









文章目录
7. MapReduce
7.1 MapReduce简介
MapReduce是一种分布式并行编程框架
- 数据处理能力提升的两条路线:
- 单核CPU到双核到四核到八核
- 分布式并行编程
7.1.1 分布式并行编程
-
借助一个集群通过堕胎机器同时并行处理大规模数据集
-
相关的并行编程框架
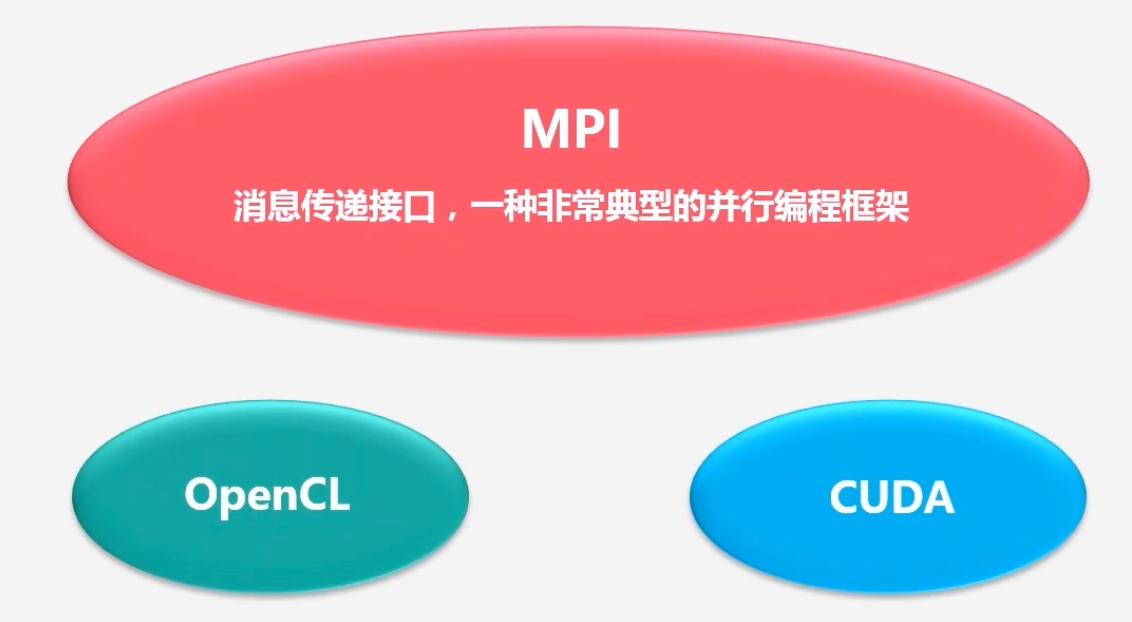
-
并行编程模型和传统的并行编程框架的区别

7.1.2 MapReduce模型简介
-
MapReduce包含两大函数:Map和Reduce
-
MapReduce策略:
-
采用分而治之的做法
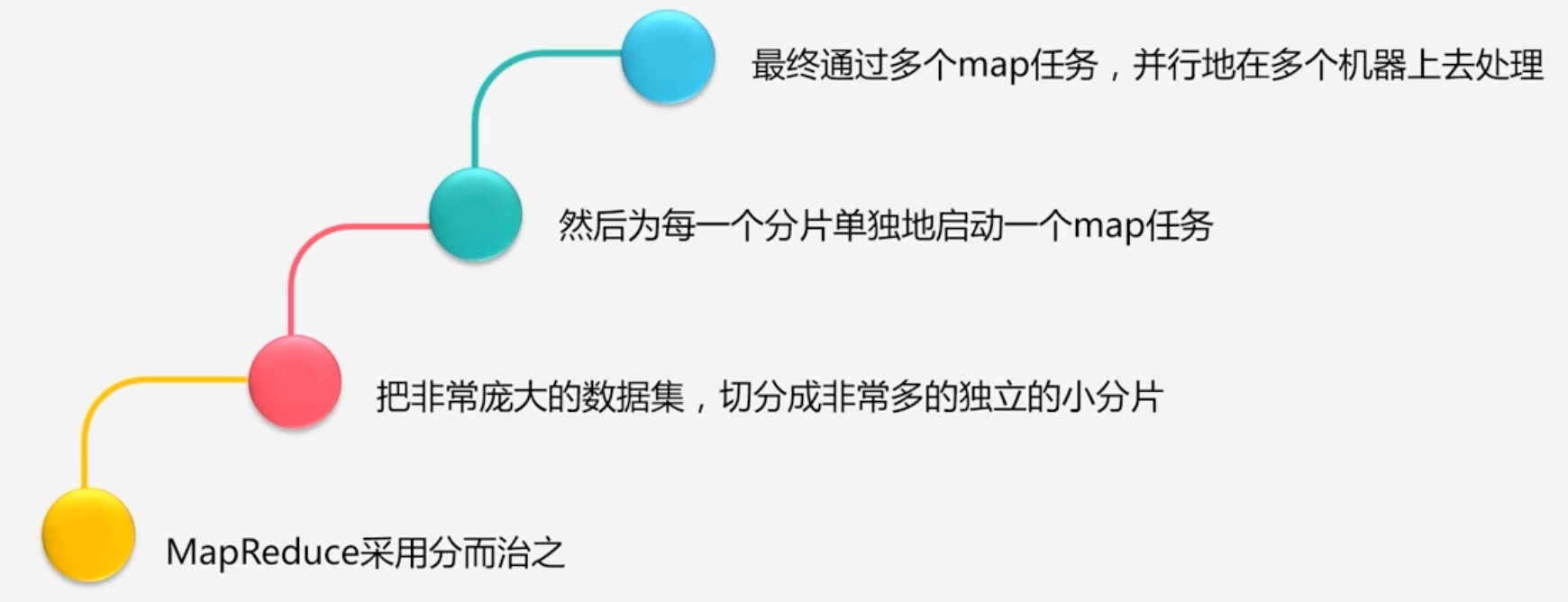
-
-
MapReduce理念
-
计算向数据靠拢,而不是数据向计算靠拢
-
什么事数据向计算靠拢?
-
即完成一次数据分析时,选择一个计算节点,把运行数据分析的程序放在计算节点上运行
-
然后把它所涉及的数据,全部从各个不同的节点上面拉过来,传输到计算发生的地方
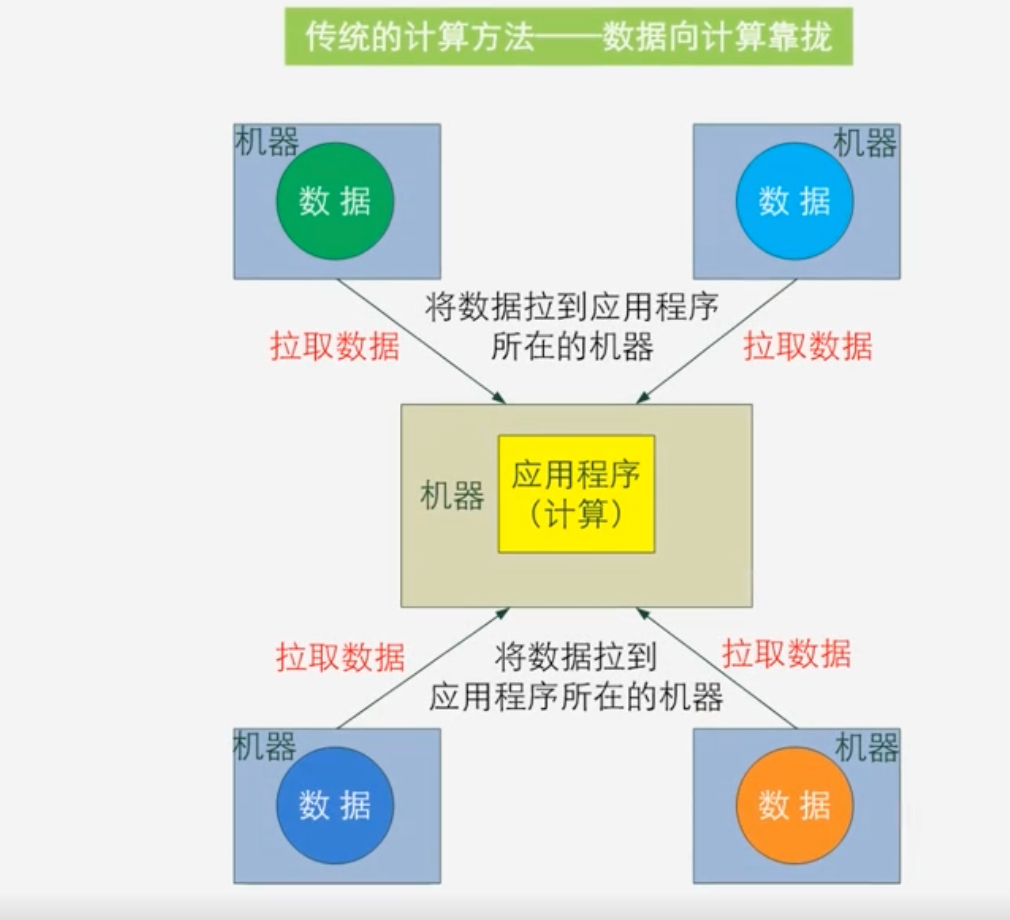
-
MapReduce采用计算向数据靠拢的方式
- 即会寻找离这个数据节点最近的Map机器做这个机器上的数据分析
- 通常Map机器和数据在同一个台机器上,从而大大减少网络中的数据传输靠开销
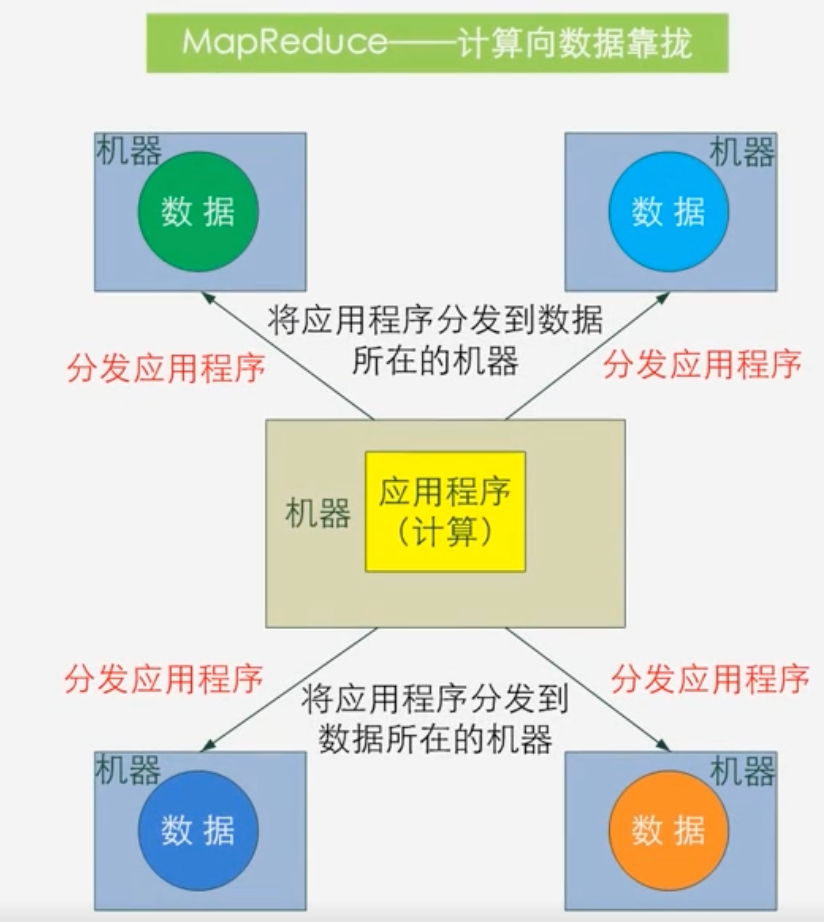
-
MapReduce架构:Master/Slave的架构
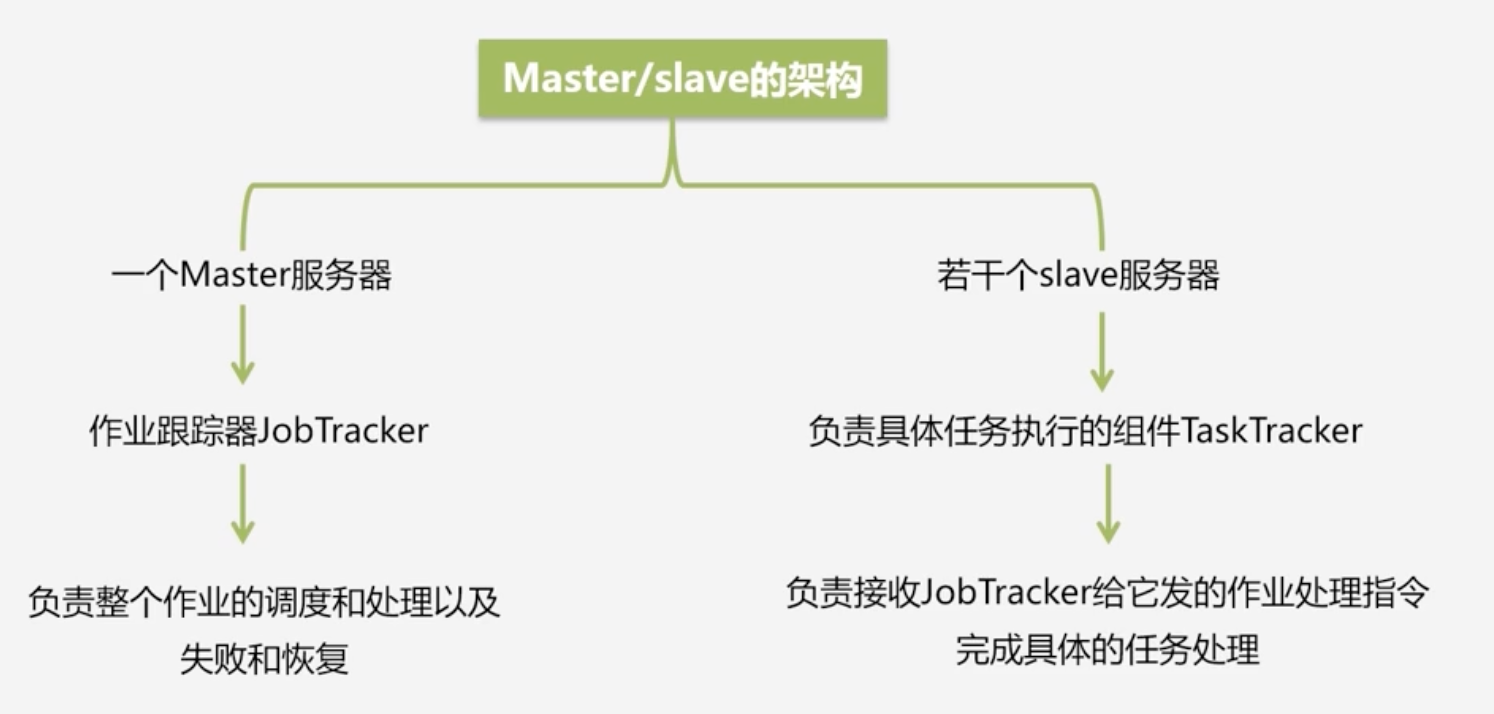
-
-
-
-
Map函数和Reduce函数
-
Map函数
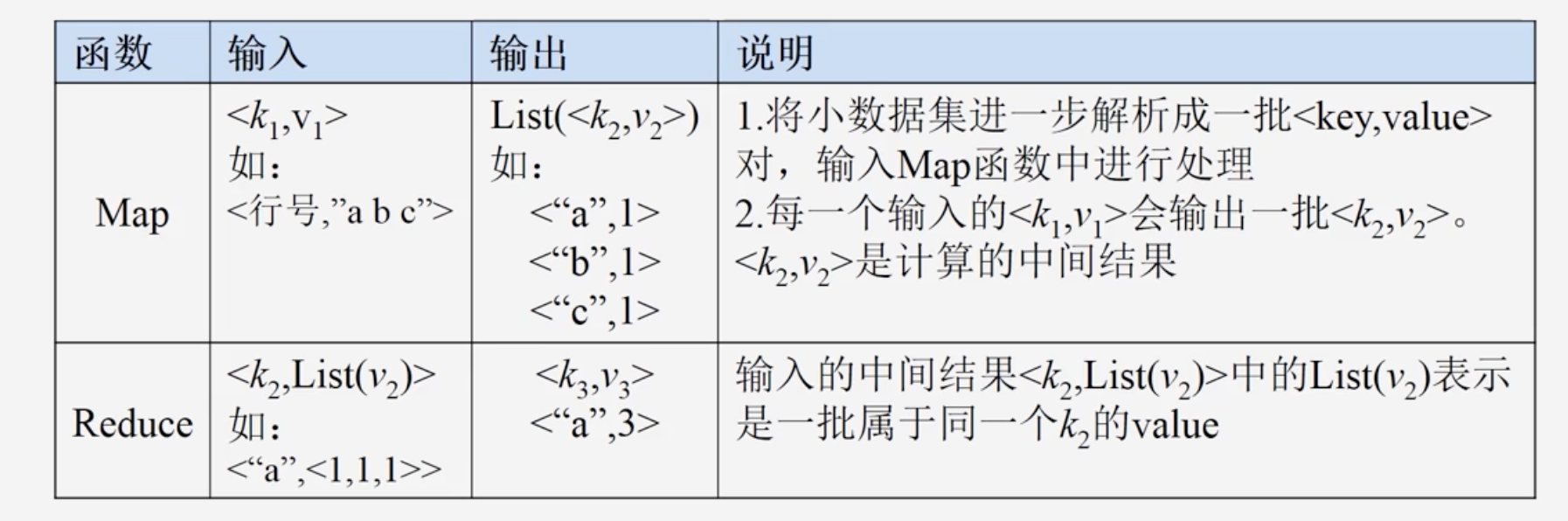
-
Reduce函数

-
7.2 MapReduce体系结构
-
MapReduce体系结构
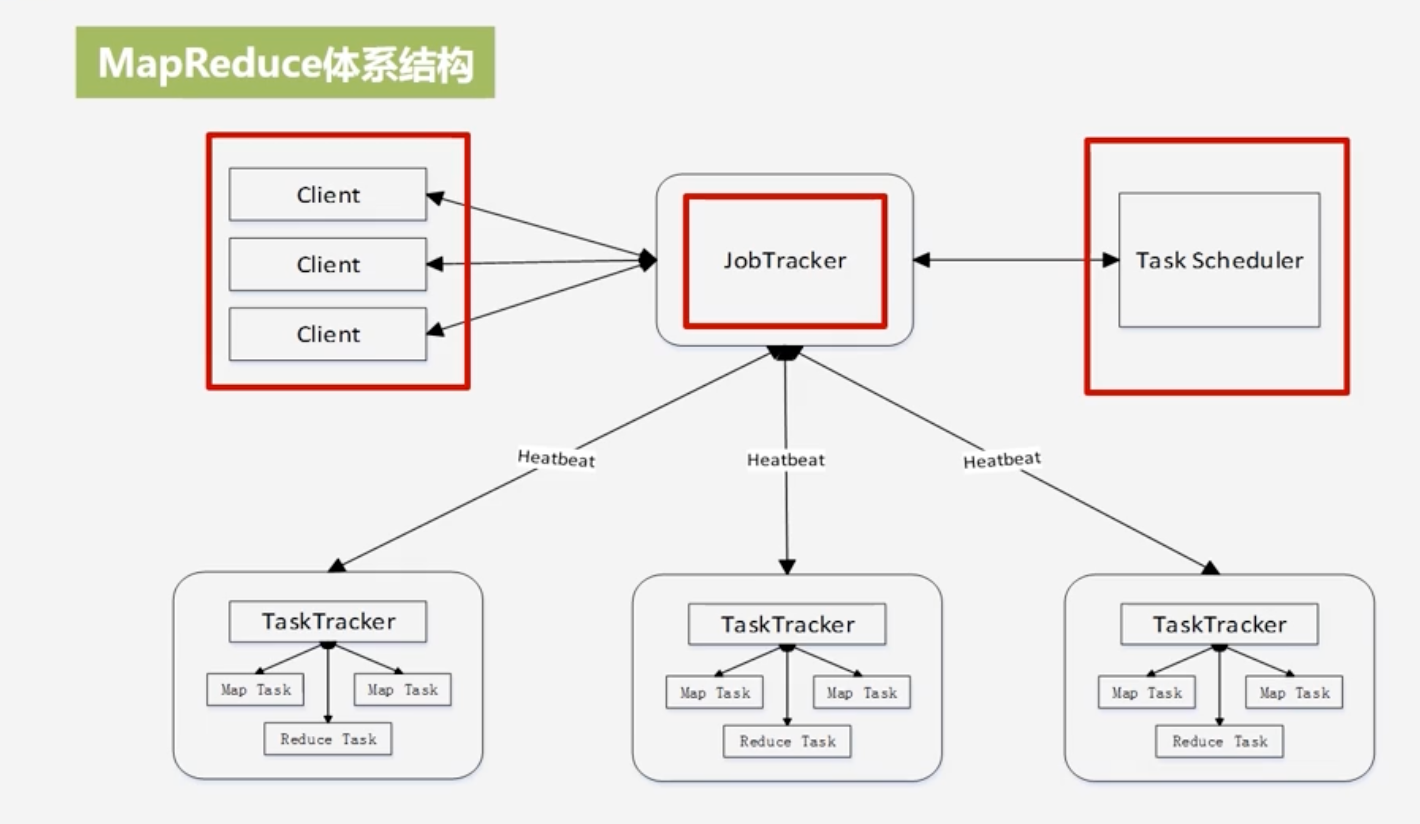
-
Client(客户端)
- 通过client可以提交用户编写的应用程序,用户通过它将应用程序交给JobTracker端
- 通过这些Client用户也可以通过它提供一些接口去查看当前提交作业的运行状态
-
JobTracker(作业跟踪器)
- 负责资源的监控和作业的调度
- 监控底层的其他的TaskTracker以及当前运行的Job的健康状况
- 一旦探测到失败的情况就把这个任务转移到其他节点继续执行跟踪任务执行进度和资源使用量
-
TaskTracker(任务调度器)
-
执行具体的相关任务一般接受JobTracker发送过来的命令
-
把一些自己的资源使用情况,以及任务的运行进度通过心跳的方式,也就是heartbeat发送给JobTracker
-
使用slot概念,将自己机器的cpu、内存资源等分为slot
- 两种类型的slot不互相通用,map类型的slot不能用了reduce任务,这是1.0的缺陷
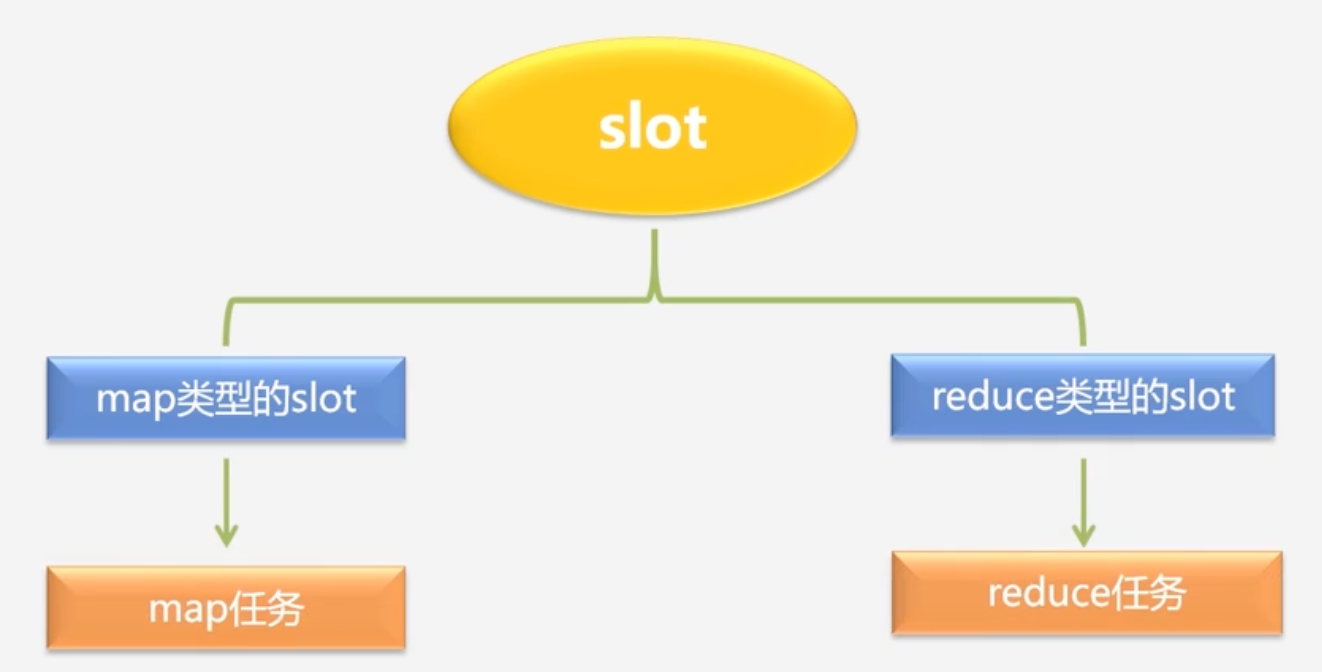
-
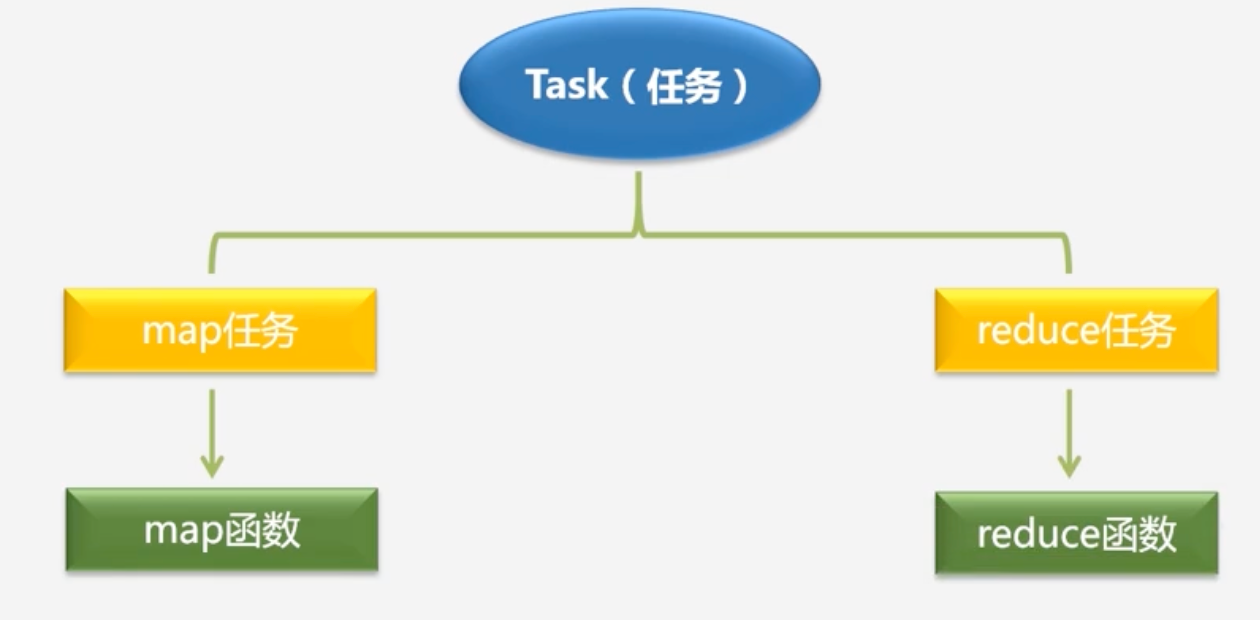
Task任务也有两种:map任务和reduce任务
-
-
7.3 MapReduce工作流程概述
-
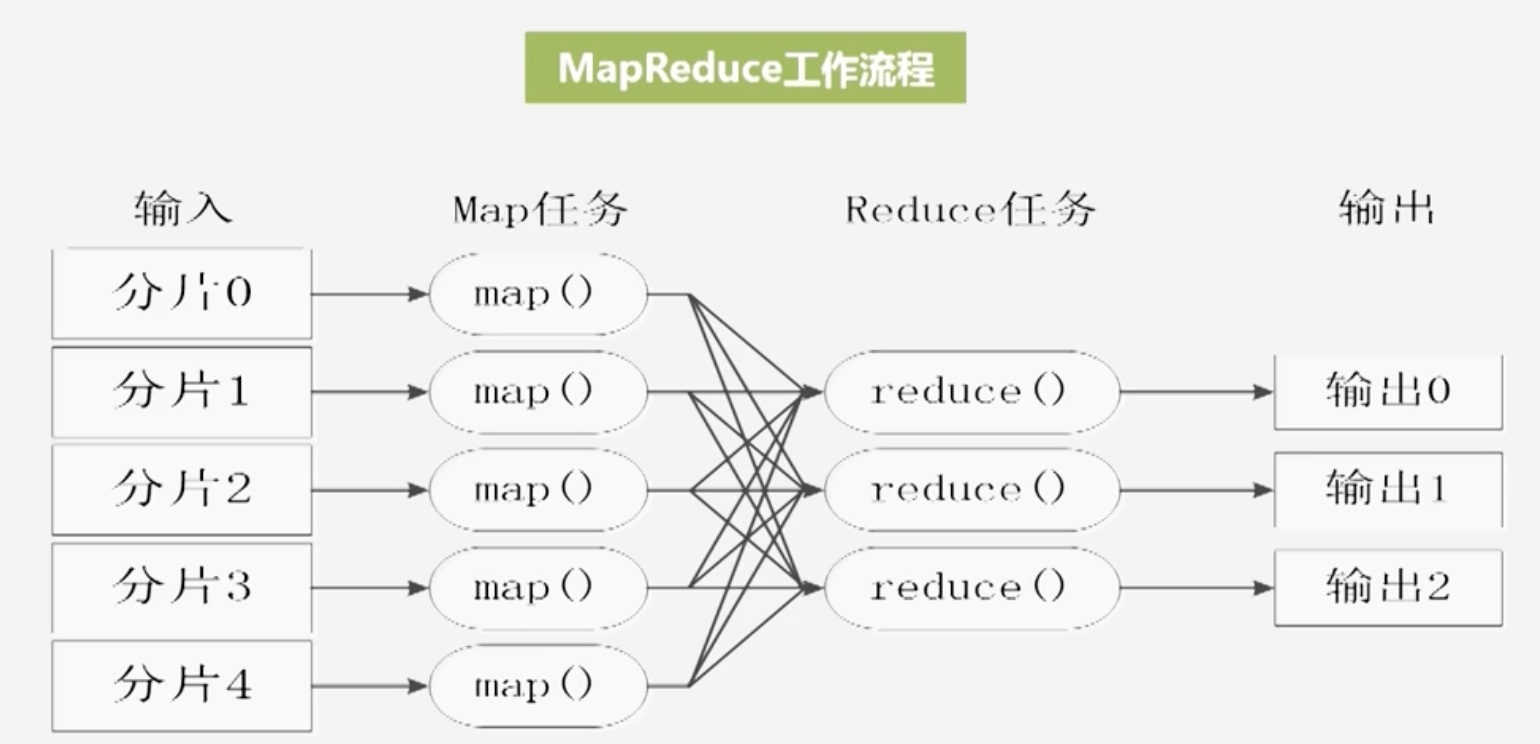
MapReduce工作流程
- 将数据分片处理,利用map进行输入(key,value)类型,然后通过Reduce任务输出(key,value)类型到HDFS
- 将map的结果进行排序、归并、合并(shuffle),结束后将结果分发给相应的Reduce处理
- 注意不同map任务之间不进行通信,不同Reduce任务之间也不会进行信息交换
-
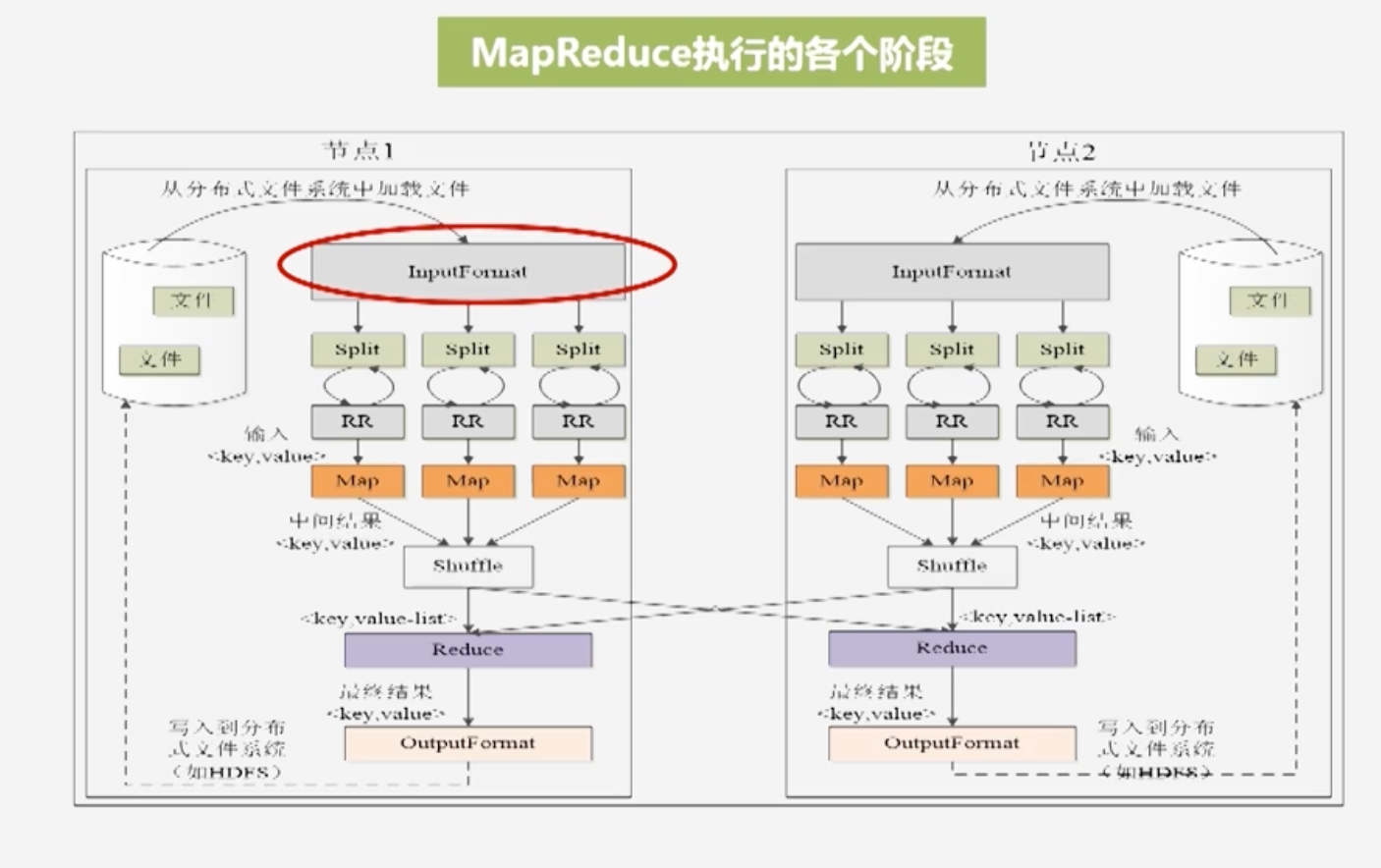
MapReduce执行的各个阶段
- 数据通过InputFormat从HDFS读取文件,并对输入进行格式验证
- 将大数据集切分成多个split分片,不是物理上的切分,只是逻辑上的切分
- Record Reader(RR):记录阅读器,根据分片的距离位置信息,从HDFS的各块将数据分片的信息读出,输出为(key,value)形式,作为map的输入
- Map:用户撰写的处理逻辑,生成一系列的(key,value)的中间结果
- 通过shuffle(分区,排序,合并)过程,将相关的键值对分发给相应的Reduce任务处理
- 编写Reduce处理逻辑,任务结束后,分析结果以(key,value)形式显示
- outoutformat检查输出格式,写入HDFS系统
-
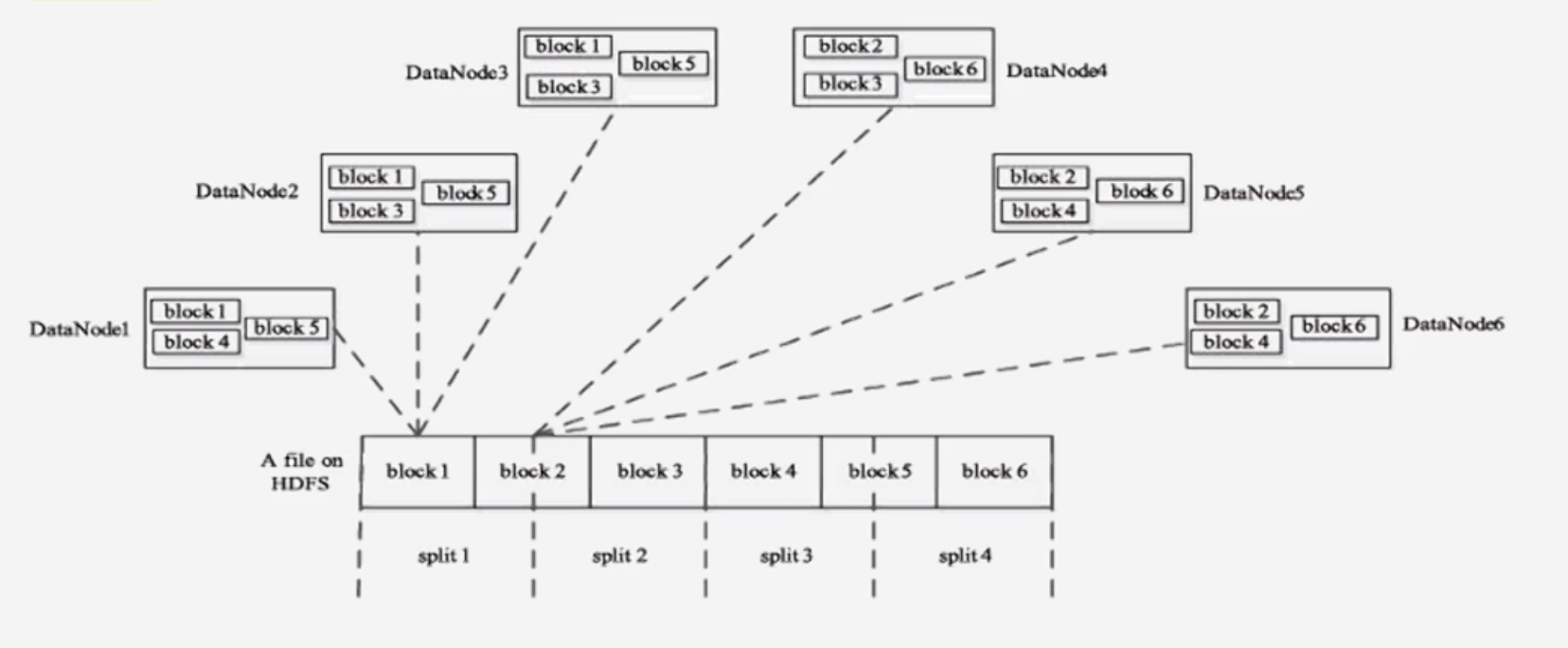
分片的具体过程
-
一个大文件在HDFS中可能由多个块组成,如下图例子在物理上被分为6块,但在逻辑上通过split分块四块内容
-
每个分片都是一个map任务,如果分片过少,影响并行效率;若分片过多,map切换耗费相关管理资源,影响执行效率
-
一般来说会将一个块的大小作为HDFS的分片大小,因为假如block1和block2不在一个机器上面,block1运行split1的map任务,此时
需要将数据从block2机器存到block1所在的机器,会出现额外的数据开销
-
-
Reduce任务的数量
- 最优的Reduce任务个数取决于集群中可用的Reduce任务槽(slot)的数目
- 通常设置比reduce任务槽数目稍微小一些的Reduce任务个数(这样可以预留一些系统资源处理可能发生的错误)
7.4 Shuffle过程原理
-
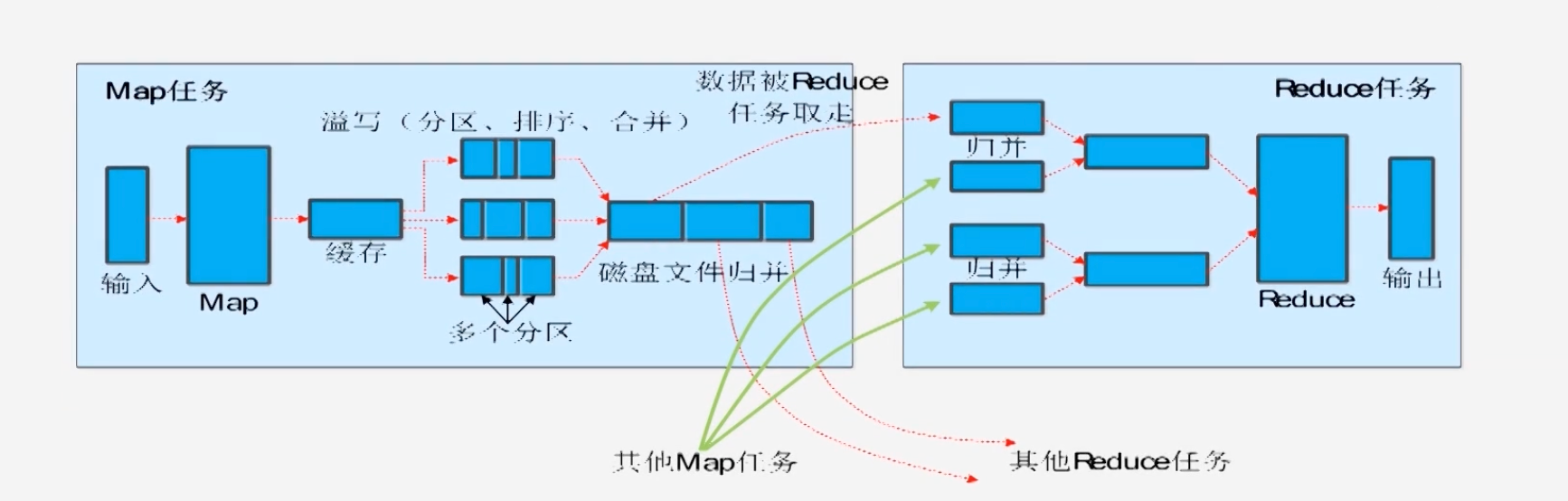
Shuffle过程简介
- HDFS输入数据,分片操作,每个分片都启动一个Map任务,Map任务中包含对用户的处理逻辑
- Map输出结果(键值对),输出到缓冲区,若缓冲区满了,则发生溢写
- 溢写过程:将缓存区的数据(经过分区排序合并处理之后)写到磁盘,同时清空缓冲区
- 溢写发生多次,生成多个磁盘文件,要对这些磁盘文件做统一归并
- 归并完成后,通知Reduce任务来取走磁盘分区内的数据
- 取走后,Reduce任务要执行归并、合并操作,将合并后的数据传递给Reduce函数
- 最后输出到相应的HDFS文件系统
-
Shuffle过程分类
-
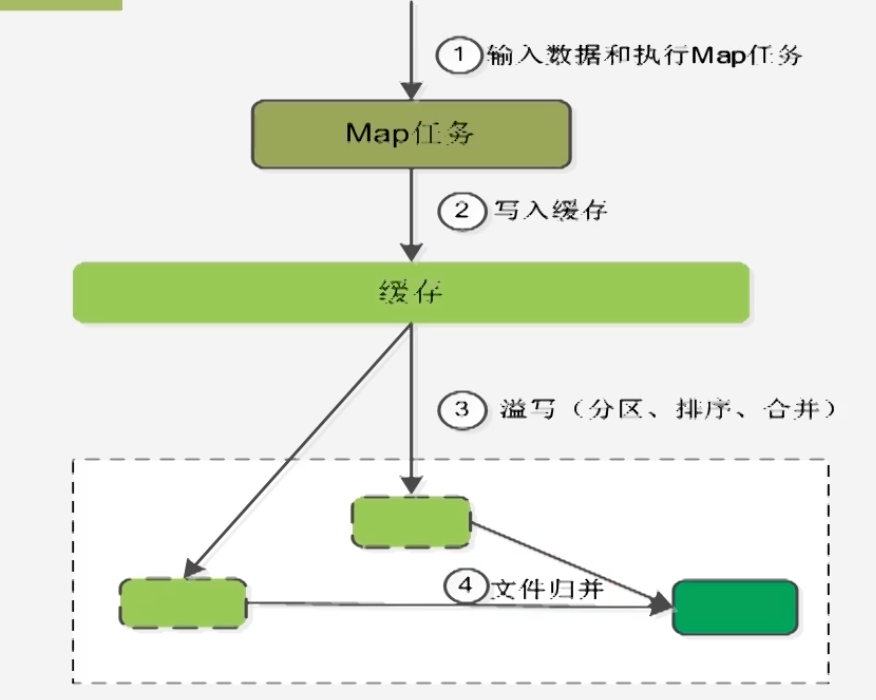
Map端的Shuffle过程
-
每个Map任务都会给其分配相应的缓存,一般来说是100M
-
如果缓存满了再启动溢写,可能会导致后来Map生成的值无法写入缓冲区,丢失值。
因此,在溢写的时候会设置一个溢写比例,例如80%,即如果写出内容占缓存比例的80%的时候启动溢写,剩余20M空间可以供给给后来生成的map
-
溢写的分区操作,主要是利用分区分给不同的Reduce任务,排序操作内部会自动完成,合并操作不是必须的,若用户定义合并操作,则会启动合并操作,如(a,1)(a,1)会被合并为(a,2)
-
-
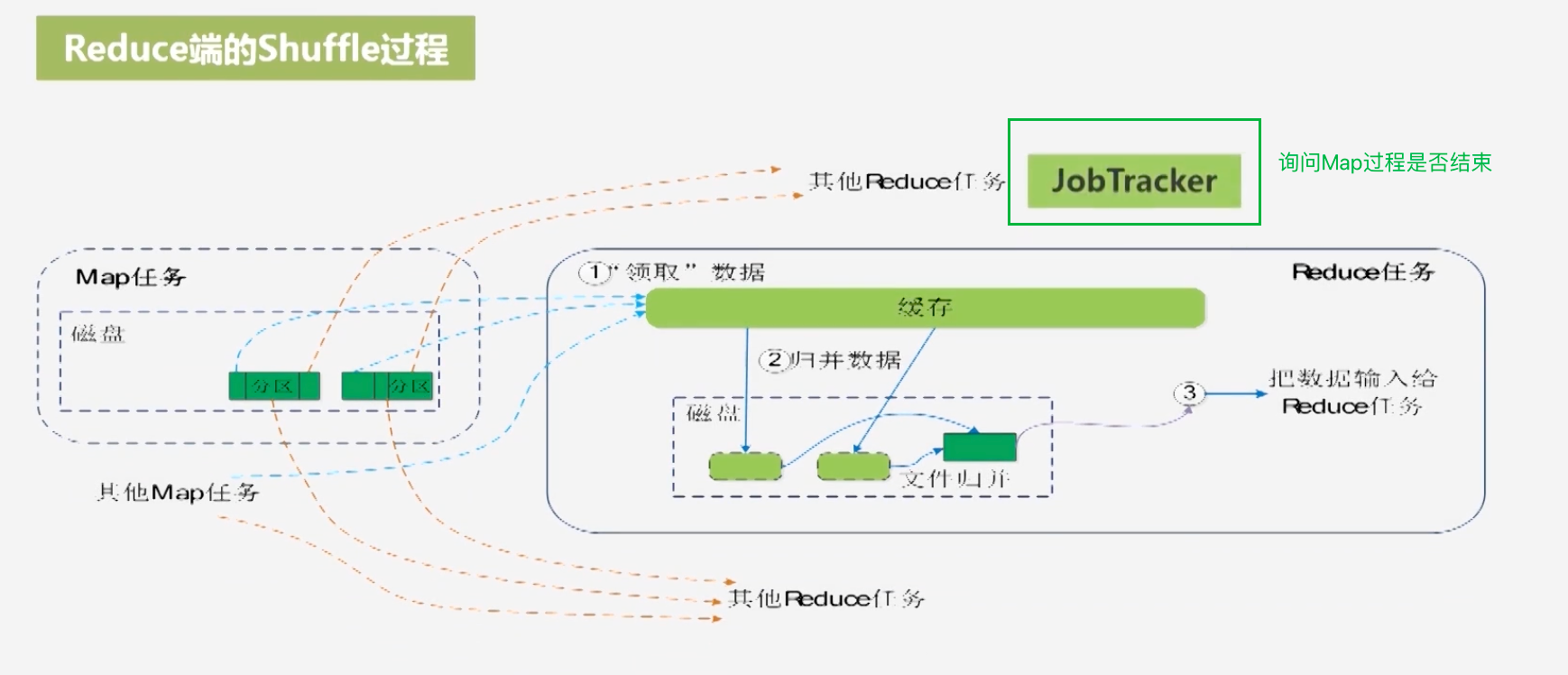
Reduce端的Shuffle过程
- 向JobTracker询问自己所需要的数据是否能够可以取出,JobTracker监测Map任务,若是任务完成了,就通知Reduce任务将任务取走
- Reduce从Map机器上将任务拉去到本地,Map任务生成的键值对是从不同的Map机器上拉去的,可以继续做归并操作
- 注意这个归并操作不同于合并,合并是将(a,1)(a,1)合并为(a,2)这种形式,归并是将多个Map中的(a,1)合并为<a,<1,1,1>>
- 所以若Map过程没有合并操作,得到的就是<a,<1,1,1>>形式数据,归并之后若是用户定义了合并操作,会将其合并为<a,3>形式数据
-
7.5 MapReduce应用程序的执行过程
-
整个执行过程
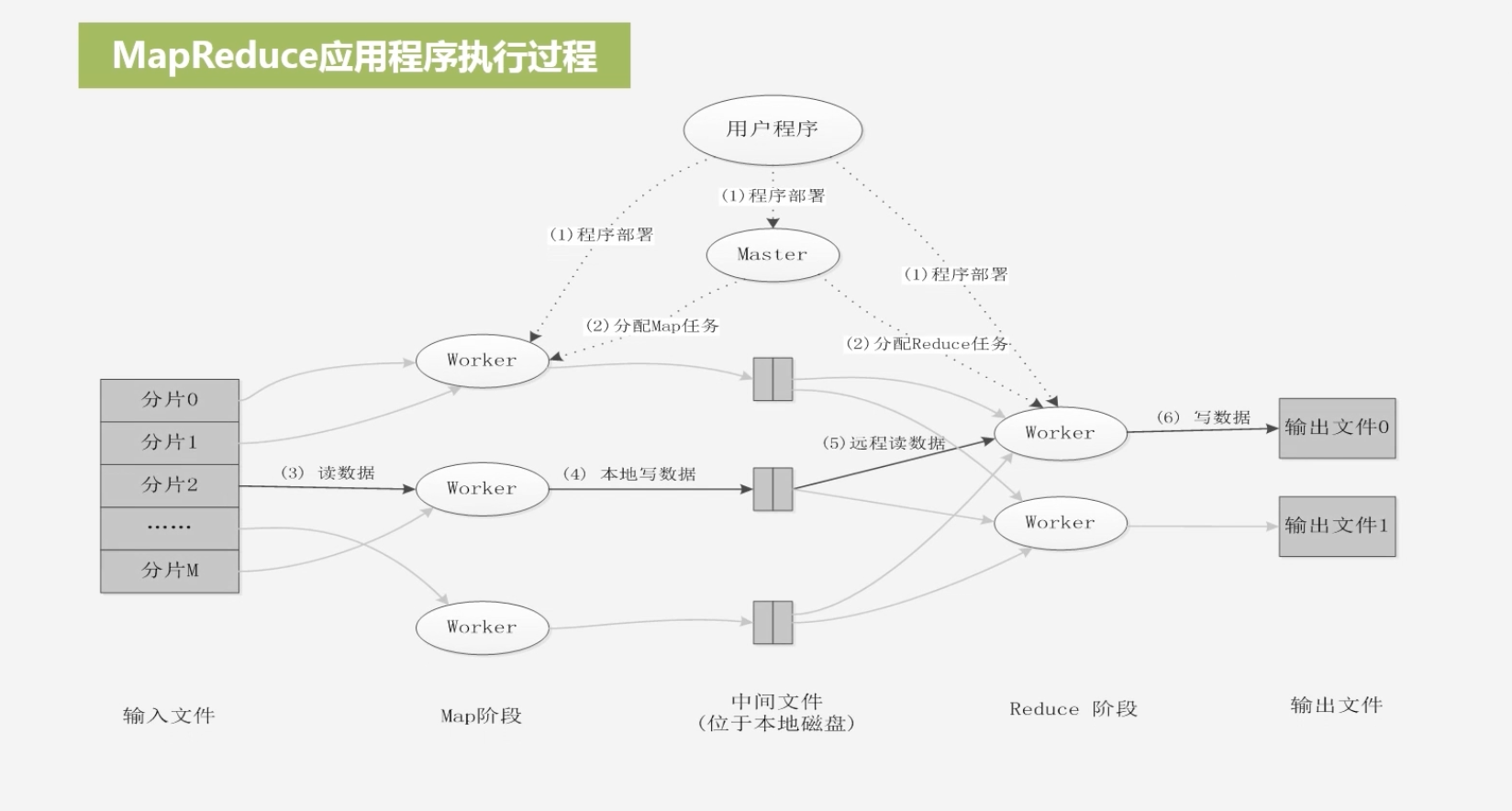
-
-
程序部署:将程序分发到不同机器上
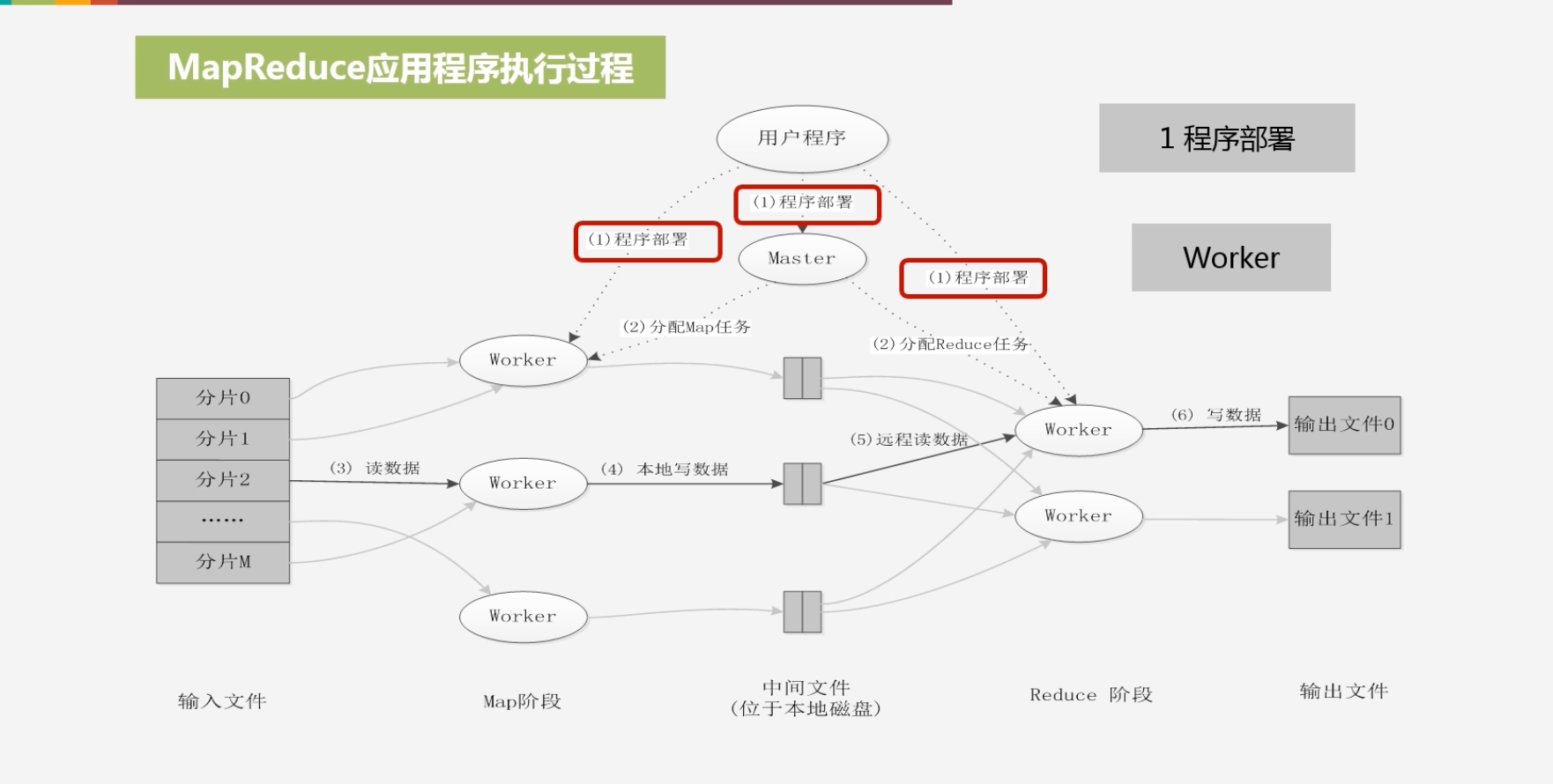
-
-
-
分配Worker执行Map任务和Reduce任务
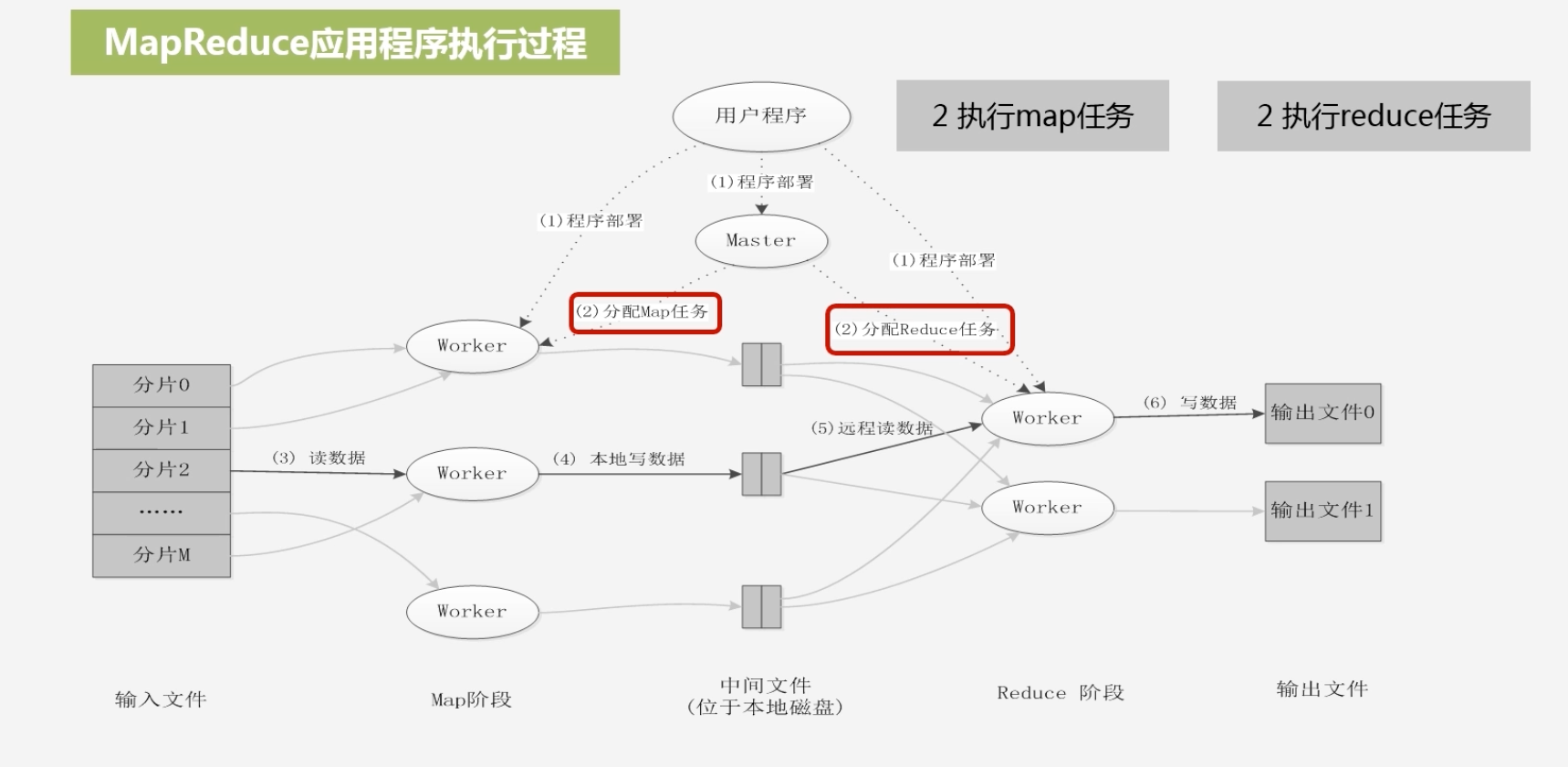
-
-
-
选择空闲Worker机器进行分片,然后读取数据,分给不同的Worker执行Map任务,生成(key,value)键值对,输出结果先写到缓存
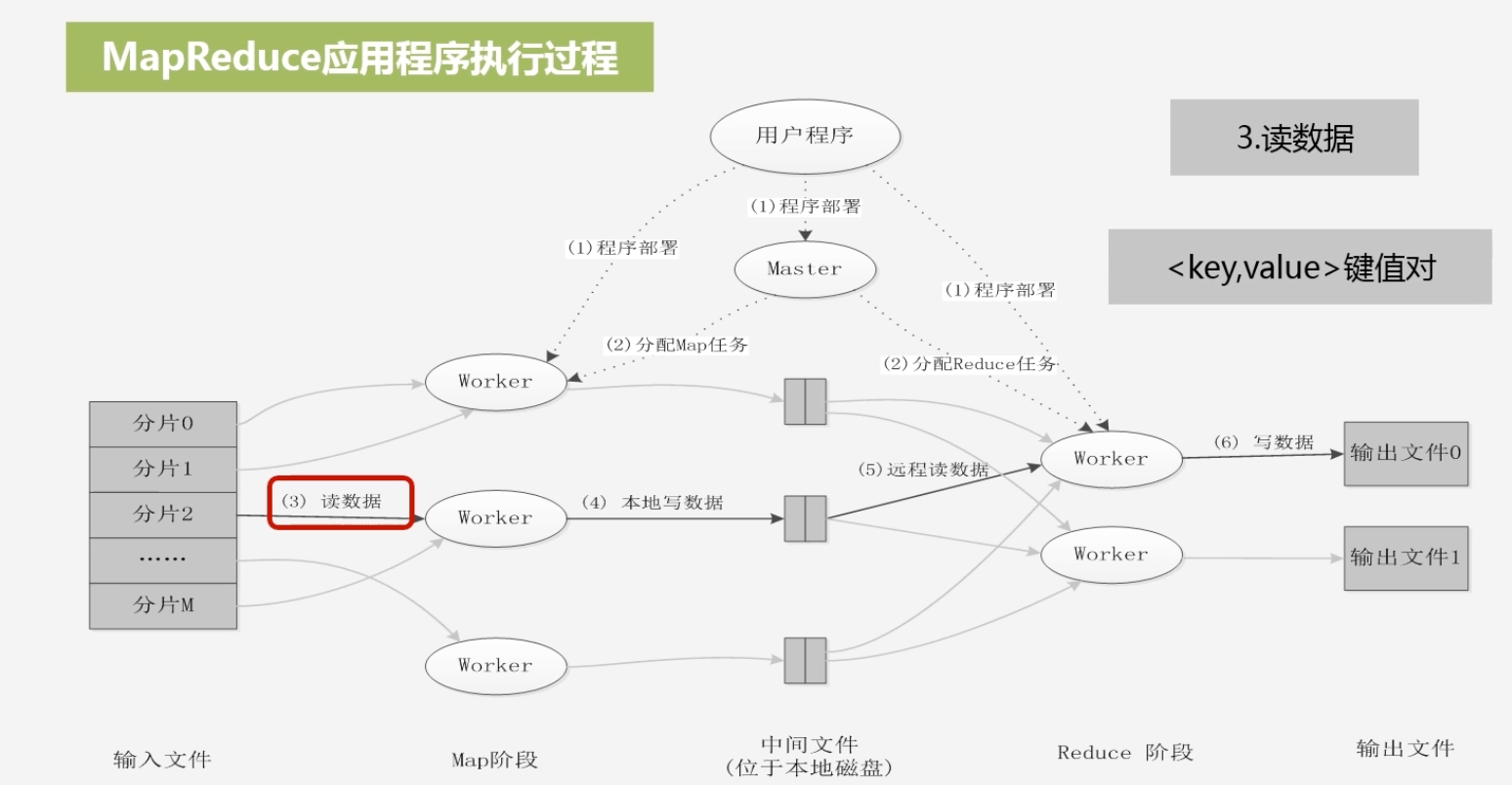
-
-
-
缓存满了会将数据写到本地
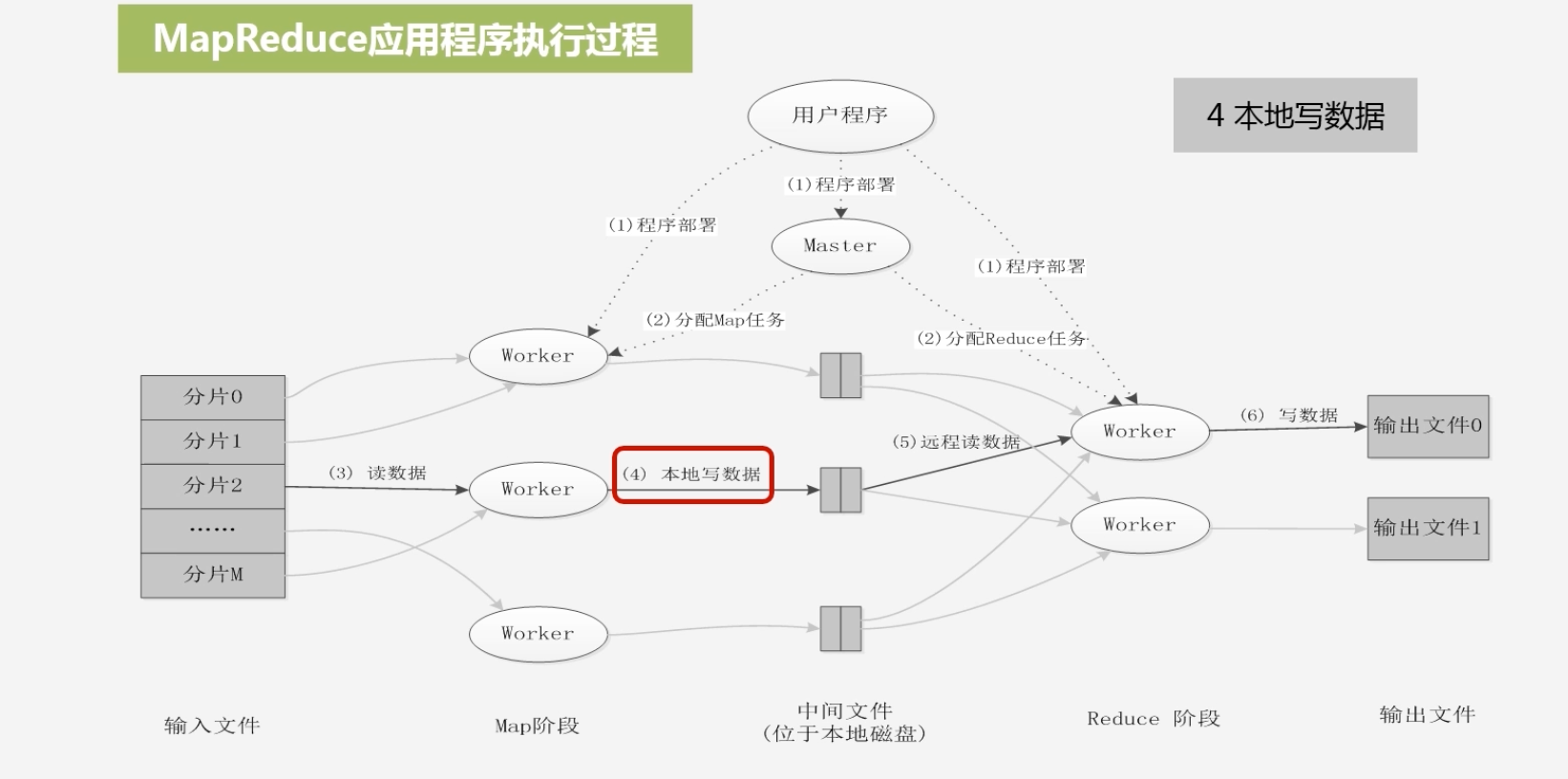
-
-
-
Reduce机器将数据拉回到本地处理
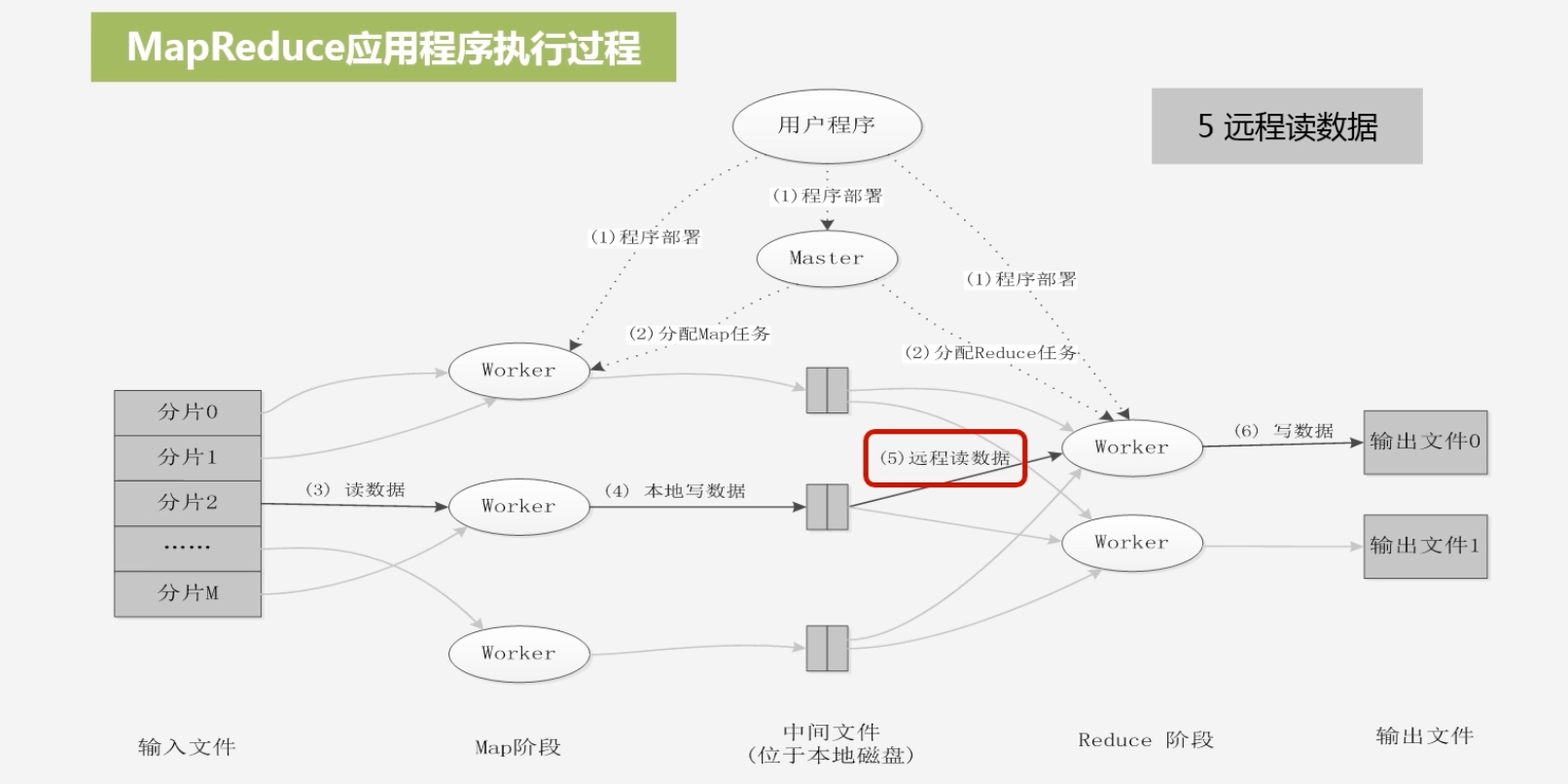
-
-
-
将相关的结果写到输出文件中去
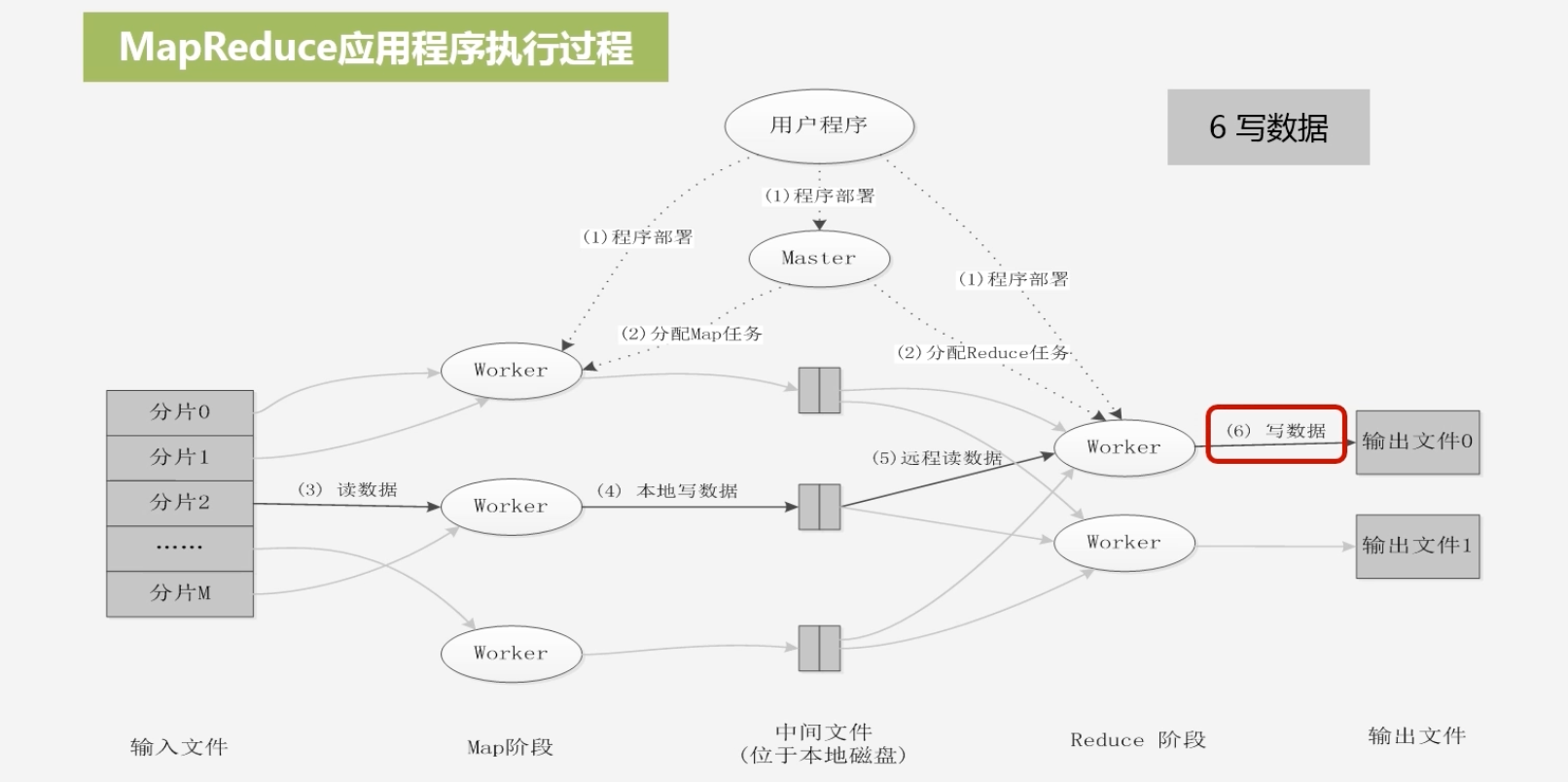
-
-
7.6 WordCount实例分析
-
WordCount程序任务:满足MapReduce分而治之的要求
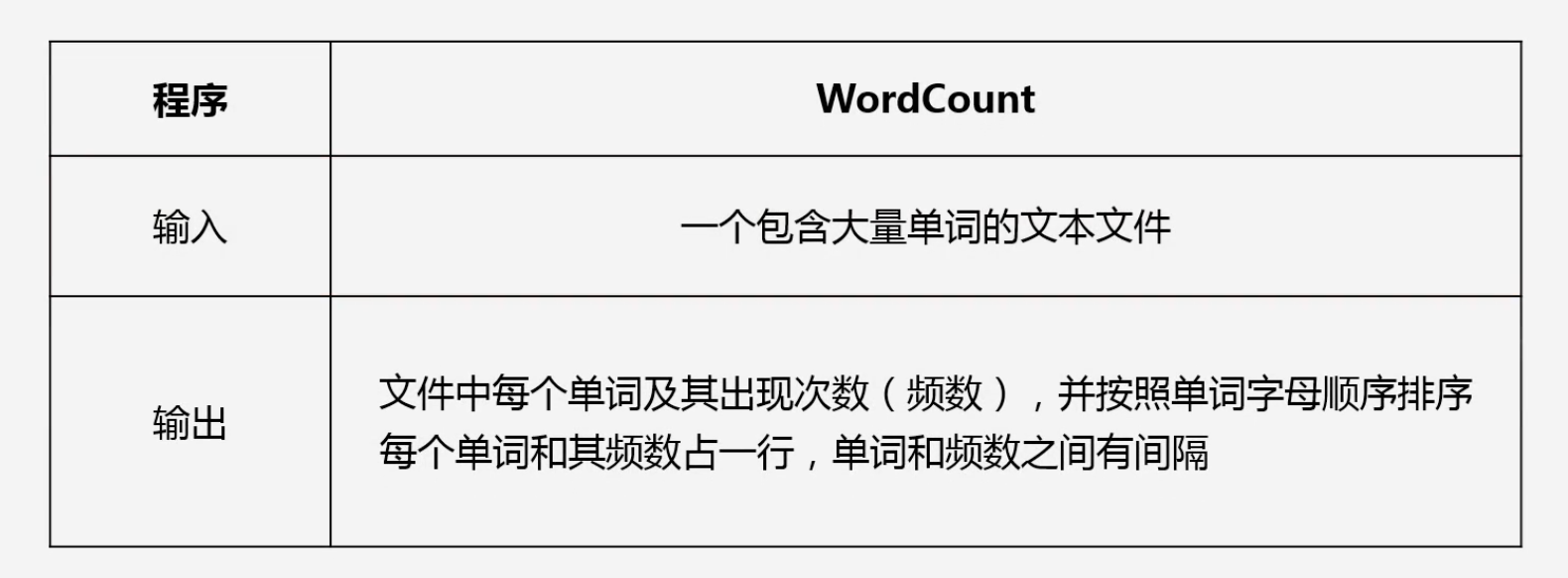
-
一个WordCount执行过程的实例
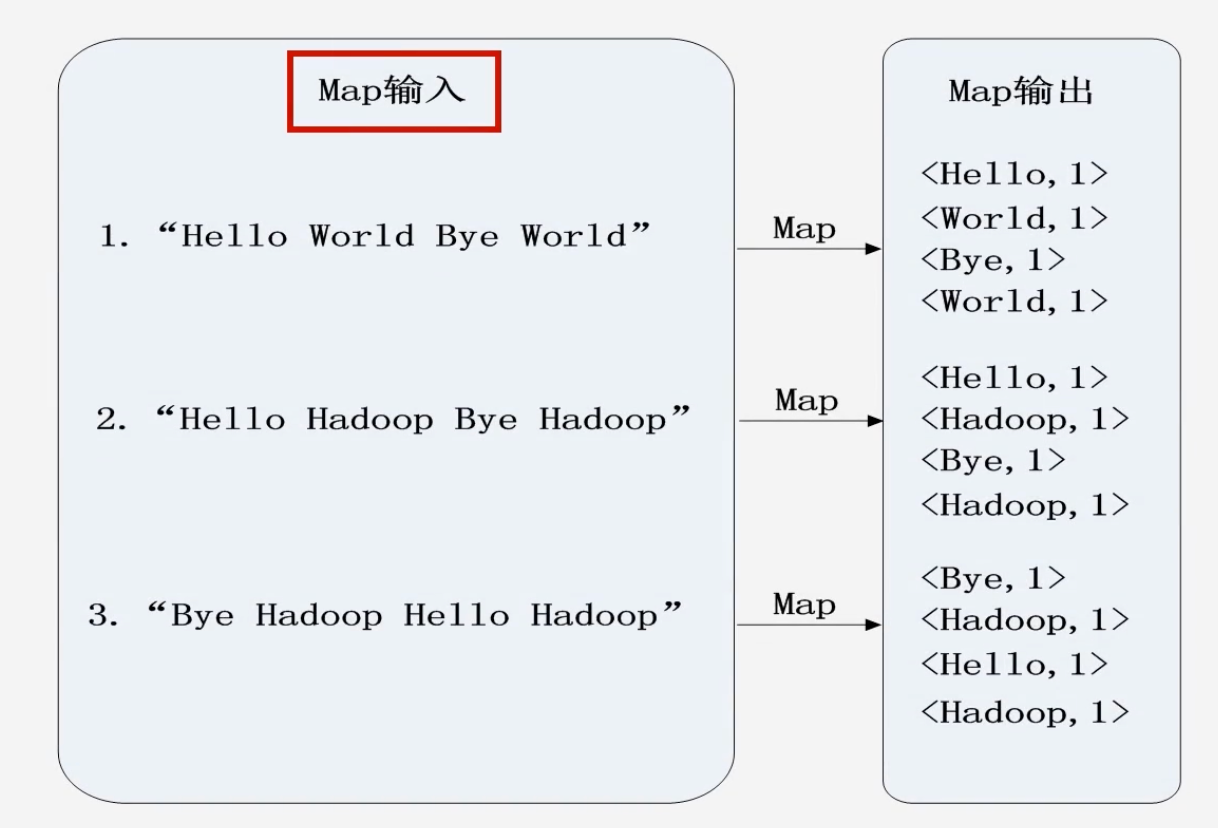
-
假设用户没有定义合并(combine)操作,shuffle操作之后生成的是(key,value-list)形式
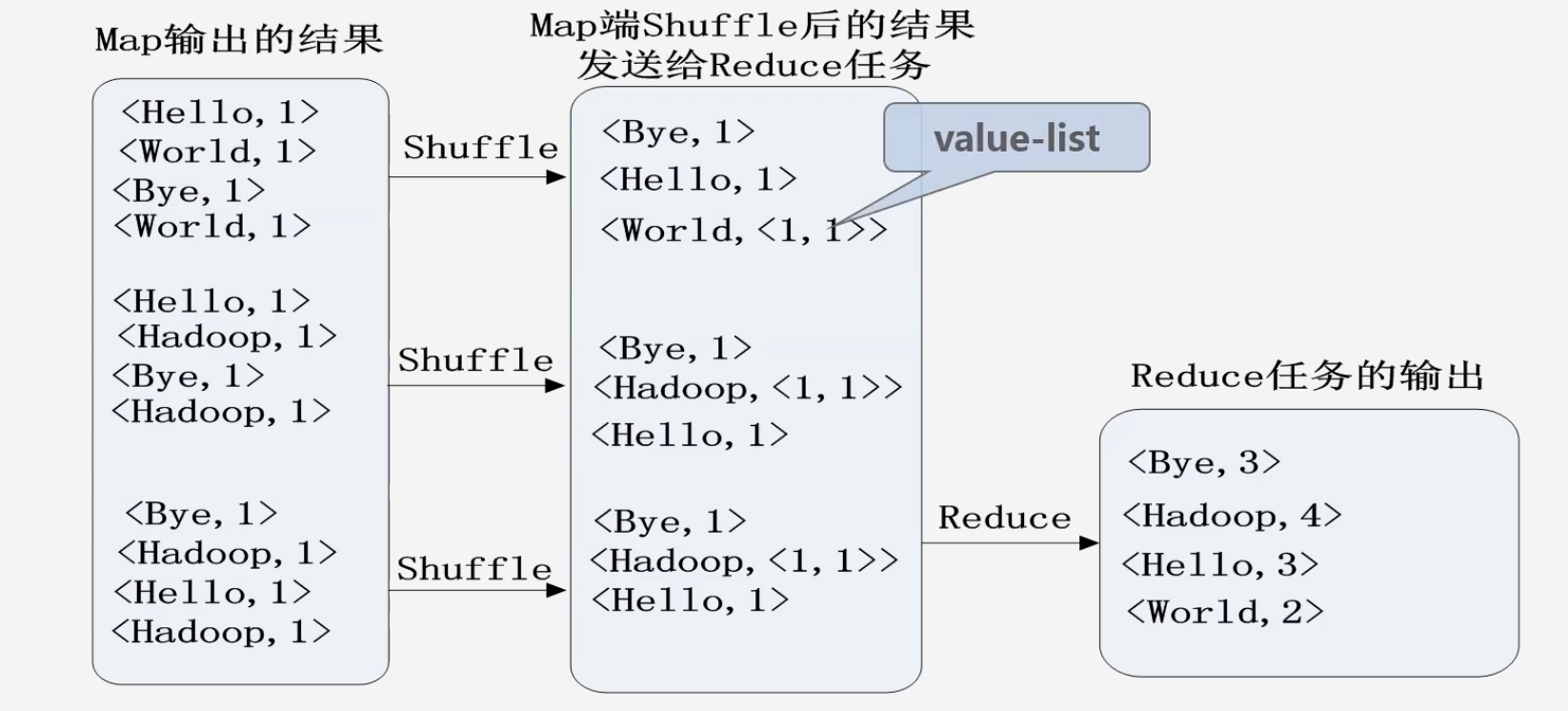
-
假如用户定义了Combine操作:
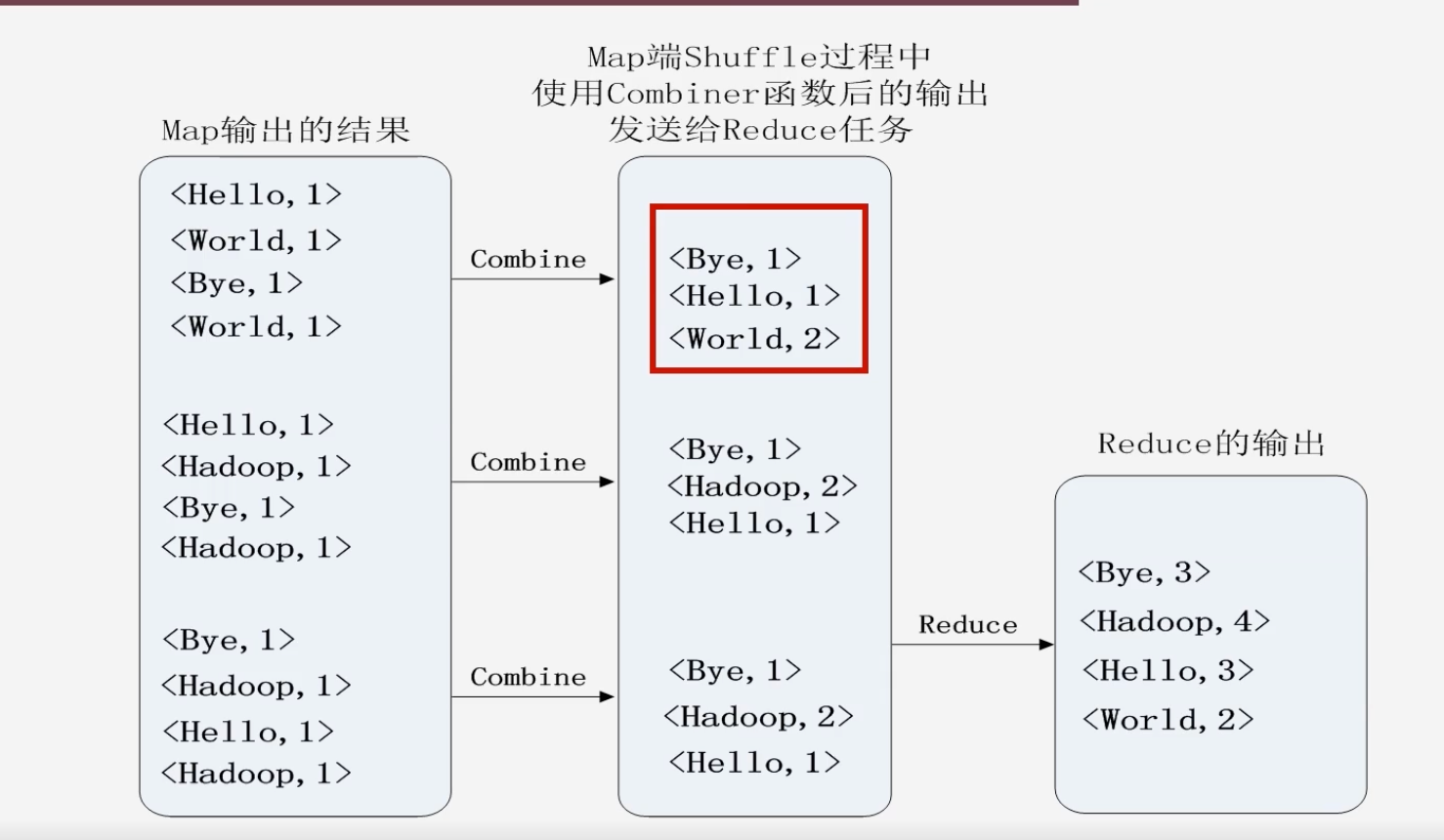
-
7.7 MapReduce的具体应用
-
相关应用
-
举例:MapReduce实现关系的自然连接
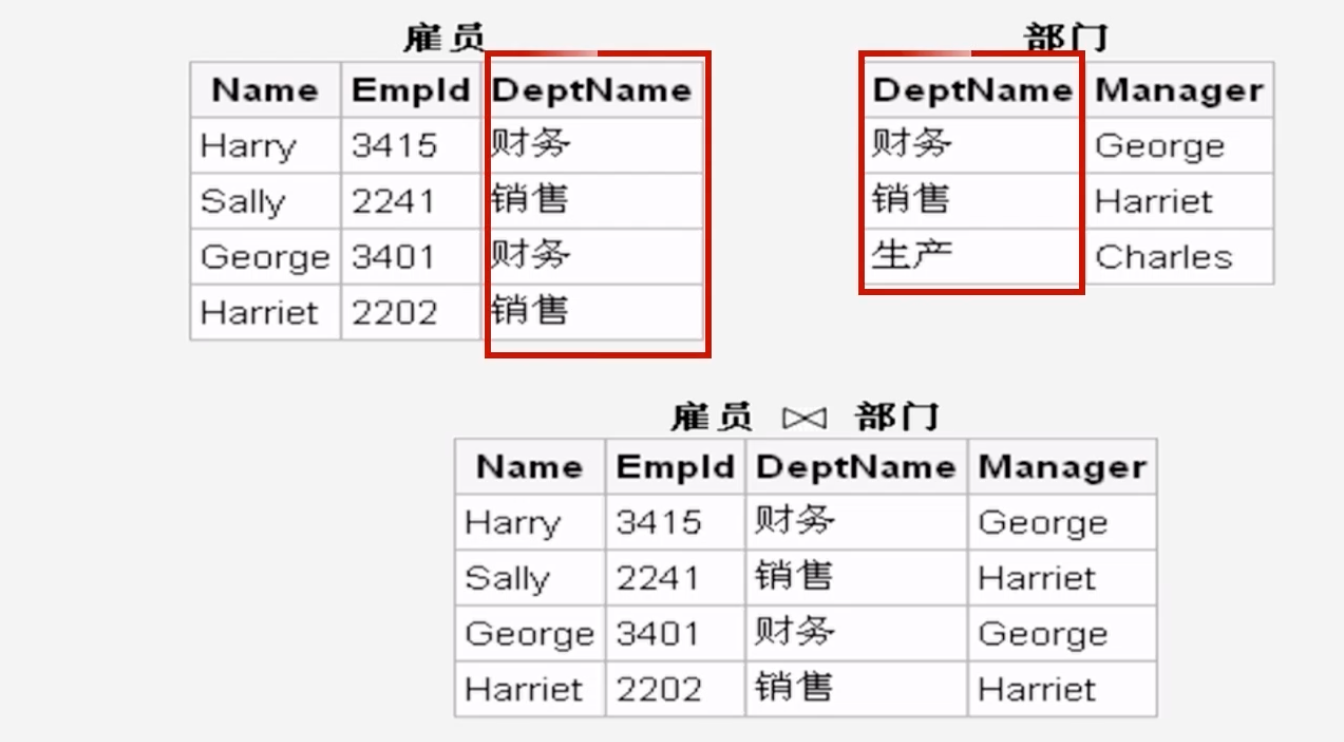
-
用Map实现自然连接的过程:原理
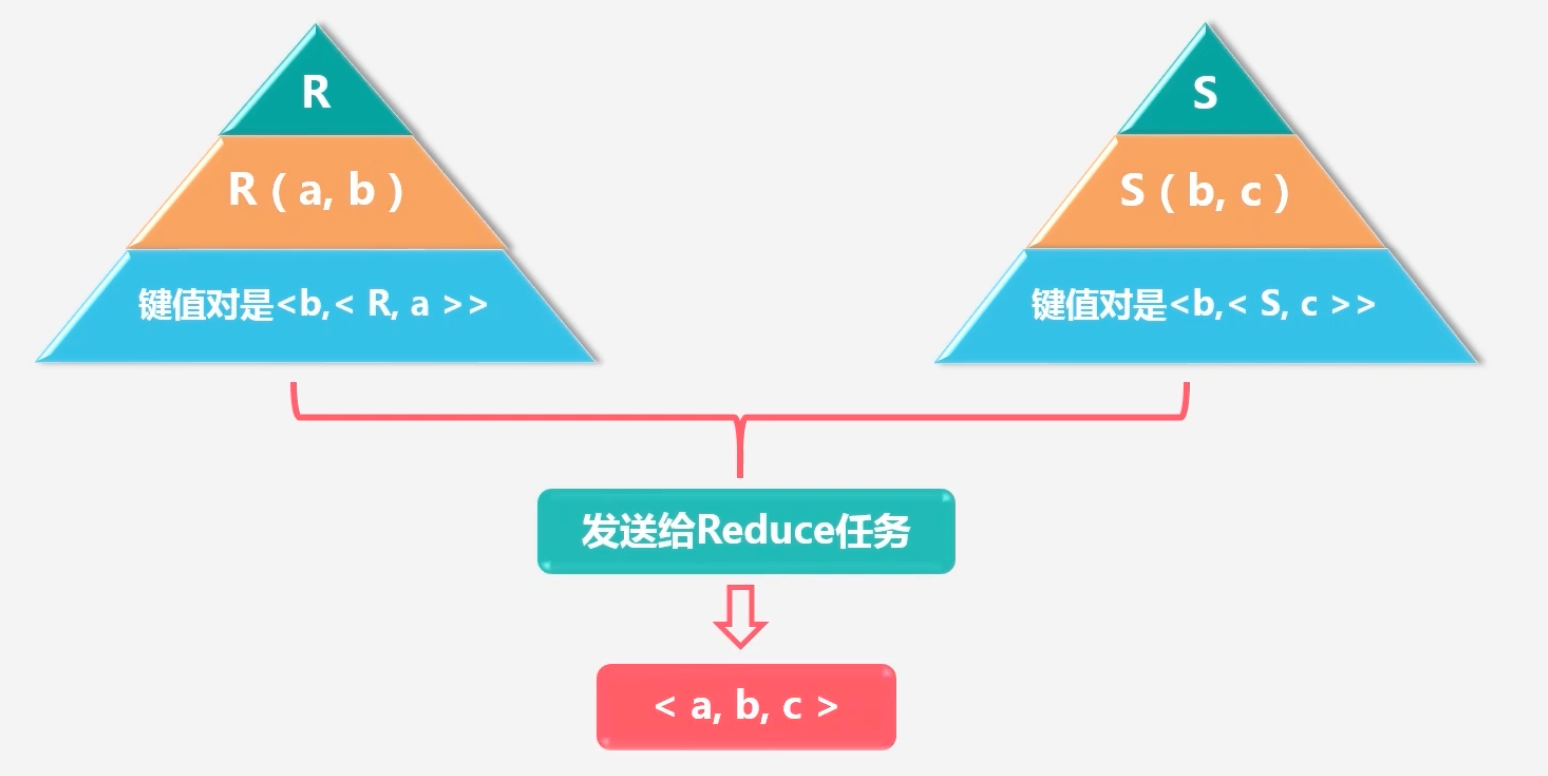
-
具体过程
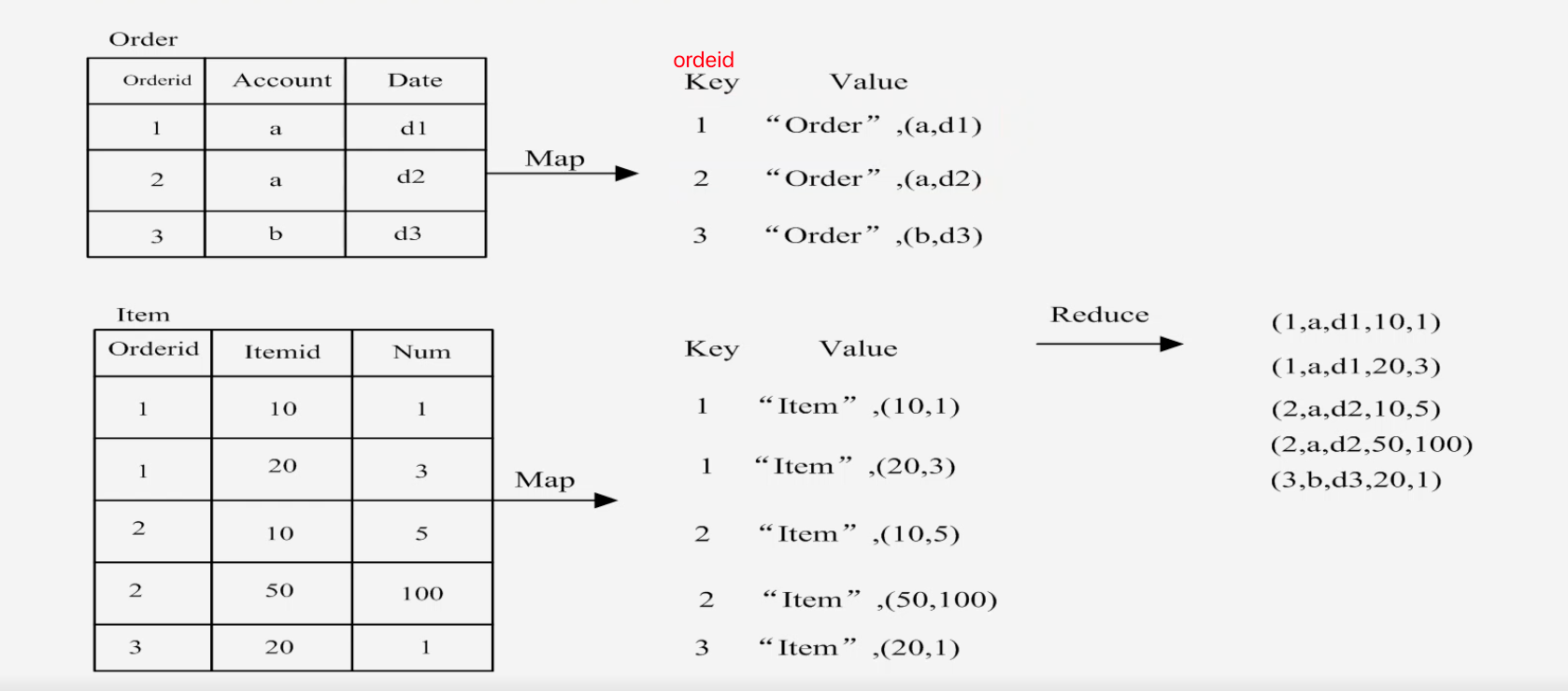
-
7.8 MaReduce编程实践
见:[MapReduce编程实践(Hadoop3.3.5)_厦大数据库实验室博客 (xmu.edu.cn)](














 6176
6176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









