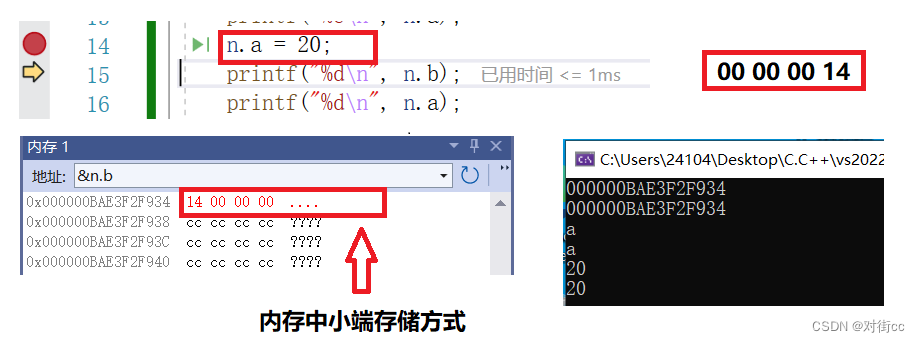
运行这一段代码的时候会发现,为什么n.a和n.b不但地址相同,而且改变其中一个,另一个也会随之改变。这已经说明了a和b公用一块空间,且同一时间,只能使用其中一个。
那么char和int的区别在哪??
假如我把整数改成500会发生变化吗???
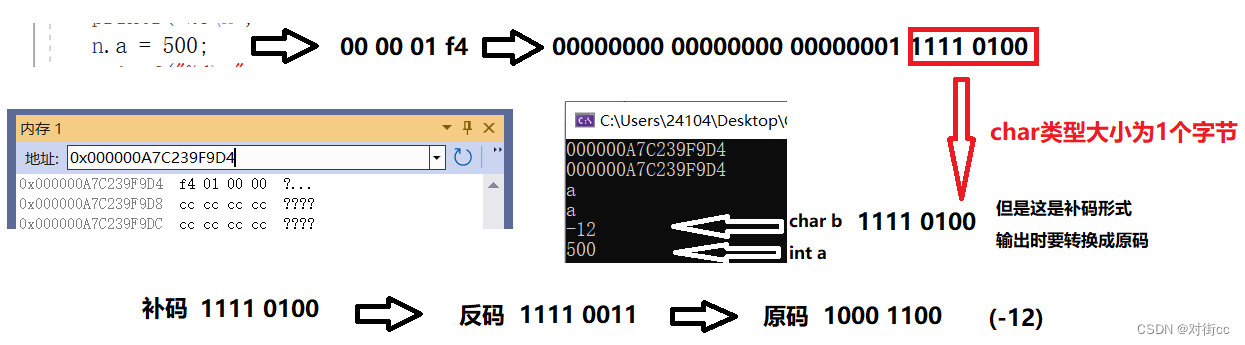
很仔细了解释了 为什么输入500时,输出的结果有那么大的差异
首先一个字节有符号数的大小为(-128~127)
当超过这个值时,一个字节已经无法放下他,但是取值时我们仍然只能取8个bit位。
这是用1个字节存4个字节整数的问题。















 3704
3704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









