







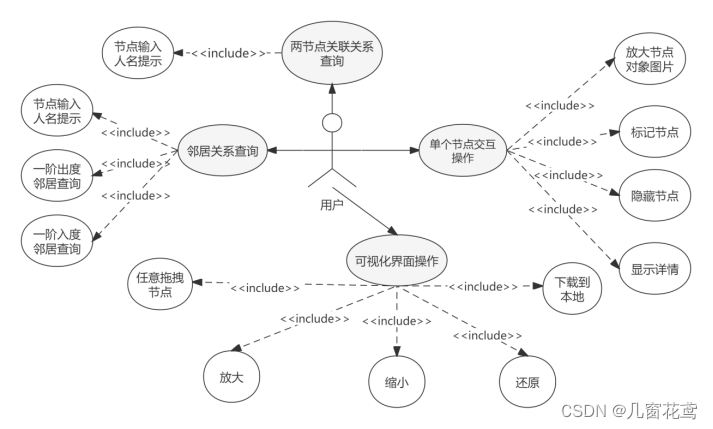
关联查询系统的主要功能
本系统是一个关联关系查询系统,构建此原型系统的目的主要是:为了方便用户分析两具体实体之间的关联关系网络。系统开发的总体任务是实现用户交互性良好的关联查询系统,提供两节点之间全路径导出子图的动态可视化展示界面。
数据收集
首先进行基础人名名单的获取,1905明星网中的明星库网址为:
https://www.1905.com/mdb/star/m1p1.html 为静态网页,因此通过Python的Requests库进行模拟请求,结合lxml进行网页信息提取,就可以爬取到其名单信息。
本文基于Python的网络爬虫技术进行网页爬取。首先使用Requests库来获取网页的html信息。Requests库中包含多种请求方式,本文中主要使用Requests库中的Get请求。需要爬取的位置信息如下图所示:

明确需要爬取的数据位置时,可以通过beatiful soup库或者lxml库进行HTML内容的解析,本文选择使用lxml库对HTML内容进行解析,解析后得到的基础人名格式图片如下。

然后需要从基础人名信息出发,让其向外扩展六层关系,并将关系记录到txt文件中。关系来源于百度百科搜索词条,当搜索明星人名时,该页面会显示相对应的明星关系。

其中需要注意的是,有些人名在搜索的时候会认为是同义词,即可能有多个同名的人。在拼接url进行人名搜索时,不会跳转到该人名的介绍页面,而会跳转到选择页面,让其选择以下几个相同人名的超链接进行跳转。所以在搜索前必须加一步判断操作,如果是同义词那么优先选择超链接中包含中国、内地、演员、歌手的那条超链接进行跳转。还需要注意的细节是,因为是从基础人名扩展六层关系,如果这个人名在百度百科中找不到其第一层关系信息,那就没有继续向下扩展的必要,可以直接从扩展名单中将其删去。
跳转之后,就可以正常按照网页分析,明确关系信息位于的标签位置,进行Xpath解析,将明星关系信息先保存与list列表中,最后统一写出为txt文件。
前端后端实现框架
后端
后端实现过程:利用C++语言实现后端算法核心代码,需要将后端代码嵌入Web服务开发框架中,因此选择了Oatpp这种轻量级web开发框架。
Oatpp框架在github开源,可以按照官方文档介绍下载安装。
Oatpp框架下主要包含:与前端进行交互的controller层,定义实体类的dto层,以及框架核心启动类App.cpp。
首先,将基于图模型的任意两点间的关联查询算法的核心代码作为实体类定义,置于dto类中。然后在Oatpp的启动类中申明全局变量Graph g,当Oatpp框架启动时,就会调用图模型的构建函数,读取源数据集,构建相应的图模型存于内存中。
其次,设计与前端交互的dto类的结构体,其结构体如图所示。

Mydto结构体中包括需要返回的响应状态statusCode,导出子图的所有关联关系message,导出子图中包含的节点列表nodes,源节点和目标节点的id号sourceTarget。Mydto最终以json字符串的形式发送给前端。
然后设计合理的API接口,保证返回的json数据中包含节点以及节点之间的关联关系。设计的API接口主要如下。
前端
前端使用Vue3.0 框架+d3.js可视化图表库,可以实现节点图的动态拖拽
成果展示
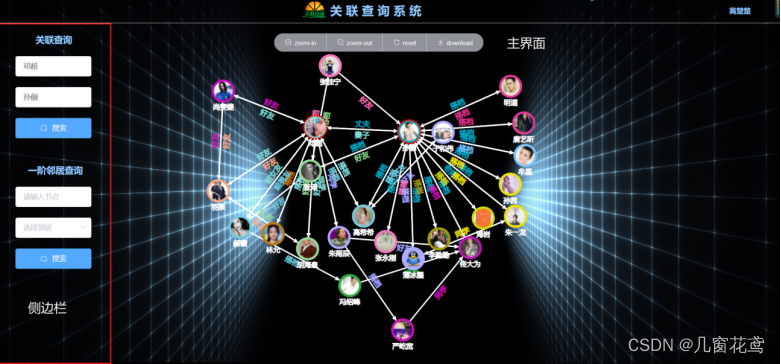
本系统已经部署到云服务上,可以通过公网ip:175.178.53.125 访问。
相关代码开源地址:前后端代码















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









