









2. Hadoop
2.1 Hadoop简介
-
Hadoop可以支持多种编程语言:c,c++,java,python
-
Hadoop用java语言开发,具有跨平台特性
-
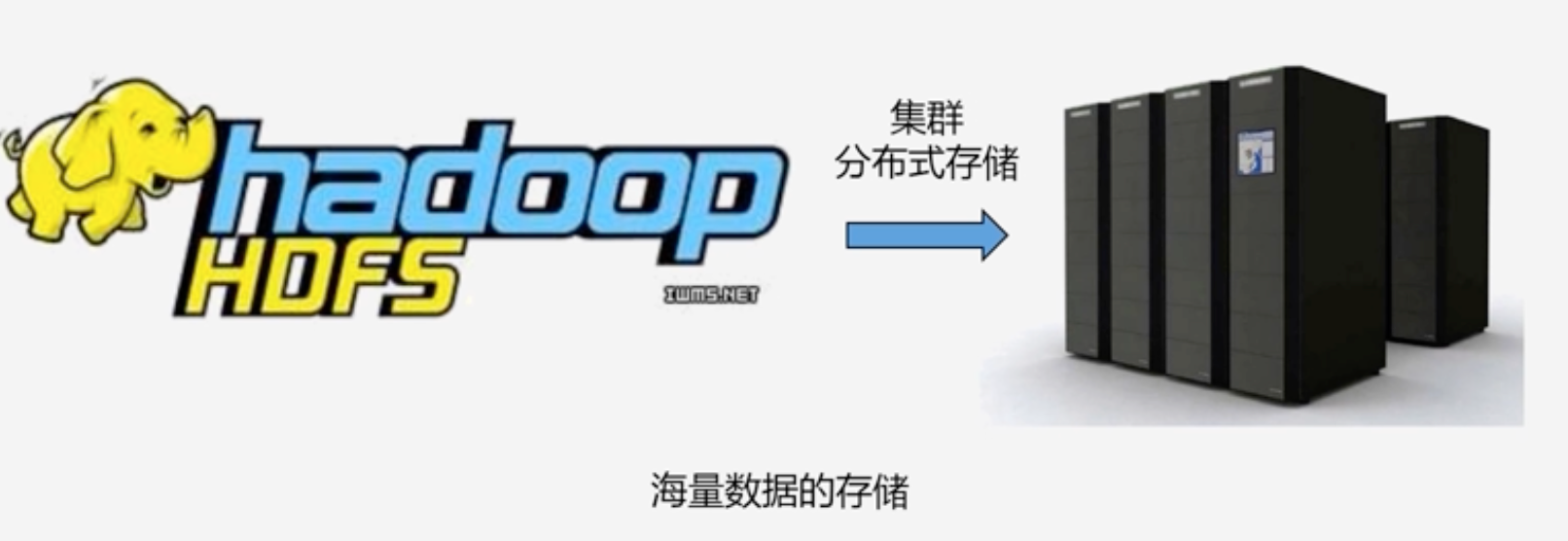
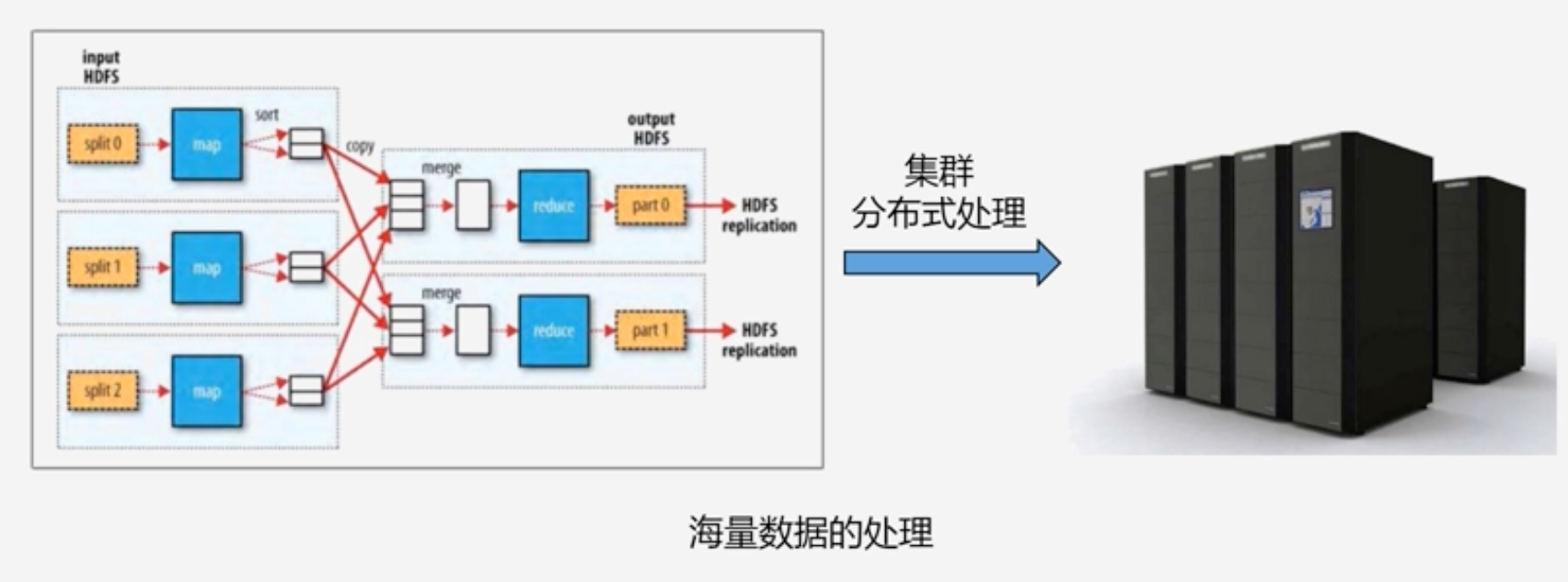
Hadoop两大核心:HDFS+MapReduce 分别解决了海量数据的分布式存储和分布式处理问题
-
2003年,谷歌发布了分布式文件系统GIS,2004年Hadoop将其纳入自己平台下开源实现
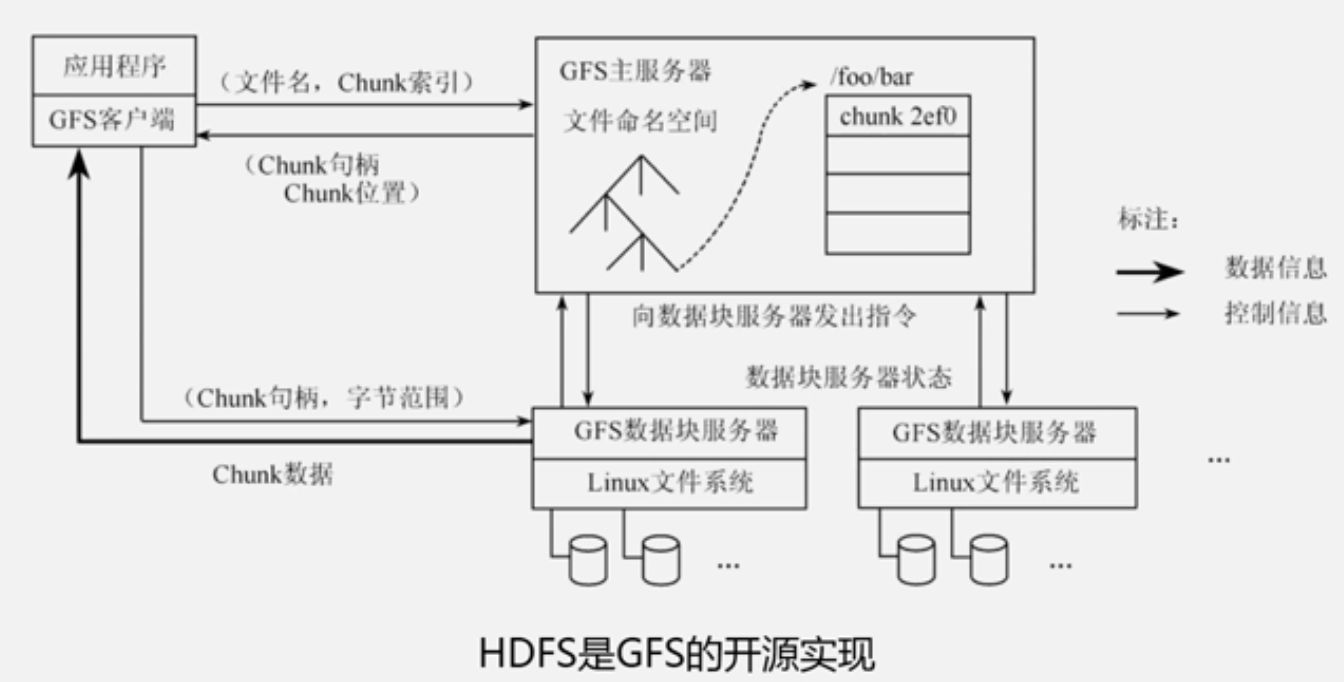
-
2004年,谷歌发布了分布式的并行编程框架MapReduce
-
Hadoop特性:
- Hadoop具有很高的可靠性:多台机器构成集群,部分机器发生故障,剩余机器可以继续对外提供服务
- Hadoop具有很高的效率:可以将成百上千的机器一起计算
- Hadoop具有很好的扩展性:可以不断的在集群中增加机器
- Hadoop的成本非常低:高性能计算(High Performance Computing 缩写HPC)
- 其可以采用普通PC机构成一个集群
-
Hadoop应用现状:
-
FaceBook公司采用Hadoop集群用于日志处理、推荐系统和数据仓库等方面
-
2.2 Hadoop版本演变

-
Hadoop1.0的两大核心:HDFS和MapReduce
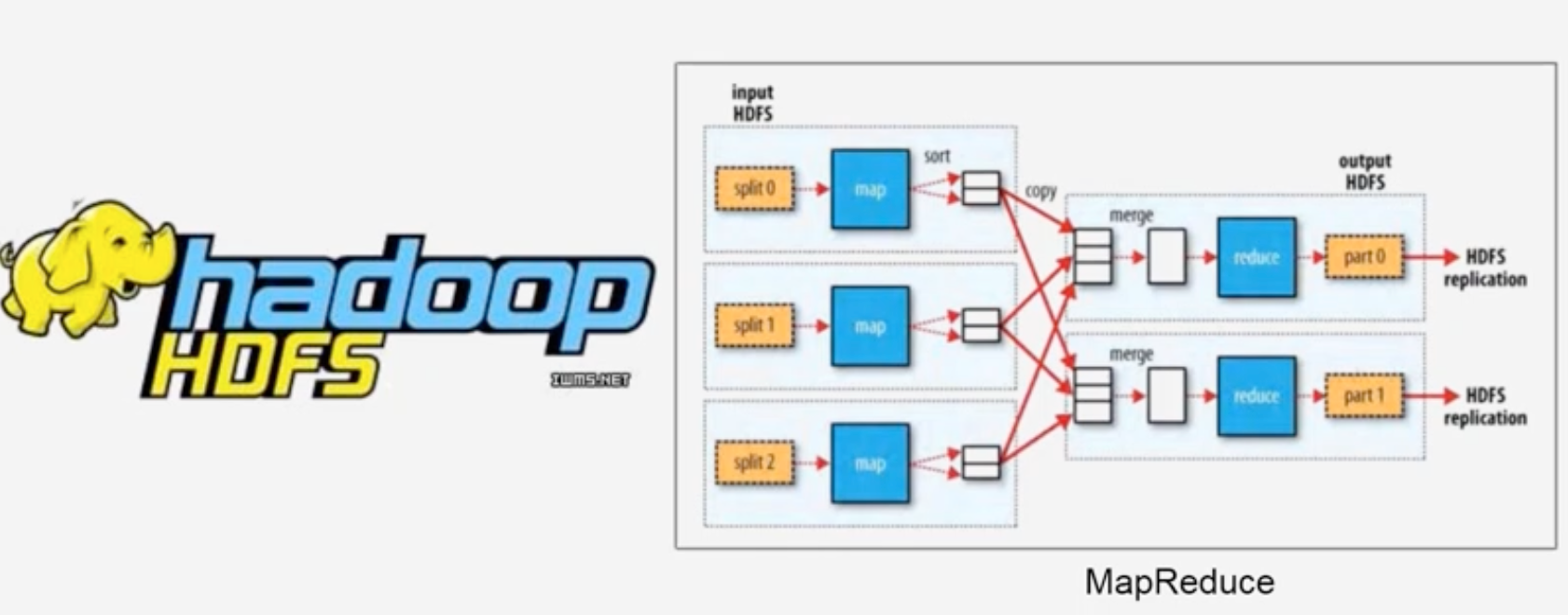
-
Hadoop2.0对mapreduce的资源调度做出划分
- 将1.0版本中关于资源调度的模块单独抽出来,变成一个模块Yarn
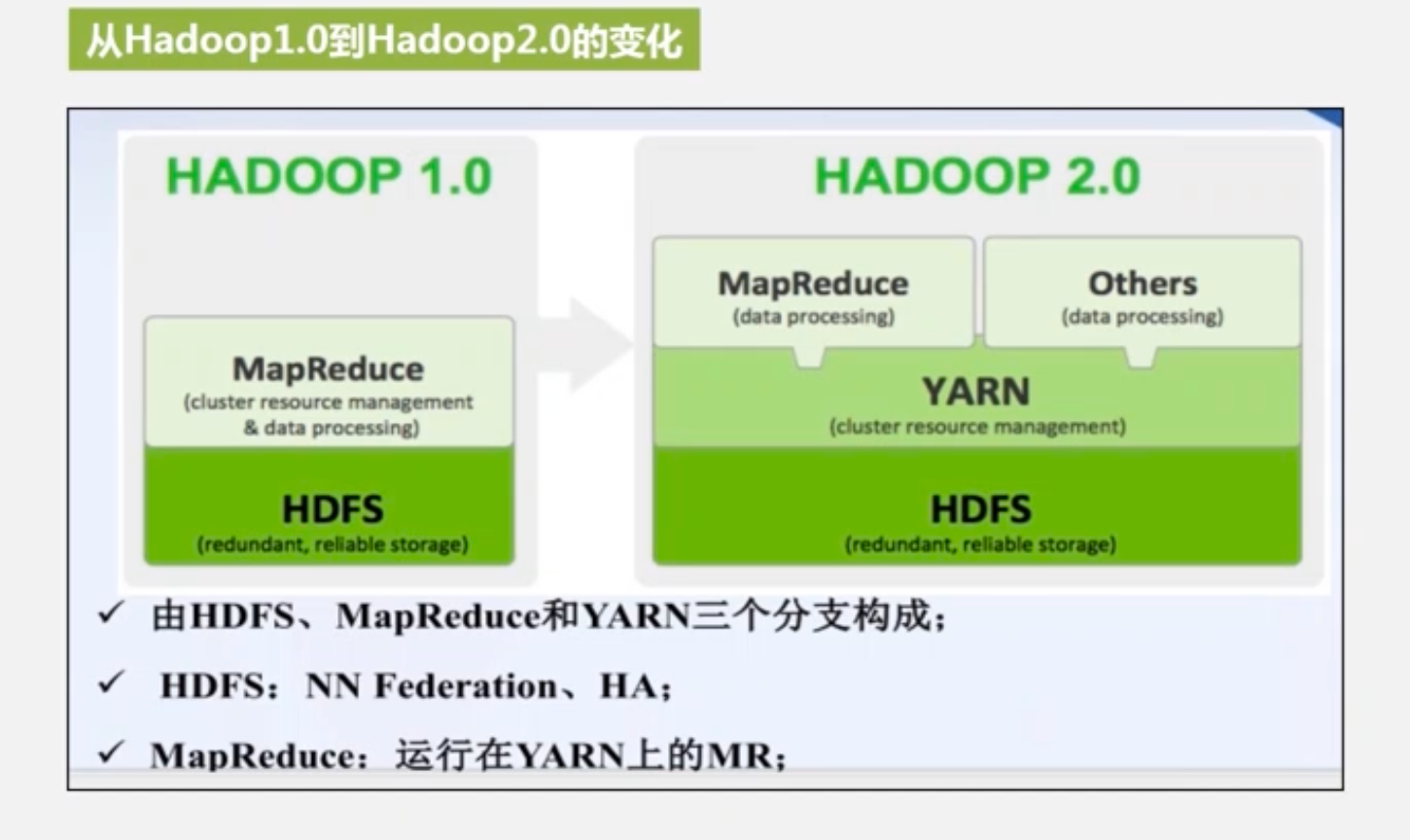
-
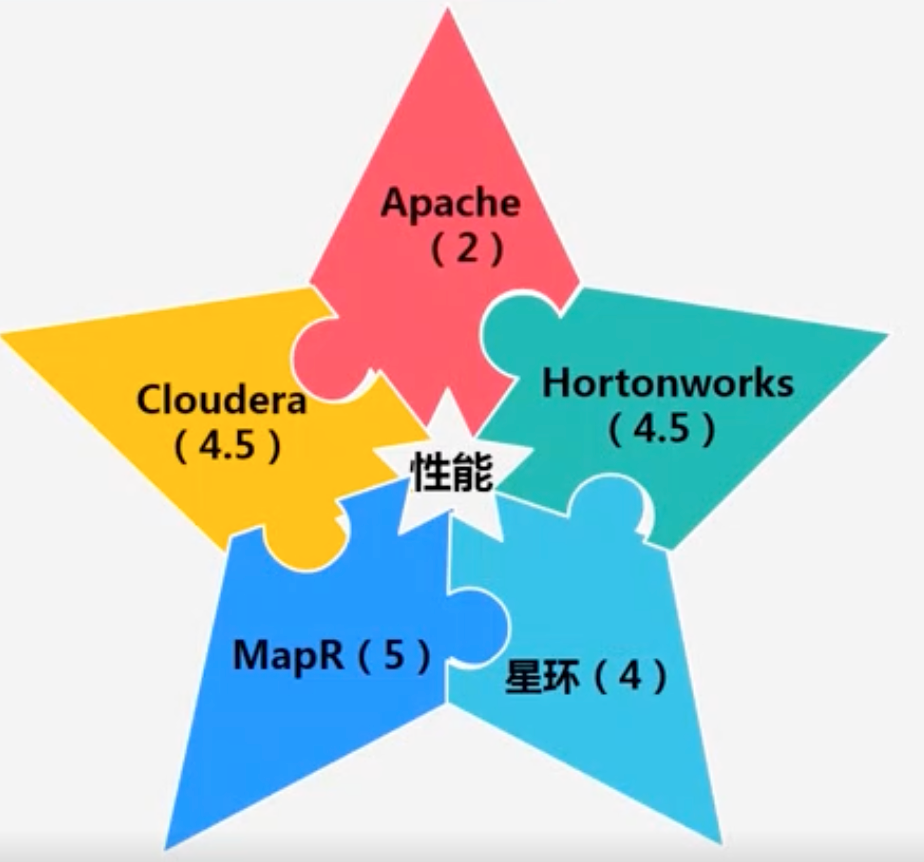
Hadoop的发行版:Hortonworks(企业版)、cloudera CDH:Cloudera Distribution Hadoop、MapR
- 易用性
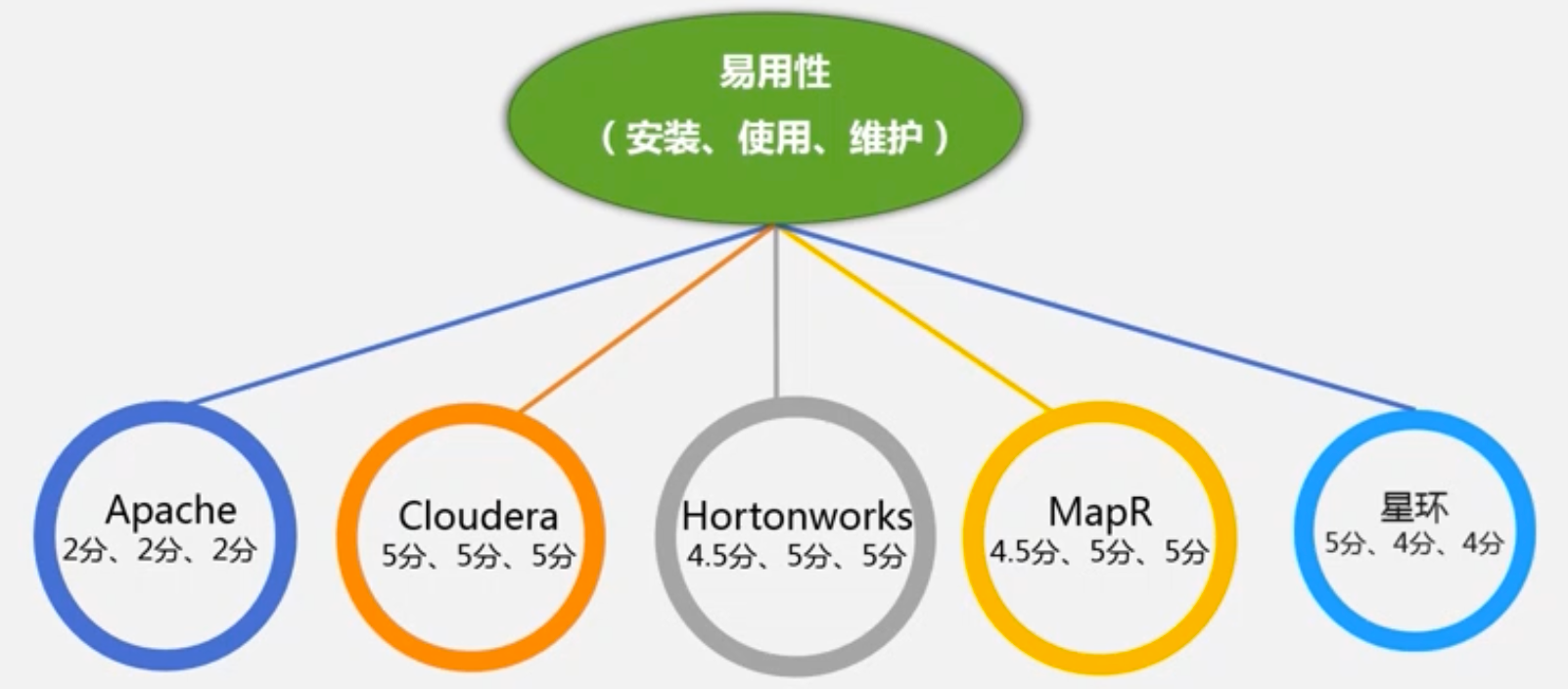
- 性能
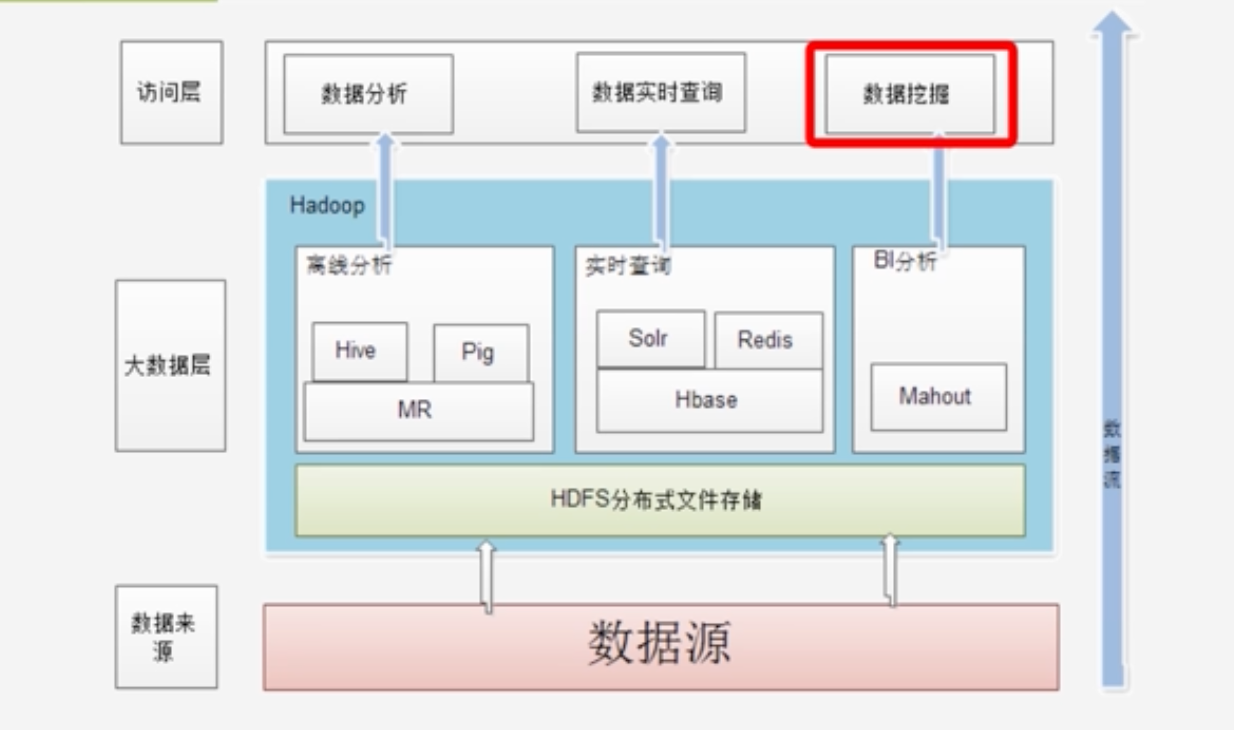
2.3 Hadoop项目结构
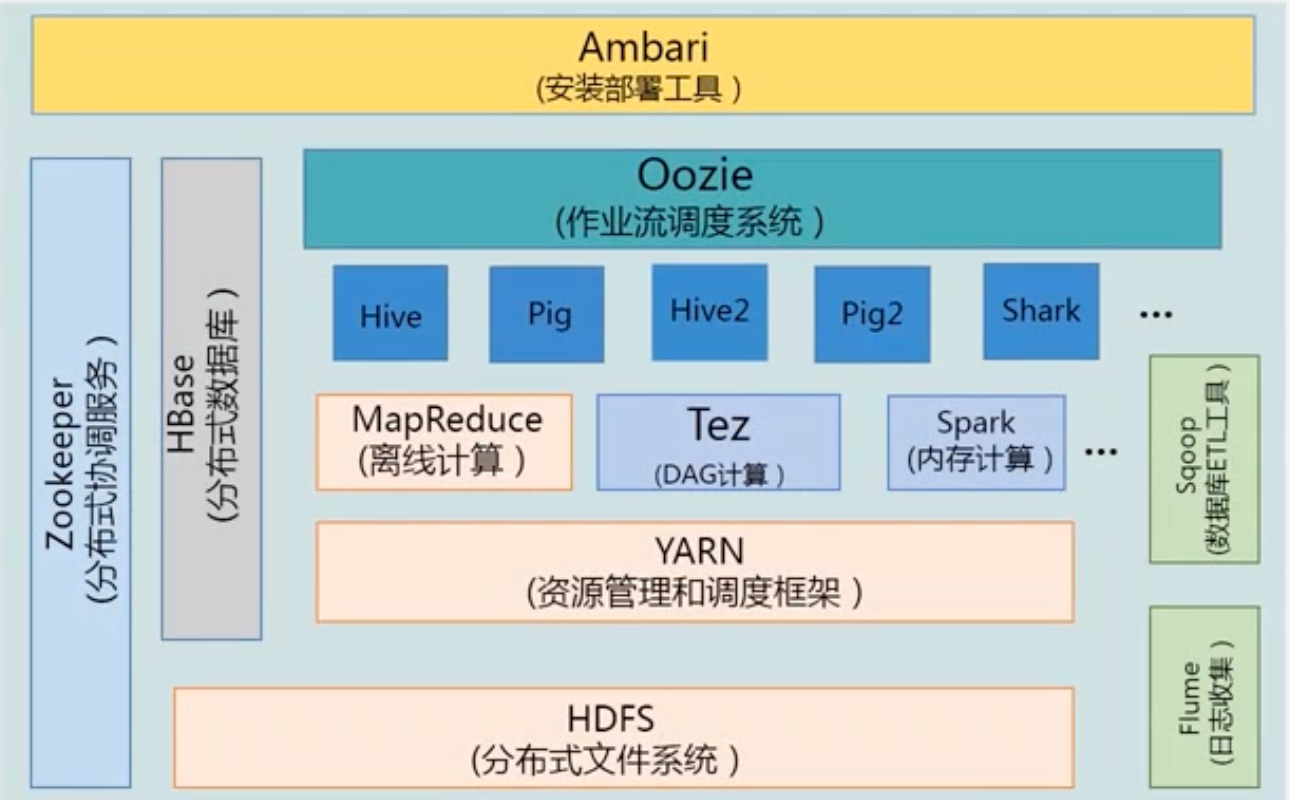
- YARN:负责资源调度:内存/CPU/带宽等
- Spark:类似MapReduce的通用并行框架,区别是Spark是基于内存计算的、MapReduce是基于磁盘计算的
- Hive:是hadoop上的数据仓库
- Hive:把sql语句转换为MapReduce作业
- Pig:一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin
- Oozie:需要不同应用程序配合完成工作,需要工作流管理系统来完成
- Zookeeper:分布式锁,一致性管理,提供分布式协调一致性服务
- HBase:是Hadoop上的非关系行的分布式数据库,支持实时应用
- Flume:日志采集
- Sqoop:是Hadoop和传统数据库之间的数据传递
- Amber:Hadoop快速部署工具,支持Hadoop集群的供应、管理和监控
2.4 Hadoop集群的部署和使用
-
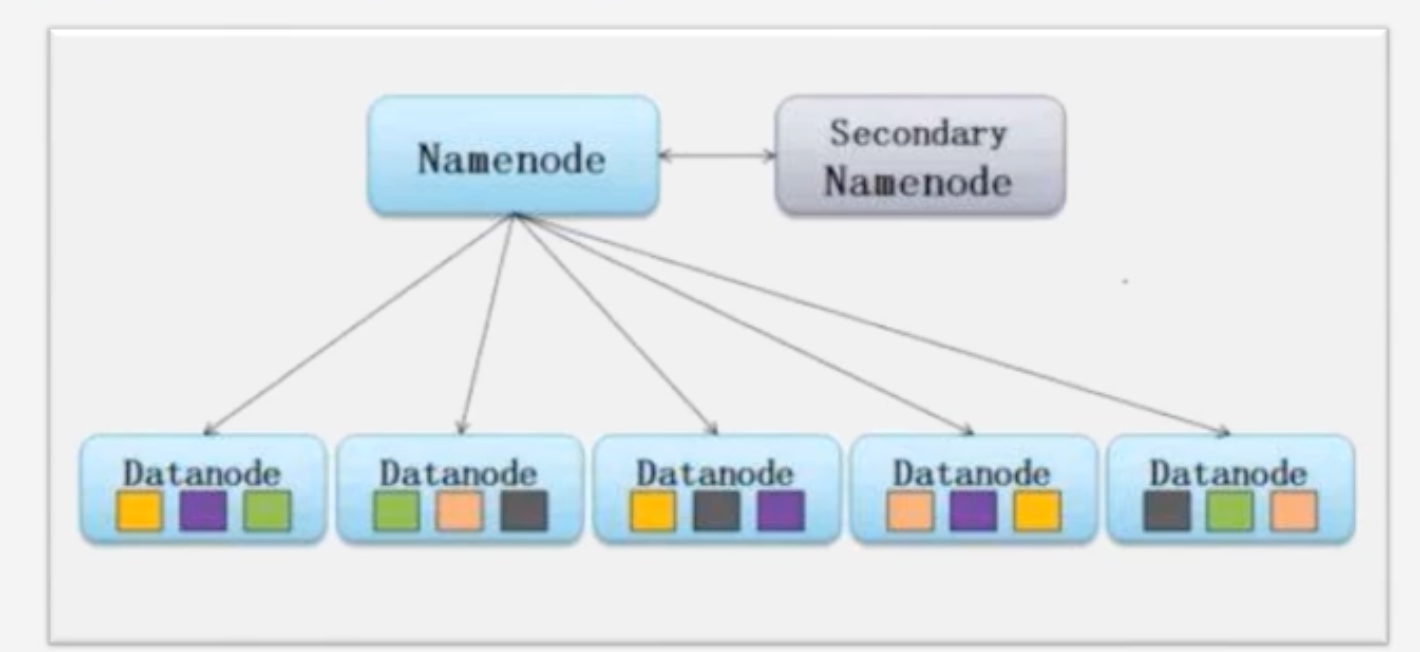
集群硬件配置:NameNode和DataNode
-
MapReduce有两大核心组建:JobTracker和TaskTracker
- JobTracker负责MapReduce的作业管理:将MapReduce的大作业拆分成小作业分发到各个机器上去执行
- 而不同的机器上的协调问题就是TaskTracker:每个TaskTracker负责跟踪执行自己负责的那部分作业
-
冷备份:SecondNameNode
-
NameNode出现故障之后SecondNameNode无法马上顶上去,需要一个恢复的过程
-
-
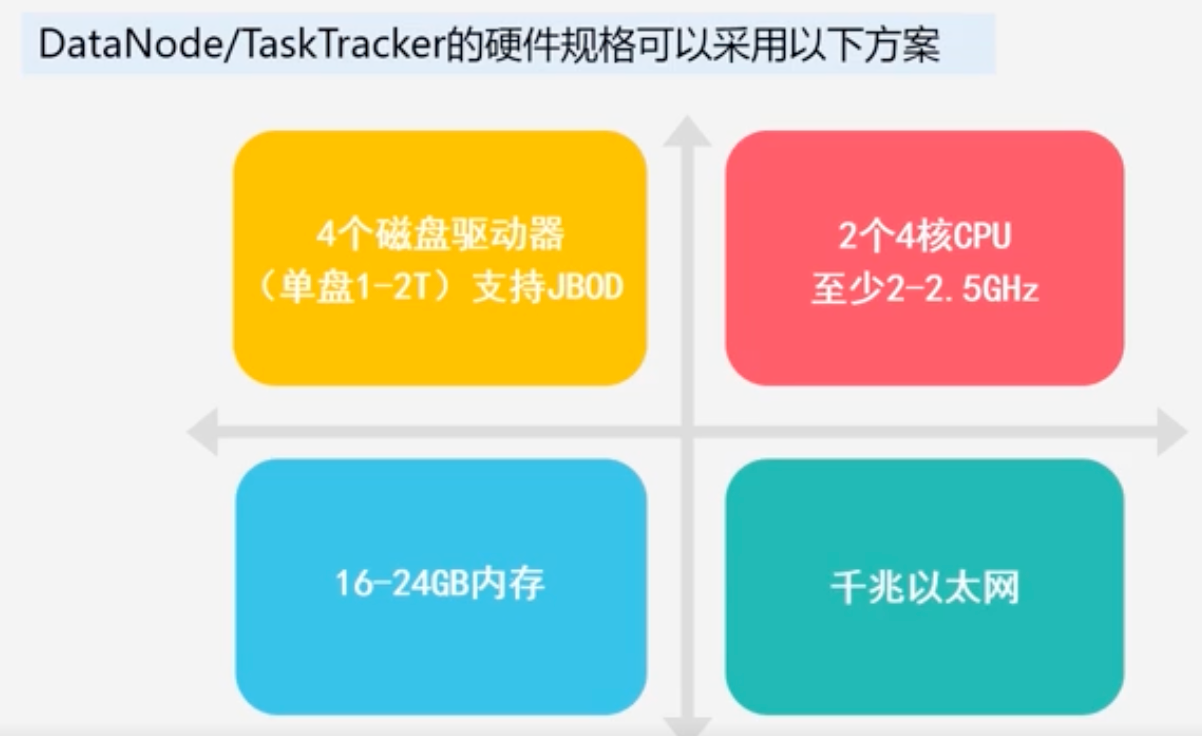
TaskTracker和DataNode可能在同一个机器上面,即这个机器既是TaskTracker又是DataNode
-
TaskTracker和DataNode的集群硬件配置
-
NameNode总管家
- 管理各种元数据并提供服务
- NameNode里面有很多元数据都是直接保存在内存当中的

- 小集群可以将secondNameNode和NameNode放在一起,若是集群较大SecondNameNode需要单独设置一台服务器
-
集群规模
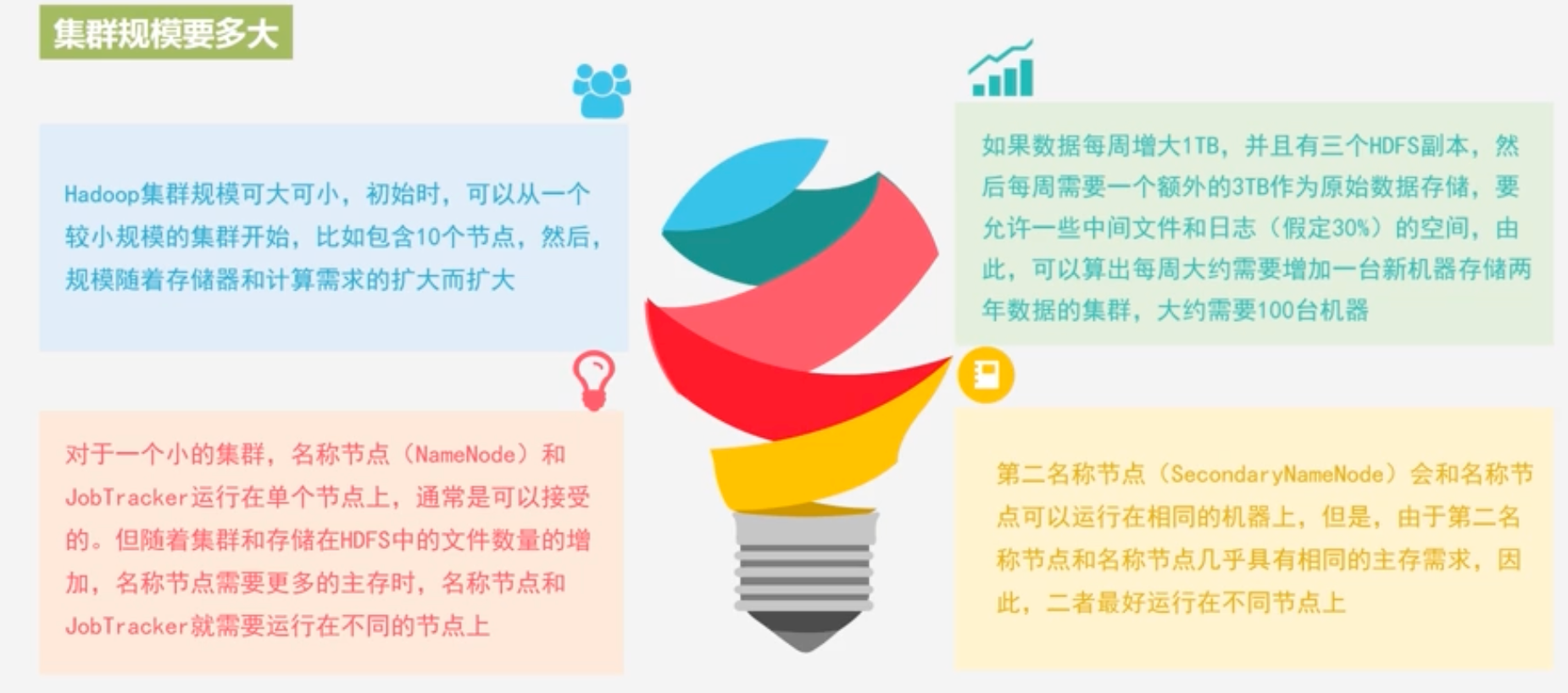
-
Hadoop集群的部署和使用
- Hadoop自带的一些基准测试程序,被打包在测试程序JAR文件中
- 用TestDFSIO基准测试,来测试HDFS的IO性能
- 用排序测试MapReduce:Hadoop自带的一个部分排序的程序,这个测试过程的整个数据集都会通过洗牌(Shuffle)传输至Reducer,可以充分测试MapReduce的性能














 3160
3160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









