







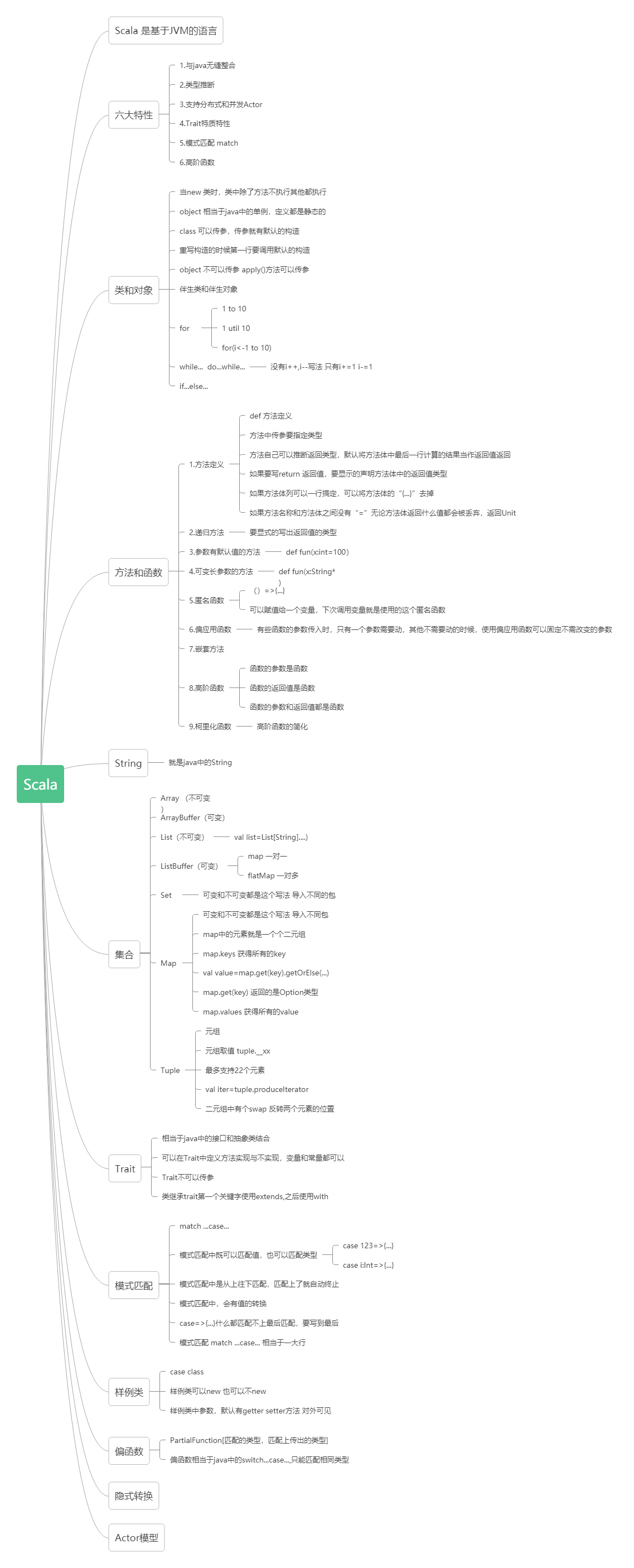
思维导图
学习目标
1.能够安装上scala必备的开发工具IDEA
2.了解学习scala的必要性
3.了解函数式编程的特点
4.掌握scala编程基础
Scala介绍
-
Scala是一种针对JVM 将面向函数和面向对象技术组合在一起的编程语言。Scala编程语言近来抓住了很多开发者的眼球。它看起来像是一种纯粹的面向对象编程语言,而又无缝地结合了命令式和函数式的编程风格。Scala融汇了许多前所未有的特性,让开发者能够很好的而同时又运行于JVM之上。随着大数据的日益发展,scala必定会成为必不可少的开发语言。
-
Spark1.6中使用的是Scala2.10。Spark2.0版本以上使用是Scala2.11版本。
Scala官网6个特征。

1.Java和scala可以混编
Java里面可以调用scala包,scala里面也可以调用java包
2.类型推测(自动推测类型) 定义类型只能使用val和var
3.并发和分布式 actor:支持并发和分布式
4.特质,特征(类似java中interfaces 和 abstract结合)
5.模式匹配(类似java switch)
6.高阶函数

1.Scala安装使用
1.1 windows安装,配置环境变量
首先安装jdk,推荐1.8版本
下载scala-2.11.8.msi文件解压安装即可
新建SCALA_HOME

- 上个步骤完成后,编辑Path变量,在后面追加如下:
;%SCALA_HOME%\bin;%SCALA_HOME%\jre\bin
- 打开cmd,输入:scala - version 看是否显示版本号,确定是否安装成功

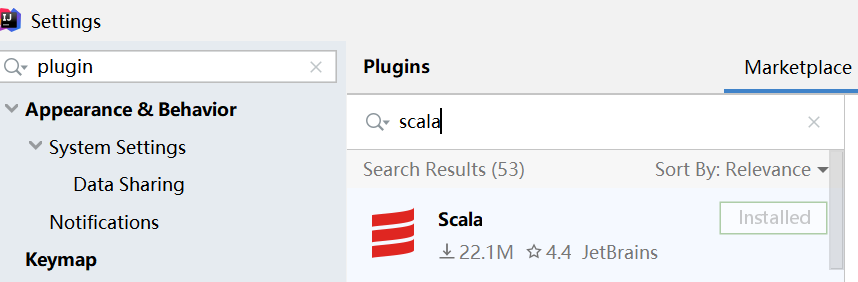
1.2 idea 中配置scala插件
- 打开idea,close项目后,点击Configure->Plugins
-
搜索scala,点击Install安装
-
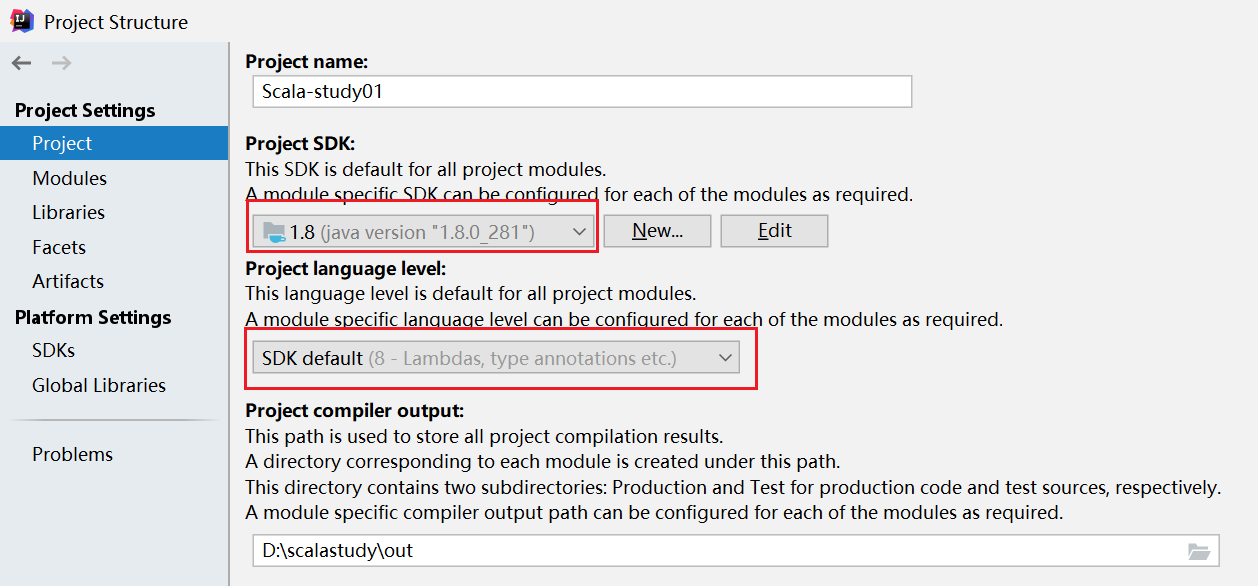
设置jdk,打开Project Structure,点击new 选择安装好的jdk路径
注意:最好将这几个位置的jdk设置的相同,否则可能会报错


-
创建scala项目,配置scala sdk(Software Development Kit)



点击第三步,弹出选择SDK,点击Browse选择本地安装的Scala目录。选择system.
2.Scala基础
2.1 数据类型




2.2变量和常量的声明
-
定义变量或者常量的时候,也可以写上返回的类型,一般省略,如:val a:Int = 10
-
常量不可再赋值
/** * 定义变量和常量 * 变量 :用 var 定义 ,可修改 * 常量 :用 val 定义,不可修改 */ var name = "zhangsan" println(name) name ="lisi" println(name) val gender = "m" // gender = "g" 错误,不能给常量再赋值注意:scala有个原则就是极简原则,不用写的东西一概不写。
定义变量有两种形式
一种是像上面那样用val修饰另一种是var进行修饰
val 定义的变量不可变相当与java中的final
用表达式进行赋值
Val x=1 Val y=if(1>0) 1 else -1混和表达式
Val a =if (x>0) 1 else “jay”需要注意的是any是所有的父类,相当于java里的object
else缺失的表达式
val p=if (x>5) 1
2.3 类和对象
- 创建类
class Person{
val name = "zhangsan"
val age = 18
def sayName() = {
"my name is "+ name
}
}
- 创建对象
object Lesson_Class {
def main(args: Array[String]): Unit = {
val person = new Person()
println(person.age);
println(person.sayName())
}
}
- 对象中的apply方法
object中不可以传参,当创建一个object时,如果传入参数,那么会自动寻找object中的相应参数个数的apply方法。
/**
* object 单例对象中不可以传参,
* 如果在创建Object时传入参数,那么会自动根据参数的个数去Object中寻找相应的apply方法
*/
object Lesson_ObjectWithParam {
def apply(s:String) = {
println("name is "+s)
}
def apply(s:String,age:Int) = {
println("name is "+s+",age = "+age)
}
def main(args: Array[String]): Unit = {
Lesson_ObjectWithParam("zhangsang")
Lesson_ObjectWithParam("lisi",18)
}
- 伴生类和伴生对象
class Person(xname :String , xage :Int){
var name = Person.name
val age = xage
var gender = "m"
def this(name:String,age:Int,g:String){
this(name,age)
gender = g
}
def sayName() = {
"my name is "+ name
}
}
object Person {
val name = "zhangsanfeng"
def main(args: Array[String]): Unit = {
val person = new Person("wagnwu",10,"f")
println(person.age);
println(person.sayName())
println(person.gender)
}
}
注意点:
建议类名首字母大写 ,方法首字母小写,类和方法命名建议符合驼峰命名法。
scala 中的object是单例对象,相当于java中的工具类,可以看成是定义静态的方法的类。object不可以传参数。另:Trait不可以传参数
scala中的class类默认可以传参数,默认的传参数就是默认的构造函数。
重写构造函数的时候,必须要调用默认的构造函数。
class 类属性自带getter ,setter方法。
使用object时,不用new,使用class时要new ,并且new的时候,class中除了方法不执行(不包括构造),其他都执行。
如果在同一个文件中,object对象和class类的名称相同,则这个对象就是这个类的伴生对象,这个类就是这个对象的伴生类。可以互相访问私有变量。
2.4 This
主构造器–辅助构造器–私有构造器
辅助构造器(Auxiliary Constructor)
- 辅助构造器的名称为this
- 每个辅助构造器都必须以一个对先前已定义的其他辅助构造器或主构造器的调用开始
class Student {
private var name = " "
private var age = 0
def this(name: String){ //辅助构造器1
this() //调用主构造器
this.name = name
}
def this(name: String,age: Int){ //辅助构造器2
this(name) //调用前一个辅助构造器
this.age = age
}
}
现在有以下三种方式实例化对象:
object Test1 {
def main(args: Array[String]): Unit = {
val s1 = new Student //主构造器
val s2 = new Student("gcc") //辅助构造器1
val s3 = new Student("gss",21) //辅助构造器2
}
}
主构造器(Primary Constructor)
Scala中,每个类都有主构造器,但并不以this定义。
-
主构造器的参数直接放在类名之后
class Student(val name: String,val age: Int){ // 括号中的就是主构造器的参数 ...... } -
只有主构造器的参数才会被编译成字段,其初始化的值为构造时传入的参数。
-
主构造器会执行类定义中的所有语句
class Student (val name: String,val age: Int){ println("Primary constructor and Auxiliary constructor!") def fun()={ println(s"name is $name,age is $age") } } object Lession_this { def main(args: Array[String]): Unit = { val s1 = new Student("gcc",18) val s2 = new Student("gss",20) s1.fun s2.fun } }输出结果为:

说明:
因为println语句是主构造器的一部分,所以在每次实例化的时候,会执行一次println。
然后fun函数被调用2次,就执行两次fun函数的内容 -
在主构造器中使用默认参数,可防止辅助构造器使用过多
class Student(val name:String="",val age: Int = 0) -
如果不带val或var的参数至少被一个方法使用,它将升格为字段
class Dog(name:String, color:String){ def fun = name + " is " + color + " Dog!" }上述代码声明并初始化了不可变字段name和color,并且这两个字段都是对象私有的。也就是说,类的方法,只能访问到当前对象的字段。
私有构造器(Private Constructor)
想要让主构造器变成私有构造器,只需要加上private关键字即可class Dog private(val age: Int){...}
2.5 if else
val age=20
if(age<=20){
println("age<20")
}else if(age>20&&age<=30){
println("age>20&&age<=30")
}else{
println("age>30")
}
2.6 for ,while,do…while
- to和until:
to:包含右边界
until:不包含右边界例: 1 to 10 返回1到10的Range数组,包含10
1 until 10 返回1到10 Range数组 ,不包含10
to和until 的用法(不带步长,带步长区别)
println(1 to 10 )//打印 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
println(1.to(10))//与上面等价,打印 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
println(1 to (10 ,2))//步长为2,从1开始打印 ,1,3,5,7,9
println(1.to(10, 2))
println(1 until 10 ) //不包含最后一个数,打印 1,2,3,4,5,6,7,8,9
println(1.until(10))//与上面等价
println(1 until (10 ,3 ))//步长为2,从1开始打印,打印1,4,7
在scala中,Range代表的是一段整数的范围,官方有关range的api:
http://www.scala-lang.org/api/current/index.html#scala.collection.immutable.Range
var r = 1 to 10;//赋值1到10的整数
var r = 1.to(10);
for(i <- 0 to 10);
for(i <- 0 until 10);
var r = Range(1,10);
var r = Range(1,10,2);//1到10的整数,步长为2,步长不能为0,默认步长为1
这些底层其实都是Range,Range(1,10,2):1是初始值,10是条件,2是步长,步长也可以为负值,递减。
until和Range是左闭右开,1是包含的,10是不包含。而to是左右都包含。
- 创建for循环
for( i <- 1 to 10 ){
println(i)
}
val arr=Array(“a”,”b”,”c”)
for(i<-arr)
println(i)
- 创建多层for循环(高级for循环)
//可以分号隔开,写入多个list赋值的变量,构成多层for循环
//scala中 不能写count++ count-- 只能写count+
var count = 0;
for(i <- 1 to 10; j <- 1 until 10){
println("i="+ i +", j="+j)
count += 1
}
println(count);
//例子: 打印九九乘法表
for(i<-1 until 10)
{
for(j<-1 to i){
print(s"$i*$j="+i*j+"\t")
}
println()
}
for(i<-1 until 10;j<-1 to i)
{
print(s"$i*$j="+i*j+"\t")
if(i==j)
println()
}
- for循环中可以加条件判断,可以使用分号隔开,也可以不使用分号(使用空格)
//可以在for循环中加入条件判断
for(i<- 1 to 10 ;if (i%2) == 0 ;if (i == 4) ){
println(i)
}
- scala中不能使用count++,count—只能使用count = count+1 ,count += 1
2.7 for循环用yield 关键字返回一个集合
把满足条件的i组成一个集合
val result = for(i <- 1 to 100 if(i>50) if(i%2==0)) yield i
println(result)
-
while循环,while(){},do {}while()
/** * while 循环 */ var index = 0 while(index < 100 ){ println("第"+index+"次while 循环") index += 1 } index = 0 do{ index +=1 println("第"+index+"次do while 循环") }while(index <100 )
2.8 懒加载
当函数返回值被声明为lazy时,函数的执行将被推迟,直到我们首次对此取值,该函 数才会执行。这种函数我们称之为惰性函数,在Java的某些框架代码中称之为懒加载 (延迟加载)。
object Lession_lazy {
def sum(n1:Int,n2:Int): Int = {
println("Sum() is Working")
return n1 + n2
}
def main(args:Array[String]): Unit ={
lazy val res = sum(10,10)
println("-------------------")
println("Res="+res)
}
}
输出结果:

总结:
- Scala:
- 1.Scala object 相当于java中的单例,object中定义的全是静态的 相当于java中的工具类 Object 不能传参 对象要传参 使用apply方法 可定义多个
- 2.scala中定义变量使用var,定义常量使用val,变量可变,常量不可变 变量和常量类型可以省略不写,会自动推断
- 3.scala中每行后面都会有分号自动推断机制,不用显示的写出";"
- 4.建议在scala中使用驼峰命名法
- 5.Scala类型红可以传参,传参一定要指定类型,有了参数就有了默认的构造,类中的属性默认有getter和setter方法
- 6.类中重写构造时,第一行必须先调用默认的构造 def this(…)(…)
- 7.Scala中当new class时,类中除了方法不执行(除了构造方法),
- 8.在同一个文件中,class名称和Object名称一样时,这个类叫做这个对象的伴生类,
- 这个对象叫做这个类的伴生对象,他们之间可以互相访问私有变量
3.Scala方法与函数
3.1 Scala方法的定义
-
有参方法
-
无参方法

def fun (a: Int , b: Int ) : Unit = {
println(a+b)
}
fun(1,1)
def fun1 (a : Int , b : Int)= a+b
println(fun1(1,2))
注意点:
- 方法定义语法 用def来定义
- 可以定义传入的参数,要指定传入参数的类型
- 方法可以写返回值的类型也可以不写,会自动推断,有时候不能省略,必须写,比如在递归方法中或者方法的返回值是函数类型的时候。
- scala中方法有返回值时,可以写return,也可以不写return,会把方法中最后一行当做结果返回。当写return时,必须要写方法的返回值。
- 如果返回值可以一行搞定,可以将{…}省略不写
- 传递给方法的参数可以在方法中使用,并且scala规定方法的传过来的参数为val的,不是var的。
- 如果定义方法时,省略了方法名称和方法体之间的"=",那么无论方法体最后一行计算的结果是什么,都会被丢弃,返回Unit
3.2 方法与函数
定义一个方法:
def method(a:Int,b:Int) =a*b
val a =2
method(3,5)
定义一个函数:
Val f1=(x:Int,y:Int)=>x+y
f1 (1,2)
3.2.1 匿名函数
"=>"就是匿名函数,多用于方法的参数是函数时,常用匿名函数
val stringToUnit: String => Unit = (s: String) => {
println(s)
}
stringToUnit("hello")
在函数式编程语言中,函数是"头等公民",它可以像任何其他数据类型一样被传递和操作,函数可以在方法中传递。
3.2.2 递归方法
/**
* 递归方法
* 5的阶乘
*/
def fun2(num :Int) :Int= {
if(num ==1)
num
else
num * fun2(num-1)
}
print(fun2(5))
3.2.3 参数有默认值的方法
-
默认值的函数中,如果传入的参数个数与函数定义相同,则传入的数值会覆盖默认值。
-
如果不想覆盖默认值,传入的参数个数小于定义的函数的参数,则需要指定参数名称。
/**
* 包含默认参数值的函数
* 注意:
* 1.默认值的函数中,如果传入的参数个数与函数定义相同,则传入的数值会覆盖默认值
* 2.如果不想覆盖默认值,传入的参数个数小于定义的函数的参数,则需要指定参数名称
*/
def fun3(a :Int = 10,b:Int) = {
println(a+b)
}
fun3(b=2)
3.2.4 可变参数的方法
def fun(s:String*)= {
s.foreach(println)
}
3.2.5 匿名函数
-
有参匿名函数
-
无参匿名函数
-
有返回值的匿名函数
- 可以将匿名函数返回给val定义的值
/**
* 匿名函数
* 1.有参数匿名函数
* 2.无参数匿名函数
* 3.有返回值的匿名函数
* 注意:
* 可以将匿名函数返回给定义的一个变量
*/
//有参数匿名函数
val value1: (Int)=>Unit = (a : Int) => {
println(a)
}
value1(1)
//无参数匿名函数
val value2 = ()=>{
println("我爱学习")
}
value2()
//有返回值的匿名函数
val value3 = (a:Int,b:Int) =>{
a+b
}
println(value3(4,4))
3.2.6 嵌套方法
/**
* 嵌套方法
* 例如:嵌套方法求5的阶乘
*/
def fun5(num:Int)={
def fun6(a:Int,b:Int):Int={
if(a == 1){
b
}else{
fun6(a-1,a*b)
}
}
fun6(num,1)
}
println(fun5(5))
3.2.7 偏应用函数
偏应用函数是一种表达式,不需要提供函数需要的所有参数,只需要提供部分,或不提供所需参数。
某些情况下,方法中的参数非常多,调用这个方法非常频繁,每次调用只有固定的某个参数变化,其他的都不变可以定义偏应用参数来实现
/**
* 偏应用函数
*/
def showLog(date:Date,log:String): Unit ={
println(s"date is $date,log is $log")
}
val date=new Date()
showLog(date,"a")
showLog(date,"b")
showLog(date,"c")
def fun=showLog(date,_:String)
fun("a")
fun("b")
fun("c")
3.2.8 高阶函数
函数的参数是函数,或者函数的返回类型是函数,或者函数的参数和函数的返回类型是函数的函数。
-
函数的参数是函数
-
函数的返回是函数
-
函数的参数和函数的返回是函数
/**
* 高阶函数
* 函数的参数是函数 或者函数的返回是函数 或者函数的参数和返回都是函数
*/
//函数的参数是函数
def hightFun(f : (Int,Int) =>Int, a:Int ) : Int = {
f(a,100)
}
def f(v1 :Int,v2: Int):Int = {
v1+v2
}
println(hightFun(f, 1))
//函数的返回是函数
//1,2,3,4相加
def hightFun2(a : Int,b:Int) : (Int,Int)=>Int = {
def f2 (v1: Int,v2:Int) :Int = {
v1+v2+a+b
}
f2
}
println(hightFun2(1,2)(3,4))
//函数的参数是函数,函数的返回是函数
def hightFun3(f : (Int ,Int) => Int) : (Int,Int) => Int = {
f
}
println(hightFun3(f)(100,200))
println(hightFun3((a,b) =>{a+b})(200,200))
//以上这句话还可以写成这样
//如果函数的参数在方法体中只使用了一次 那么可以写成_表示
println(hightFun3(_+_)(200,200))
3.2.9 柯里化函数
-
高阶函数的简化
-
定义
-
柯里化(Currying)指的是把原来接受多个参数的函数变换成接受一个参数的函数过程,并且返回接受余下的参数且返回结果为一个新函数的技术。
-
scala柯里化风格的使用可以简化主函数的复杂度,提高主函数的自闭性,提高功能上的可扩张性、灵活性。可以编写出更加抽象,功能化和高效的函数式代码。
def fun7(a :Int,b:Int)(c:Int,d:Int) = { a+b+c+d } println(fun7(1,2)(3,4))
3.2.10 闭包
-
闭包是一个函数,返回值依赖于声明在函数外部的一个或多个变量。
-
闭包通常来讲可以简单的认为是可以访问不在当前作用域范围内的一个函数
/**
* scala中的闭包
* 闭包是一个函数,返回值依赖于声明在函数外部的一个或多个变量。
*/
object ClosureDemo {
def main(args: Array[String]): Unit = {
//变量y不处于其有效作用域时,函数还能够对变量进行访问
val y=20
val add=(x:Int)=>{
x+y
}
//在add中有两个变量:x和y。其中的一个x是函数的形式参数,
//在add方法被调用时,x被赋予一个新的值。y不是形式参数,而是自由变量
println(add(3))
}
}
4. Scala字符串
String
StringBuilder 可变
string操作方法举例
-
比较:equals
-
比较忽略大小写:equalsIgnoreCase
-
indexOf:如果字符串中有传入的assci码对应的值,返回下标
/**
* String && StringBuilder
*/
val str = "abcd"
val str1 = "ABCD"
println(str.indexOf(97))
println(str.indexOf("b"))
println(str==str1)
/**
* compareToIgnoreCase
*
* 如果参数字符串等于此字符串,则返回值 0;
* 如果此字符串小于字符串参数,则返回一个小于 0 的值;
* 如果此字符串大于字符串参数,则返回一个大于 0 的值。
*
*/
println(str.compareToIgnoreCase(str1))
String类的相关方法
char charAt(int index)
返回指定位置的字符 从0开始
int compareTo(Object o)
比较字符串与对象
int compareTo(String anotherString)
按字典顺序比较两个字符串
int compareToIgnoreCase(String str)
按字典顺序比较两个字符串,不考虑大小写
String concat(String str)
将指定字符串连接到此字符串的结尾
boolean contentEquals(StringBuffer sb)
将此字符串与指定的 StringBuffer 比较。
static String copyValueOf(char[] data)
返回指定数组中表示该字符序列的 String
static String copyValueOf(char[] data, int offset, int count)
返回指定数组中表示该字符序列的 String
boolean endsWith(String suffix)
测试此字符串是否以指定的后缀结束
boolean equals(Object anObject)
将此字符串与指定的对象比较
boolean equalsIgnoreCase(String anotherString)
将此 String 与另一个 String 比较,不考虑大小写
byte getBytes()
使用平台的默认字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中
byte[] getBytes(String charsetName
使用指定的字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中
void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)
将字符从此字符串复制到目标字符数组
int hashCode()
返回此字符串的哈希码
16
int indexOf(int ch)
返回指定字符在此字符串中第一次出现处的索引(输入的是ascii码值)
int indexOf(int ch, int fromIndex)
返返回在此字符串中第一次出现指定字符处的索引,从指定的索引开始搜索
int indexOf(String str)
返回指定子字符串在此字符串中第一次出现处的索引
int indexOf(String str, int fromIndex)
返回指定子字符串在此字符串中第一次出现处的索引,从指定的索引开始
String intern()
返回字符串对象的规范化表示形式
int lastIndexOf(int ch)
返回指定字符在此字符串中最后一次出现处的索引
int lastIndexOf(int ch, int fromIndex)
返回指定字符在此字符串中最后一次出现处的索引,从指定的索引处开始进行反向搜索
int lastIndexOf(String str)
返回指定子字符串在此字符串中最右边出现处的索引
int lastIndexOf(String str, int fromIndex)
返回指定子字符串在此字符串中最后一次出现处的索引,从指定的索引开始反向搜索
int length()
返回此字符串的长度
boolean matches(String regex)
告知此字符串是否匹配给定的正则表达式
boolean regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len)
测试两个字符串区域是否相等
28
boolean regionMatches(int toffset, String other, int ooffset, int len)
测试两个字符串区域是否相等
String replace(char oldChar, char newChar)
返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的
String replaceAll(String regex, String replacement
使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串
String replaceFirst(String regex, String replacement)
使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串
String[] split(String regex)
根据给定正则表达式的匹配拆分此字符串
String[] split(String regex, int limit)
根据匹配给定的正则表达式来拆分此字符串
boolean startsWith(String prefix)
测试此字符串是否以指定的前缀开始
boolean startsWith(String prefix, int toffset)
测试此字符串从指定索引开始的子字符串是否以指定前缀开始。
CharSequence subSequence(int beginIndex, int endIndex)
返回一个新的字符序列,它是此序列的一个子序列
String substring(int beginIndex)
返回一个新的字符串,它是此字符串的一个子字符串
String substring(int beginIndex, int endIndex)
返回一个新字符串,它是此字符串的一个子字符串
char[] toCharArray()
将此字符串转换为一个新的字符数组
String toLowerCase()
使用默认语言环境的规则将此 String 中的所有字符都转换为小写
String toLowerCase(Locale locale)
使用给定 Locale 的规则将此 String 中的所有字符都转换为小写
String toString()
返回此对象本身(它已经是一个字符串!)
String toUpperCase()
使用默认语言环境的规则将此 String 中的所有字符都转换为大写
String toUpperCase(Locale locale)
使用给定 Locale 的规则将此 String 中的所有字符都转换为大写
String trim()
删除指定字符串的首尾空白符
static String valueOf(primitive data type x)
返回指定类型参数的字符串表示形式
5. 集合
5.1 数组
5.1.1 创建数组
/**
* 创建数组两种方式:
* 1.new Array[String](3)
* 2.直接Array
*/
//创建类型为Int 长度为3的数组
val arr1 = new Array[Int](3)
//创建String 类型的数组,直接赋值
val arr2 = Array[String]("s100","s200","s300")
//赋值
arr1(0) = 100
arr1(1) = 200
arr1(2) = 300
5.1.2 数组遍历
arr.foreach(println)
for(elem<-arr)
println(elem)
5.1.3 创建一维数组和二维数组
//一维数组
var arr1=new Array[Int](3)
arr1(0)=1
arr1(1)=2
arr1(2)=3
arr1.foreach(println)
//二维数组
val array=new Array[Array[Int]](3)
array(0)=Array[Int](1,2,3)
array(1)=Array[Int](4,5,6)
array(2)=Array[Int](7,8,9)
for(arr<-array){
for(elem<-arr)
println(elem)
}
5.1.4 数组中方法举例
- Array.concate:合并数组
- Array.fill(5)(“baway”):创建初始值的定长数组
Array常用方法
def apply( x: T, xs: T* ): Array[T]
创建指定对象 T 的数组, T 的值可以是 Unit, Double, Float, Long, Int, Char, Short, Byte, Boolean。
def concat[T]( xss: Array[T]* ): Array[T]
合并数组
def copy( src: AnyRef, srcPos: Int, dest: AnyRef, destPos: Int, length: Int ): Unit
复制一个数组到另一个数组上。相等于 Java's System.arraycopy(src, srcPos, dest, destPos, length)。
def empty[T]: Array[T]
返回长度为 0 的数组
def iterate[T]( start: T, len: Int )( f: (T) => T ): Array[T]
返回指定长度数组,每个数组元素为指定函数的返回值。
scala> Array.iterate(0,3)(a=>a+1)
res1: Array[Int] = Array(0, 1, 2)
以上实例数组初始值为 0,长度为 3,计算函数为a=>a+1:
def fill[T]( n: Int )(elem: => T): Array[T]
返回数组,长度为第一个参数指定,同时每个元素使用第二个参数进行填充。
def fill[T]( n1: Int, n2: Int )( elem: => T ): Array[Array[T]]
返回二数组,长度为第一个参数指定,同时每个元素使用第二个参数进行填充。
def ofDim[T]( n1: Int ): Array[T]
创建指定长度的数组
def ofDim[T]( n1: Int, n2: Int ): Array[Array[T]]
创建二维数组
def ofDim[T]( n1: Int, n2: Int, n3: Int ): Array[Array[Array[T]]]
创建三维数组
def range( start: Int, end: Int, step: Int ): Array[Int]
创建指定区间内的数组,step 为每个元素间的步长
def range( start: Int, end: Int ): Array[Int]
创建指定区间内的数组
def tabulate[T]( n: Int )(f: (Int)=> T): Array[T]
返回指定长度数组,每个数组元素为指定函数的返回值,默认从 0 开始。
以上实例返回 3 个元素:
scala> Array.tabulate(3)(a => a + 5)
res0: Array[Int] = Array(5, 6, 7)
def tabulate[T]( n1: Int, n2: Int )( f: (Int, Int ) => T): Array[Array[T]]
返回指定长度的二维数组,每个数组元素为指定函数的返回值,默认从 0 开始。
5.1.5 可变长数组
/**
* 可变长度数组的定义
*/
val arr = ArrayBuffer[String]("a","b","c")
arr.append("hello","scala")//添加多个元素
arr.+=("end")//在最后追加元素
arr.+=:("start")//在开头添加元素
arr.foreach(println)
5.2 list
5.2.1 创建list
val list = List(1,2,3,4)
- Nil长度为0的list
5.2.2 list遍历
//遍历
list.foreach { x => println(x)}
// list.foreach { println}
//filter
val list1 = list.filter { x => x>3 }
list1.foreach { println}
//count
val value = list1.count { x => x>3 }
println(value)
//map
val nameList = List(
"hello baway",
"hello xasxt",
"hello shsxt"
)
val mapResult:List[Array[String]] = nameList.map{ x => x.split(" ") }
mapResult.foreach{println}
//flatmap
val flatMapResult : List[String] = nameList.flatMap{ x => x.split(" ") }
flatMapResult.foreach { println }
5.2.3 list方法举例
-
filter:过滤元素
-
count:计算符合条件的元素个数
-
map:对元素操作
-
flatmap :压扁扁平,先map再flatten
flagmap示意图:

5.2.4 list方法总结
def +(elem: A): List[A]
前置一个元素列表
def ::(x: A): List[A]
在这个列表的开头添加的元素。
def :::(prefix: List[A]): List[A]
增加了一个给定列表中该列表前面的元素。
def ::(x: A): List[A]
增加了一个元素x在列表的开头
def addString(b: StringBuilder): StringBuilder
追加列表的一个字符串生成器的所有元素。
def addString(b: StringBuilder, sep: String): StringBuilder
追加列表的使用分隔字符串一个字符串生成器的所有元素。
def apply(n: Int): A
选择通过其在列表中索引的元素
def contains(elem: Any): Boolean
测试该列表中是否包含一个给定值作为元素。
def copyToArray(xs: Array[A], start: Int, len: Int): Unit
列表的副本元件阵列。填充给定的数组xs与此列表中最多len个元素,在位置开始。
def distinct: List[A]
建立从列表中没有任何重复的元素的新列表。
def drop(n: Int): List[A]
返回除了第n个的所有元素。
def dropRight(n: Int): List[A]
返回除了最后的n个的元素
def dropWhile(p: (A) => Boolean): List[A]
丢弃满足谓词的元素最长前缀。
def endsWith[B](that: Seq[B]): Boolean
测试列表是否使用给定序列结束。
def equals(that: Any): Boolean
equals方法的任意序列。比较该序列到某些其他对象。
def exists(p: (A) => Boolean): Boolean
测试谓词是否持有一些列表的元素。
def filter(p: (A) => Boolean): List[A]
返回列表满足谓词的所有元素。
def forall(p: (A) => Boolean): Boolean
测试谓词是否持有该列表中的所有元素。
def foreach(f: (A) => Unit): Unit
应用一个函数f以列表的所有元素。
20 def head: A
选择列表的第一个元素
def indexOf(elem: A, from: Int): Int
经过或在某些起始索引查找列表中的一些值第一次出现的索引。
def init: List[A]
返回除了最后的所有元素
def intersect(that: Seq[A]): List[A]
计算列表和另一序列之间的多重集交集。
def isEmpty: Boolean
测试列表是否为空
def iterator: Iterator[A]
创建一个新的迭代器中包含的可迭代对象中的所有元素
def last: A
返回最后一个元素
def lastIndexOf(elem: A, end: Int): Int
之前或在一个给定的最终指数查找的列表中的一些值最后一次出现的索引
def length: Int
返回列表的长度
def map[B](f: (A) => B): List[B]
通过应用函数以g这个列表中的所有元素构建一个新的集合
def max: A
查找最大的元素
def min: A
查找最小元素
def mkString: String
显示列表的字符串中的所有元素
def mkString(sep: String): String
显示的列表中的字符串中使用分隔串的所有元素
def reverse: List[A]
返回新列表,在相反的顺序元素
def sorted[B >: A]: List[A]
根据排序对列表进行排序
def startsWith[B](that: Seq[B], offset: Int): Boolean
测试该列表中是否包含给定的索引处的给定的序列
def sum: A
概括这个集合的元素
def tail: List[A]
返回除了第一的所有元素
def take(n: Int): List[A]
返回前n个元素
def takeRight(n: Int): List[A]
返回最后n个元素
def toArray: Array[A]
列表以一个数组变换
def toBuffer[B >: A]: Buffer[B]
列表以一个可变缓冲器转换
def toMap[T, U]: Map[T, U]
此列表的映射转换
def toSeq: Seq[A]
列表的序列转换
def toSet[B >: A]: Set[B]
列表到集合变换
def toString(): String
列表转换为字符串
5.2.5 可变长list
/**
* 可变长list
*/
val listBuffer: ListBuffer[Int] = ListBuffer[Int](1,2,3,4,5)
listBuffer.append(6,7,8,9)//追加元素
listBuffer.+=(10)//在后面追加元素
listBuffer.+=:(100)//在开头加入元素
listBuffer.foreach(println
5.3 set
5.3.1 创建set
//创建 没有new方法
val set1 = Set(1,2,3,4,4)
val set2 = Set(1,2,5)
5.3.2 set遍历
set1.foreach { println}
for(s <- set1){
println(s)
}
5.3.3 set方法举例
-
交集:intersect ,&
-
差集: diff ,&~
-
子集:subsetOf
-
最大:max
-
最小:min
-
转成数组,toList
-
转成字符串:mkString("~")
//交集 val set3 = set1.intersect(set2) set3.foreach{println} val set4 = set1.&(set2) set4.foreach{println} println("*******") //差集 set1.diff(set2).foreach { println } set1.&~(set2).foreach { println } //子集 set1.subsetOf(set2) //最大值 println(set1.max) //最小值 println(set1.min) println("****") //转成数组,list set1.toArray.foreach{println} println("****") set1.toList.foreach{println} //mkString println(set1.mkString) println(set1.mkString("\t"))
5.3.4 set方法总结
def +(elem: A): Set[A]
为集合添加新元素,x并创建一个新的集合,除非元素已存在
def -(elem: A): Set[A]
移除集合中的元素,并创建一个新的集合
def contains(elem: A): Boolean
如果元素在集合中存在,返回 true,否则返回 false。
def &(that: Set[A]): Set[A]
返回两个集合的交集
def &~(that: Set[A]): Set[A]
返回两个集合的差集
def +(elem1: A, elem2: A, elems: A*): Set[A]
通过添加传入指定集合的元素创建一个新的不可变集合
def ++(elems: A): Set[A]
合并两个集合
def -(elem1: A, elem2: A, elems: A*): Set[A]
通过移除传入指定集合的元素创建一个新的不可变集合
def addString(b: StringBuilder): StringBuilder
将不可变集合的所有元素添加到字符串缓冲区
def addString(b: StringBuilder, sep: String): StringBuilder
将不可变集合的所有元素添加到字符串缓冲区,并使用指定的分隔符
def apply(elem: A)
检测集合中是否包含指定元素
def count(p: (A) => Boolean): Int
计算满足指定条件的集合元素个数
def copyToArray(xs: Array[A], start: Int, len: Int): Unit
复制不可变集合元素到数组
def diff(that: Set[A]): Set[A]
比较两个集合的差集
def drop(n: Int): Set[A]]
返回丢弃前n个元素新集合
def dropRight(n: Int): Set[A]
返回丢弃最后n个元素新集合
def dropWhile(p: (A) => Boolean): Set[A]
从左向右丢弃元素,直到条件p不成立
def equals(that: Any): Boolean
equals 方法可用于任意序列。用于比较系列是否相等。
def exists(p: (A) => Boolean): Boolean
判断不可变集合中指定条件的元素是否存在。
def filter(p: (A) => Boolean): Set[A]
输出符合指定条件的所有不可变集合元素。
def find(p: (A) => Boolean): Option[A]
查找不可变集合中满足指定条件的第一个元素
def forall(p: (A) => Boolean): Boolean
查找不可变集合中满足指定条件的所有元素
def foreach(f: (A) => Unit): Unit
将函数应用到不可变集合的所有元素
def head: A
获取不可变集合的第一个元素
def init: Set[A]
返回所有元素,除了最后一个
def intersect(that: Set[A]): Set[A]
计算两个集合的交集
def isEmpty: Boolean
判断集合是否为空
def iterator: Iterator[A]
创建一个新的迭代器来迭代元素
def last: A
返回最后一个元素
def map[B](f: (A) => B): immutable.Set[B]
通过给定的方法将所有元素重新计算
def max: A
查找最大元素
def min: A
查找最小元素
def mkString: String
集合所有元素作为字符串显示
def mkString(sep: String): String
使用分隔符将集合所有元素作为字符串显示
def product: A
返回不可变集合中数字元素的积。
def size: Int
返回不可变集合元素的数量
def splitAt(n: Int): (Set[A], Set[A])
把不可变集合拆分为两个容器,第一个由前 n 个元素组成,第二个由剩下的元素组成
def subsetOf(that: Set[A]): Boolean
如果集合A中含有子集B返回 true,否则返回false
def sum: A
返回不可变集合中所有数字元素之和
def tail: Set[A]
返回一个不可变集合中除了第一元素之外的其他元素
def take(n: Int): Set[A]
返回前 n 个元素
def takeRight(n: Int):Set[A]
返回后 n 个元素
def toArray: Array[A]
将集合转换为数组
def toBuffer[B >: A]: Buffer[B]
返回缓冲区,包含了不可变集合的所有元素
def toList: List[A]
返回 List,包含了不可变集合的所有元素
def toMap[T, U]: Map[T, U]
返回 Map,包含了不可变集合的所有元素
def toSeq: Seq[A]
返回 Seq,包含了不可变集合的所有元素
def toString(): String
返回一个字符串,以对象来表示
5.3.5 可变长set
import scala.collection.mutable.Set
val set = Set[Int](1,2,3,4,5)
set.add(100)
set.+=(200)
set.+=(1,210,300)
set.foreach(println)
注意:
Seq是列表,适合存有序重复数据,进行快速插入/删除元素等场景
Set是集合,适合存无序非重复数据,进行快速查找海量元素的等场景
6.map
6.1map创建
val map = Map(
"1" -> "baway",
2 -> "shsxt",
(3,"xasxt")
)
注意:创建map时,相同的key被后面的相同的key顶替掉,只保留一个
6.2获取map的值
- map.get(“1”).get
- map.get(100).getOrElse(“no value”):如果map中没有对应项,赋值为getOrElse传的值。
//获取值
println(map.get("1").get)
val result = map.get(8).getOrElse("no value")
println(result)
6.3 遍历map
- for,foreach
//map遍历
for(x <- map){
println("====key:"+x._1+",value:"+x._2)
}
map.foreach(f => {
println("key:"+ f._1+" ,value:"+f._2)
})
6.4 遍历key
- map.keys
//遍历key
val keyIterable = map.keys
keyIterable.foreach { key => {
println("key:"+key+", value:"+map.get(key).get)
} }
println("---------")
6.5 遍历value
- map.values
//遍历value
val valueIterable = map.values
valueIterable.foreach { value => {
println("value: "+ value)
} }
6.6 合并map
-
++ 例:map1.++(map2) --map1中加入map2
-
++: 例:map1.++:(map2) --map2中加入map1(新版本中已经没有这个方法)
注意:合并map会将map中的相同key的value替换
val map1=Map[String,Int](("a",1),("b",2),("c",3),("d",4))
val map2=Map[String,Int](("a",100),("b",2),("c",300),("e",500))
//map2合并map1,相同key的用map2当中的数替换
val result= map1.++(map2)
result.foreach(println)
6.7 map中的方法举例
-
filter:过滤,留下符合条件的记录
-
count:统计符合条件的记录数
-
contains:map中是否包含某个key
-
exist:符合条件的记录存在不存在
/**
* map方法
*/
//count
val countResult = map.count(p => {
p._2.equals("shsxt")
})
println(countResult)
//filter
map.filter(_._2.equals("shsxt")).foreach(println)
//contains
println(map.contains(2))
//exist
println(map.exists(f =>{
f._2.equals("xasxt")
}))
6.8 Map方法总结
def ++(xs: Map[(A, B)]): Map[A, B]
返回一个新的 Map,新的 Map xs 组成
def -(elem1: A, elem2: A, elems: A*): Map[A, B]
返回一个新的 Map, 移除 key 为 elem1, elem2 或其他 elems。
def --(xs: GTO[A]): Map[A, B]
返回一个新的 Map, 移除 xs 对象中对应的 key
def get(key: A): Option[B]
返回指定 key 的值
def iterator: Iterator[(A, B)]
创建新的迭代器,并输出 key/value 对
def addString(b: StringBuilder): StringBuilder
将 Map 中的所有元素附加到StringBuilder,可加入分隔符
def addString(b: StringBuilder, sep: String): StringBuilder
将 Map 中的所有元素附加到StringBuilder,可加入分隔符
def apply(key: A): B
返回指定键的值,如果不存在返回 Map 的默认方法
def clone(): Map[A, B]
从一个 Map 复制到另一个 Map
def contains(key: A): Boolean
如果 Map 中存在指定 key,返回 true,否则返回 false。
def copyToArray(xs: Array[(A, B)]): Unit
复制集合到数组
def count(p: ((A, B)) => Boolean): Int
计算满足指定条件的集合元素数量
def default(key: A): B
定义 Map 的默认值,在 key 不存在时返回。
def drop(n: Int): Map[A, B]
返回丢弃前n个元素新集合
def dropRight(n: Int): Map[A, B]
返回丢弃最后n个元素新集合
def dropWhile(p: ((A, B)) => Boolean): Map[A, B]
从左向右丢弃元素,直到条件p不成立
def empty: Map[A, B]
返回相同类型的空 Map
def equals(that: Any): Boolean
如果两个 Map 相等(key/value 均相等),返回true,否则返回false
def exists(p: ((A, B)) => Boolean): Boolean
判断集合中指定条件的元素是否存在
def filter(p: ((A, B))=> Boolean): Map[A, B]
返回满足指定条件的所有集合
def filterKeys(p: (A) => Boolean): Map[A, B]
返回符合指定条件的的不可变 Map
def find(p: ((A, B)) => Boolean): Option[(A, B)]
查找集合中满足指定条件的第一个元素
def foreach(f: ((A, B)) => Unit): Unit
将函数应用到集合的所有元素
def init: Map[A, B]
返回所有元素,除了最后一个
def isEmpty: Boolean
检测 Map 是否为空
def keys: Iterable[A]
返回所有的key/p>
def last: (A, B)
返回最后一个元素
def max: (A, B)
查找最大元素
def min: (A, B)
查找最小元素
def mkString: String
集合所有元素作为字符串显示
def product: (A, B)
返回集合中数字元素的积。
def remove(key: A): Option[B]
移除指定 key
def retain(p: (A, B) => Boolean): Map.this.type
如果符合满足条件的返回 true
def size: Int
返回 Map 元素的个数
def sum: (A, B)
返回集合中所有数字元素之和
def tail: Map[A, B]
返回一个集合中除了第一元素之外的其他元素
def take(n: Int): Map[A, B]
返回前 n 个元素
def takeRight(n: Int): Map[A, B]
返回后 n 个元素
def takeWhile(p: ((A, B)) => Boolean): Map[A, B]
返回满足指定条件的元素
def toArray: Array[(A, B)]
集合转数组
def toBuffer[B >: A]: Buffer[B]
返回缓冲区,包含了 Map 的所有元素
def toList: List[A]
返回 List,包含了 Map 的所有元素
def toSeq: Seq[A]
返回 Seq,包含了 Map 的所有元素
def toSet: Set[A]
返回 Set,包含了 Map 的所有元素
def toString(): String
返回字符串对象
6.9 可变长map
/**
* 可变长Map
*/
import scala.collection.mutable.Map
val map = Map[String,Int]()
map.put("hello",100)
map.put("world",200)
map.foreach(println)
7.元组
7.1 元组定义
与列表一样,与列表不同的是元组可以包含不同类型的元素。元组的值是通过将单个的值包含在圆括号中构成的。
7.2创建元组与取值
-
val tuple = new Tuple(1) 可以使用new
-
val tuple2 = Tuple(1,2) 可以不使用new,也可以直接写成val tuple3 =(1,2,3)
-
取值用"._XX" 可以获取元组中的值
注意:tuple最多支持22个参数
//创建,最多支持22个
val tuple = new Tuple1(1)
val tuple2 = Tuple2("zhangsan",2)
val tuple3 = Tuple3(1,2,3)
val tuple4 = (1,2,3,4)
val tuple18 = Tuple18(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18)
val tuple22 = new Tuple22(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)
//使用
println(tuple2._1 + "\t"+tuple2._2)
val t = Tuple2((1,2),("zhangsan","lisi"))
println(t._1._2)
7.3 元组的遍历
tuple.productIterator得到迭代器,进而遍历
//遍历
val tupleIterator = tuple22.productIterator
while(tupleIterator.hasNext){
println(tupleIterator.next())
}
7.4 swap,toString方法
注意:swap元素翻转,只针对二元组
/**
* 方法
*/
//翻转,只针对二元组
println(tuple2.swap)
//toString
println(tuple3.toString())
8. trait 特性
8.1概念理解
Scala Trait(特征) 相当于 Java 的接口,实际上它比接口还功能强大。
与接口不同的是,它还可以定义属性和方法的实现。
一般情况下Scala的类可以继承多个Trait,从结果来看就是实现了多重继承。Trait(特征) 定义的方式与类类似,但它使用的关键字是 trait。
8.2 举例:trait中带属性带方法实现
注意:
继承的多个trait中如果有同名的方法和属性,必须要在类中使用"override"重新定义。
trait中不可以传参数
trait Read {
val readType = "Read"
val gender = "m"
def read(name:String){
println(name+" is reading")
}
}
trait Listen {
val listenType = "Listen"
val gender = "m"
def listen(name:String){
println(name + " is listenning")
}
}
class Person() extends Read with Listen{
override val gender = "f"
}
object test {
def main(args: Array[String]): Unit = {
val person = new Person()
person.read("zhangsan")
person.listen("lisi")
println(person.listenType)
println(person.readType)
println(person.gender)
}
}
8.3 举例:trait中带方法不实现
object Lesson_Trait2 {
def main(args: Array[String]): Unit = {
val p1 = new Point(1,2)
val p2 = new Point(1,3)
println(p1.isEqule(p2))
println(p1.isNotEqule(p2))
}
}
trait Equle{
def isEqule(x:Any) :Boolean
def isNotEqule(x : Any) = {
!isEqule(x)
}
}
class Point(x:Int, y:Int) extends Equle {
val xx = x
val yy = y
def isEqule(p:Any) = {
p.isInstanceOf[Point] && p.asInstanceOf[Point].xx==xx
}
}
9. 模式匹配match
9.1 概念理解:
Scala 提供了强大的模式匹配机制,应用也非常广泛。
一个模式匹配包含了一系列备选项,每个都开始于关键字 case。
每个备选项都包含了一个模式及一到多个表达式。箭头符号 => 隔开了模式和表达式。
9.2 代码及注意点
-
模式匹配不仅可以匹配值还可以匹配类型
-
从上到下顺序匹配,如果匹配到则不再往下匹配
-
都匹配不上时,会匹配到case _ ,相当于default
-
match 的最外面的"{ }"可以去掉看成一个语句
object Lesson_Match {
def main(args: Array[String]): Unit = {
val tuple = Tuple6(1,2,3f,4,"abc",55d)
val tupleIterator = tuple.productIterator
while(tupleIterator.hasNext){
matchTest(tupleIterator.next())
}
}
def matchTest(x:Any) ={
x match {
case x:Int=> println("type is Int")
case 1 => println("result is 1")
case 2 => println("result is 2")
case 3=> println("result is 3")
case 4 => println("result is 4")
case x:String => println("type is String")
// case x :Double => println("type is Double")
case _ => println("no match")
}
}
}
9.3 偏函数
如果一个方法中没有match 只有case,这个函数可以定义成PartialFunction偏函数。偏函数定义时,不能使用括号传参,默认定义PartialFunction中传入一个值,匹配上了对应的case,返回一个值,只能匹配同种类型。
**
* 一个函数中只有case 没有match ,可以定义成PartailFunction 偏函数
*/
object Lesson_PartialFunction {
def MyTest : PartialFunction[String,String] = {
case "scala" =>{"scala"}
case "hello"=>{"hello"}
case _=> {"no match ..."}
}
def main(args: Array[String]): Unit = {
println(MyTest("scala"))
}
}
10. 样例类(case classes)
10.1 概念理解
使用了case关键字的类定义就是样例类(case classes),样例类是种特殊的类。实现了类构造参数的getter方法(构造参数默认被声明为val),当构造参数是声明为var类型的,它将帮你实现setter和getter方法。
-
样例类默认帮你实现了toString,equals,copy和hashCode等方法。
-
样例类可以new, 也可以不用new
-
当一个类被定义成为case类后,Scala会自动帮你创建一个伴生对象并帮你实现了apply, unapply,setter, getter 和toString,equals,copy和hashCode等方法
10.2 例子:结合模式匹配的代码
case class Person1(name:String,age:Int)
object Lesson_CaseClass {
def main(args: Array[String]): Unit = {
val p1 = new Person1("zhangsan",10)
val p2 = Person1("lisi",20)
val p3 = Person1("wangwu",30)
val list = List(p1,p2,p3)
list.foreach { x => {
x match {
case Person1("zhangsan",10) => println("zhangsan")
case Person1("lisi",20) => println("lisi")
case _ => println("no match")
}
} }
}
}
11.隐式转换
隐式转换是在Scala编译器进行类型匹配时,如果找不到合适的类型,那么隐式转换会让编译器在作用范围内自动推导出来合适的类型。
11.1 隐式值与隐式参数
隐式值是指在定义参数时前面加上implicit。隐式参数是指在定义方法时,方法中的部分参数是由implicit修饰【必须使用柯里化的方式,将隐式参数写在后面的括号中】。隐式转换作用就是:当调用方法时,不必手动传入方法中的隐式参数,Scala会自动在作用域范围内寻找隐式值自动传入。
隐式值和隐式参数注意:
1). 同类型的参数的隐式值只能在作用域内出现一次,同一个作用域内不能定义多个类型一样的隐式值。
2). implicit 关键字必须放在隐式参数定义的开头
3). 一个方法只有一个参数是隐式转换参数时,那么可以直接定义implicit关键字修饰的参数,调用时直接创建类型不传入参数即可。
4). 一个方法如果有多个参数,要实现部分参数的隐式转换,必须使用柯里化这种方式,隐式关键字出现在后面,只能出现一次
object Lesson_ImplicitValue {
def Student(age:Int)(implicit name:String,i:Int)= {
println( s"student :$name ,age = $age ,score = $i")
}
def Teacher(implicit name:String) ={
println(s"teacher name is = $name")
}
def main(args: Array[String]): Unit = {
implicit val zs = "zhangsan"
implicit val sr = 100
Student(18)
Teacher
}
11.2 隐式转换函数
隐式转换函数是使用关键字implicit修饰的方法。当Scala运行时,假设如果A类型变量调用了method()这个方法,发现A类型的变量没有method()方法,而B类型有此method()方法,会在作用域中寻找有没有隐式转换函数将A类型转换成B类型,如果有隐式转换函数,那么A类型就可以调用method()这个方法。
隐式转换函数注意:隐式转换函数只与函数的参数类型和返回类型有关,与函数名称无关,所以作用域内不能有相同的参数类型和返回类型的不同名称隐式转换函数。
class Animal(name:String){
def canFly(): Unit ={
println(s"$name can fly...")
}
}
class Rabbit(xname:String){
val name = xname
}
object Lesson_ImplicitFunction {
implicit def rabbitToAnimal(rabbit:Rabbit):Animal = {
new Animal(rabbit.name)
}
/**
注意,返回相同类型的不同名称的函数不行
例如: implicit def ABC(rabbit:Rabbit):Animal = {
new Animal(rabbit.name)
}
**/
def main(args: Array[String]): Unit = {
val rabbit = new Rabbit("RABBIT")
rabbit.canFly()
}
}
11.3 隐式类
使用implicit关键字修饰的类就是隐式类。若一个变量A没有某些方法或者某些变量时,而这个变量A可以调用某些方法或者某些变量时,可以定义一个隐式类,隐式类中定义这些方法或者变量,隐式类中传入A即可。
隐式类注意:
1).隐式类必须定义在类,包对象,伴生对象中。
2).隐式类的构造必须只有一个参数,同一个类,包对象,伴生对象中不能出现同类型构造的隐式类。
class Rabbit(s:String){
val name = s
}
object Lesson_ImplicitClass {
implicit class Animal(rabbit:Rabbit){
val tp = "Animal"
def canFly() ={
println(rabbit.name +" can fly...")
}
}
def main(args: Array[String]): Unit = {
val rabbit = new Rabbit("rabbit")
rabbit.canFly()
println(rabbit.tp)
}
12.Actor Model(了解)
12.1 概念理解
Actor Model是用来编写并行计算或分布式系统的高层次抽象(类似java中的Thread)让程序员不必为多线程模式下共享锁而烦恼,被用在Erlang 语言上, 高可用性99.9999999 % 一年只有31ms 宕机Actors将状态和行为封装在一个轻量的进程/线程中,但是不和其他Actors分享状态,每个Actors有自己的世界观,当需要和其他Actors交互时,通过发送事件和消息,发送是异步的,非堵塞的(fire-andforget),发送消息后不必等另外Actors回复,也不必暂停,每个Actors有自己的消息队列,进来的消息按先来后到排列,这就有很好的并发策略和可伸缩性,可以建立性能很好的事件驱动系统。
Actor的特征:
-
ActorModel是消息传递模型,基本特征就是消息传递
-
消息发送是异步的,非阻塞的
-
消息一旦发送成功,不能修改
-
Actor之间传递时,自己决定决定去检查消息,而不是一直等待,是异步非阻塞的
什么是Akka
Akka 是一个用 Scala 编写的库,用于简化编写容错的、高可伸缩性的 Java 和Scala 的 Actor 模型应用,底层实现就是Actor,Akka是一个开发库和运行环境,可以用于构建高并发、分布式、可容错、事件驱动的基于JVM的应用。使构建高并发的分布式应用更加容易。
spark1.6版本之前,spark分布式节点之间的消息传递使用的就是Akka,底层也就是actor实现的。1.6之后使用的netty传输。
12.2 例:Actor简单例子发送接收消息
import scala.actors.Actor
class myActor extends Actor{
def act(){
while(true){
receive {
case x:String => println("get String ="+ x)
case x:Int => println("get Int")
case _ => println("get default")
}
}
}
}
object Lesson_Actor {
def main(args: Array[String]): Unit = {
//创建actor的消息接收和传递
val actor =new myActor()
//启动
actor.start()
//发送消息写法
actor ! "i love you !"
}
}
12.3 例:Actor与Actor之间通信
case class Message(actor:Actor,msg:Any)
class Actor1 extends Actor{
def act(){
while(true){
receive{
case msg :Message => {
println("i sava msg! = "+ msg.msg)
msg.actor!"i love you too !"
}
case msg :String => println(msg)
case _ => println("default msg!")
}
}
}
}
class Actor2(actor :Actor) extends Actor{
actor ! Message(this,"i love you !")
def act(){
while(true){
receive{
case msg :String => {
if(msg.equals("i love you too !")){
println(msg)
actor! "could we have a date !"
}
}
case _ => println("default msg!")
}
}
}
}
object Lesson_Actor2 {
def main(args: Array[String]): Unit = {
val actor1 = new Actor1()
actor1.start()
val actor2 = new Actor2(actor1)
actor2.start()
}
}
13.Spark :WordCount
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.rdd.RDD.rddToPairRDDFunctions
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("WC")
val sc = new SparkContext(conf)
val lines :RDD[String] = sc.textFile("./words.txt")
val word :RDD[String] = lines.flatMap{lines => {
lines.split(" ")
}}
val pairs : RDD[(String,Int)] = word.map{ x => (x,1) }
val result = pairs.reduceByKey{(a,b)=> {a+b}}
result.sortBy(_._2,false).foreach(println)
//简化写法
//lines.flatMap { _.split(" ")}.map { (_,1)}.reduceByKey(_+_).foreach(println)
}
}















 4697
4697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









