






数据集链接CHB-MIT Scalp EEG Database v1.0.0
如何将edf文件中的数据提取出来请参考大佬文章CHB-MIT波士顿儿童医院癫痫EEG脑电数据处理(一)_arbitrary19的博客-CSDN博客
将数据提取出来后,数据是一个[23,921600]的数组(23通道,3600秒,256Hz采样频率)。在数据集中,癫痫发作的时间是在每一个被试者的summary.txt中展示的,如下图
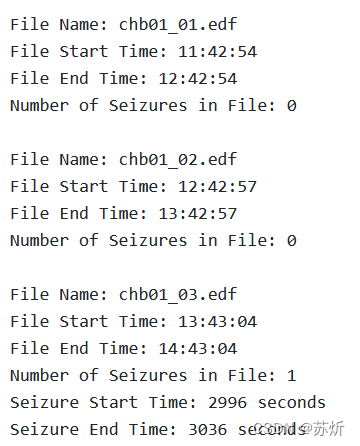
故需要将癫痫对应的时间片截取出来,函数如下:
def generate_data_label(summary_txt_filename):
with open(summary_txt_filename) as f:
summary_txt=f.read()
pattern_string="File Name: .+\nFile Start Time: .+\n.+\n.+\nSeizure Start Time: \d{1,4} seconds\nSeizure End Time: \d{1,4} seconds"
# pattern=re.compile(pattern1_string)
string_list=pattern1.findall(summary_txt)
result={}
for index, item in enumerate(string_list):
file_pattern = re.compile("File Name: (chb\d{2}\w?_\d{2}\+?\.edf)\n")
time_pattern = re.compile(
"Seizure \d? ?Start Time: (\d{1,5}) seconds\nSeizure \d? ?End Time: (\d{1,5}) seconds\n?")
file_name = re.findall(file_pattern, item[0])
file_name=file_name[0]
times = re.findall(time_pattern, item[0])
for t in times:
start_time = int(t[0])
end_time = int(t[1])
if file_name in result.keys():
result[file_name].append((start_time,end_time))
else:
result[file_name]=[(start_time,end_time)]
return result通过正则表达式提取出对应的文件名,开始发作时间,结束发作时间。
测试代码如下:
result=generate_data_label("chb16\\chb16-summary.txt")
for (k,v) in result.items():
print("文件名为{},对应时间列表为{}".format(k,v))结果如图(文件名:chb16-summary.txt):

需要注意的是 在该数据集的summary文件中,存在着大量的bug....比如某些文件在某些地方会多一个空格,有些地方是23通道,有些地方是22/24/28通道,没什么规律,但出现这些情况的文件不多,我也就懒得专门弄了,有兴趣的可以自己搞一下。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









