










记录一下一个业务问题,流程是这样的,我现在有一个定时任务,5分钟执行一次,更新车辆打卡的情况。现在有20俩车,每辆车都分配了路线,每条路线都有打卡点,每个打卡点分配了不同的时间段,也就是说,一条路线可能有几百个打卡点,这几百个打卡点中每一个都分配了时间段,有可能是1个时间段,比如8:00 - 10:00这个时间段,要去打卡。也有可能有的打卡点分配了几个时间段,比如上午两个时间段,下午两个时间段。这个时候要去判断今天的打卡情况,只能先获取路线的打卡点,然后再获取单个打卡点下面的时间段,再进行判断操作。但是问题来了,之前的写法for循环去判断只针对少数打卡点,比如一条路线也就5 - 10个打卡点这样。但是现在打卡点数量过多,路线增加,以及每个打卡点都有打卡时间段,for循环操作数据库判断无比的慢,以及非常的消耗资源内存等。。但是判断是否经过打卡点这种必须要在sql里面执行判断,之所有必须在sql判断,因为pgsql提供的ST_DWithin函数就是判断是否在缓冲区范围经过打卡点的。。所以离不开sql判断。下面代码是for循环的操作,先循环出单条路线的打卡点,然后再根据打卡点的ID用stream流匹配打卡点的时间段,再循环每个时间段到sql里面进行判断。
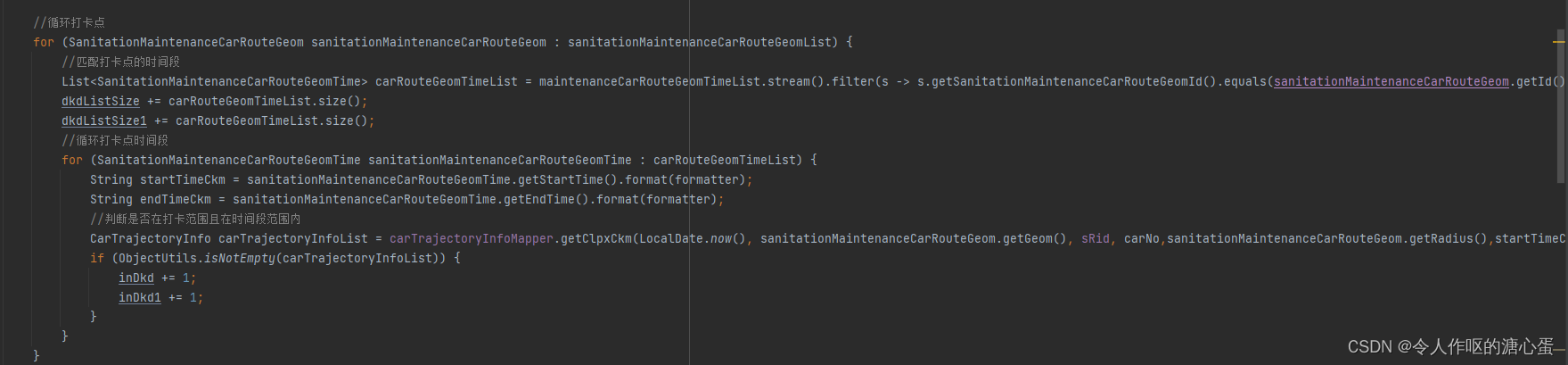
sql语句判断是这样的
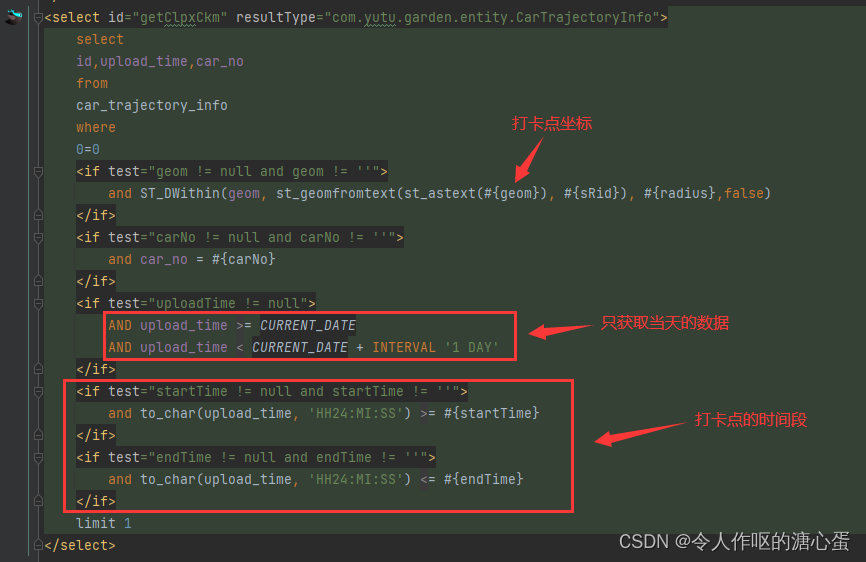
既然我们离不开sql语句判断,那就只能按照老套路,加索引这些。但是加索引提升了一点查询速度,持续的查询非常的消耗内存,导致项目运行的时候内存持续的猛增。一天时间涨了2G多,这明显很离谱。。。即使GC了,内存也无法得到释放。
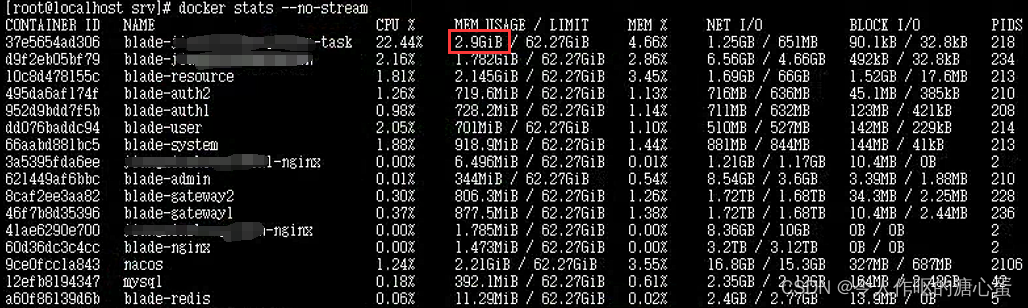
咨询了部门里的老大哥,我问他我这种打卡点判断,能不能不走sql,他说不行的,这种必须走sql的,必须走pg的ST_DWithin函数判断。他给了我一个解决方案,让我先获取出当天的轨迹数据,也就是car_trajectory_info物理表的当天数据,每次定时任务执行的时候,先查出当天的轨迹数据,然后创建临时表,把当天的轨迹数据放到临时表里面,然后把之前的sql判断语句只查临时表,比如创建了一个临时表car_trajectory_info_temp,把原来的sql语句的物理表car_trajectory_info改成car_trajectory_info_temp,执行判断结束后在把临时表删除掉。这样下来,就不会走物理表了,直接走临时表做查询(这里记得在创建临时表的时候加上索引)
具体实现临时表操作如下:
测试类
package com.yutu.garden.task;
import cn.hutool.core.collection.CollUtil;
import com.yutu.garden.entity.CarTrajectoryInfo;
import com.yutu.garden.mapper.gardens.CarTrajectoryInfoMapper;
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
import java.util.List;
import java.util.stream.Collectors;
@Component
@EnableScheduling
public class ScheduledTasks01 {
@Resource
private CarTrajectoryInfoMapper carTrajectoryInfoMapper;
// 第一个定时任务,每隔5秒执行一次
@Async("taskExecutor")
@Scheduled(cron = "*/10 * * * * *")
@Transactional
public void task() {
//先查询出当天的轨迹数据,按照条件吧,如果还有条件,可以更加详细到某些指定的数据,比如说按车牌号条件筛选
List<CarTrajectoryInfo> carTrajectoryInfoList = carTrajectoryInfoMapper.getToDayCarInfoList();
//测试 创建临时表
carTrajectoryInfoMapper.createTempTable();
System.out.println("临时表创建成功");
//递归向临时表中插入当天的数据(防止数据量过大引发IO异常)
add(carTrajectoryInfoList,0L,500L);
//查询临时表(在这里判断是否经过打卡点!)
CarTrajectoryInfo carTrajectoryInfo = carTrajectoryInfoMapper.selectTempTable(必要的参数,这里只是测试);
System.out.println("执行查询,如果为空,那就是没有经过打卡点,如果不为空那就是已经经过打卡点");
System.out.println(carTrajectoryInfo);
System.out.println("删除临时表");
carTrajectoryInfoMapper.dropTempTable();
}
//递归插入(防止数据量过大引发IO异常)
public void add (List<CarTrajectoryInfo> all,long start,long limit){
//截取 从start开始截取 截取limit条
List<CarTrajectoryInfo> collect = all.stream().skip(start).limit(limit).collect(Collectors.toList());
if(CollUtil.isEmpty(collect)){
return;
}
//批量插入数据的方法
//保存车辆轨迹数据
carTrajectoryInfoMapper.insertDataTempTable(collect);
//递归 每次插入limit条数据
add(all,start+limit,limit);
}
}
mapper层
package com.yutu.garden.mapper.gardens;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.yutu.garden.entity.CarTrajectoryInfo;
import com.yutu.garden.vo.CarWarnInfoCqZtVo;
import com.yutu.garden.vo.CarWarnInfoZyInfoVo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import java.time.LocalDate;
import java.util.Date;
import java.util.List;
@Mapper
public interface CarTrajectoryInfoMapper extends BaseMapper<CarTrajectoryInfo> {
//获取当天轨迹数据
List<CarTrajectoryInfo> getToDayCarInfoList();
//批量插入数据
void insertDataTempTable(@Param("carTrajectoryInfoList") List<CarTrajectoryInfo> carTrajectoryInfoList);
//创建临时表
void createTempTable();
//使用临时表执行判断
CarTrajectoryInfo selectTempTable(@Param("geom")String geom,
@Param("sRid")Integer sRid,
@Param("carNo")String carNo,
@Param("radius") Integer radius,
@Param("startTime") String startTime,
@Param("endTime") String endTime);
//删除临时表
void dropTempTable();
}
xml中sql语句
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.yutu.garden.mapper.gardens.CarTrajectoryInfoMapper">
<select id="getToDayCarInfoList" resultType="com.yutu.garden.entity.CarTrajectoryInfo">
select * from car_trajectory_info where DATE(upload_time) = CURRENT_DATE
</select>
<sql id="createTempTableSQL">
CREATE TEMPORARY TABLE car_trajectory_info_temp (
id int8 NOT NULL,
car_no varchar(255),
device_no varchar(255),
lng float8,
lat float8,
speed float8,
upload_time timestamp(6),
distance float8,
duration float8,
today_distance float8,
geom geometry,
clean_area float8
);
CREATE INDEX car_trajectory_info_temp_car_no_idx ON car_trajectory_info_temp USING btree (car_no);
CREATE UNIQUE INDEX car_trajectory_info_temp_id_uindex ON car_trajectory_info_temp USING btree (id);
CREATE INDEX car_trajectory_info_temp_upload_time_idx ON car_trajectory_info_temp USING btree (upload_time);
CREATE INDEX car_trajectory_info_temp_geom_idx ON car_trajectory_info_temp USING gist (geom);
</sql>
<update id="createTempTable">
<include refid="createTempTableSQL"/>
</update>
<insert id="insertDataTempTable">
INSERT INTO car_trajectory_info_temp
(id,car_no, device_no, lng, lat, speed, upload_time, distance, duration, today_distance, geom, clean_area)
VALUES
<foreach collection="carTrajectoryInfoList" item="item" separator=",">
(
#{item.id},
#{item.carNo},
#{item.deviceNo},
#{item.lng},
#{item.lat},
#{item.speed},
#{item.uploadTime},
#{item.distance},
#{item.duration},
#{item.todayDistance},
st_geomfromtext(st_astext(#{item.geom}), 4326),
#{item.cleanArea}
)
</foreach>
</insert>
<select id="selectTempTable" resultType="com.yutu.garden.entity.CarTrajectoryInfo">
select
id,upload_time,car_no
from
car_trajectory_info_temp
where
0=0
<if test="geom != null and geom != ''">
and ST_DWithin(geom, st_geomfromtext(st_astext(#{geom}), #{sRid}), #{radius},false)
</if>
<if test="carNo != null and carNo != ''">
and car_no = #{carNo}
</if>
<if test="startTime != null and startTime != ''">
and to_char(upload_time, 'HH24:MI:SS') >= #{startTime}
</if>
<if test="endTime != null and endTime != ''">
and to_char(upload_time, 'HH24:MI:SS') <= #{endTime}
</if>
limit 1
</select>
<sql id="dropTempTableSQL">
DROP TABLE IF EXISTS car_trajectory_info_temp;
</sql>
<update id="dropTempTable">
<include refid="dropTempTableSQL"/>
</update>
</mapper>
对了,如果你是多线程,使用相同的临时表,记得添加事物隔离,不然一个Service中创建临时表car_trajectory_info_temp,这时候另外一个Service也在创建临时表car_trajectory_info_temp,这时候就会出现冲突。
在多线程环境中,特别是使用数据库时,经常会出现类似的问题。出现 “关系 ‘car_trajectory_info_temp’ 已经存在” 的错误通常是因为两个不同的线程(或服务)同时尝试在同一个数据库中创建同名的临时表,这时数据库系统会报错,因为它要求每个表在同一个模式(schema)中必须是唯一的。
这种情况可能发生在以下几种情况下:
- 并发创建表:两个服务或线程在同一时间内执行了创建临时表的操作,由于操作是并行进行的,它们并不会相互感知对方的操作,因此可能导致尝试创建同名表的冲突。
- 临时表的作用域:有些数据库管理系统在某些情况下,临时表的作用域可能与连接相关联,但也可能会在整个数据库会话期间持久化。如果两个服务使用了相同的连接或者会话,那么在同一连接内创建的临时表会对其他尝试创建同名临时表的操作产生影响。
为了解决这个问题,可以考虑以下几点:
- 确保临时表的唯一性:在多线程或多服务的环境中,确保每个服务或线程创建的临时表具有唯一的命名,以避免命名冲突。可以在表名中加入服务名或者其他唯一标识符来确保这一点。
- 使用数据库事务:在可能的情况下,使用数据库的事务来包装创建临时表的操作,确保操作的原子性和隔离性,避免并发问题。
- 检查数据库连接和会话管理:确保每个服务或线程使用独立的数据库连接或会话,以防止因共享连接导致的并发问题。
- 考虑临时表的生命周期:了解和利用数据库系统中临时表的生命周期和作用域规则,以便在创建和使用临时表时遵循正确的实践和策略。
如果出现表已存在的错误是由于多个线程或服务同时尝试创建同名临时表而引起的并发问题。通过增加表名的唯一性标识符或者优化数据库操作流程,可以有效地避免这类问题。我们可以在xml的sql语句中使用${tableName}启用不同的临时表名。如:

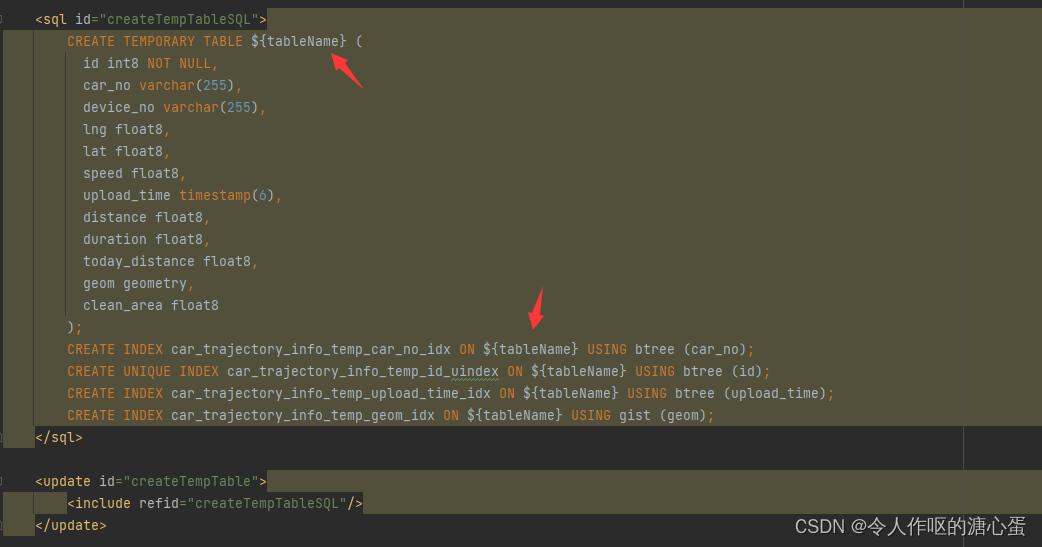
这里另外说一点,在Java中,@Transactional注解用于声明一个方法或类中所有方法的事务边界。默认情况下,Spring的声明式事务管理是在单个线程中进行的,即事务的范围和生命周期绑定到了一个线程上。
当你在一个有@Transactional注解的方法中执行多线程操作时,每个新线程都会有自己的生命周期和执行上下文,它们不会共享原始线程的事务上下文。这意味着在这些新线程中执行的操作不会参与到原始线程中声明的事务中。
如何提升效率呢?
这你就要引入多线程了,就比如我有20辆车,我使用线程去跑,核心线程设置20,让每辆车单独启用一条线程去执行,这样子效率一下子就提升了,不过这也要看你服务器CPU的承受能力。
下面提供一个示例:
线程池配置类
package com.ckm.ball.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
@Configuration
@EnableAsync // 启用异步执行支持
public class TaskExecutorConfig {
@Bean
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(20); // 核心线程数
executor.setMaxPoolSize(50); // 最大线程数
executor.setQueueCapacity(20); // 队列容量 如果核心线程数满了、队列也满了、这时候会从最大线程数中开辟一条新的线程
executor.setThreadNamePrefix("ckm-task-executor-"); // 线程名前缀
executor.initialize();
return executor;
}
}
测试类
package com.ckm.ball.task;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
@Component
@EnableScheduling
public class ScheduledTasks01 {
@Resource
private ThreadPoolTaskExecutor taskExecutor;
// 定时任务,每隔10秒执行一次
@Scheduled(cron = "*/10 * * * * *")
public void task1() {
for (int i = 0; i < 21; i++) {
taskExecutor.execute(() -> threadTest());
}
}
public void threadTest(){
System.out.println("当前时间:" + System.currentTimeMillis()+",线程名称:"+Thread.currentThread().getName());
}
}
输出结果
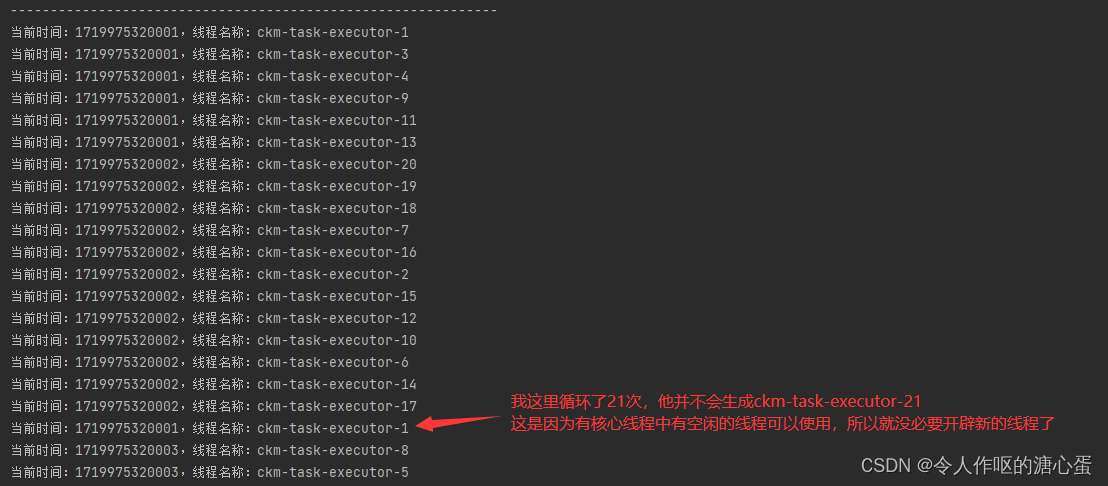
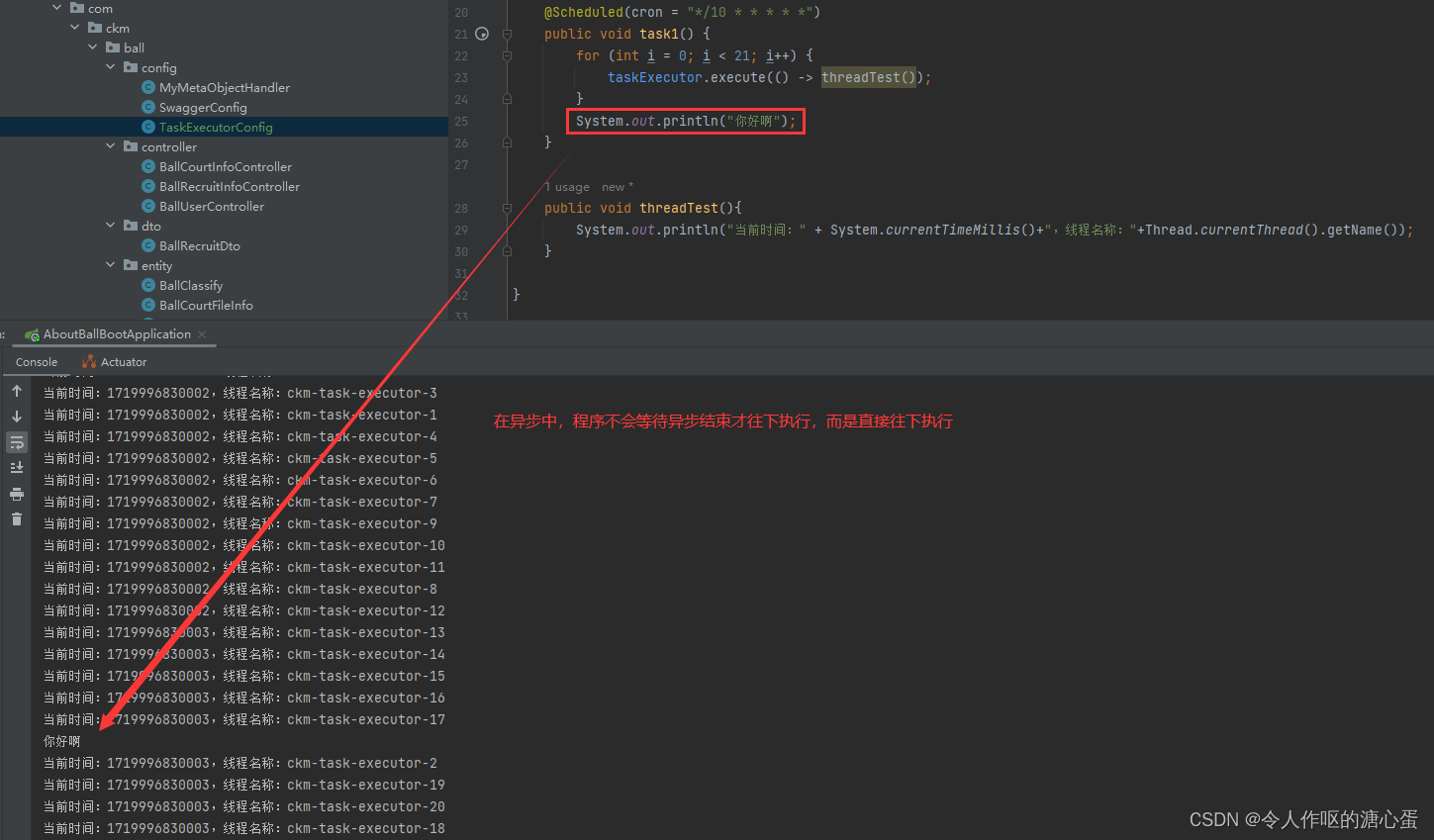
请记住,使用异步多线程,程序不会等待异步结束,而是直接执行之后的代码,就比如下面的代码
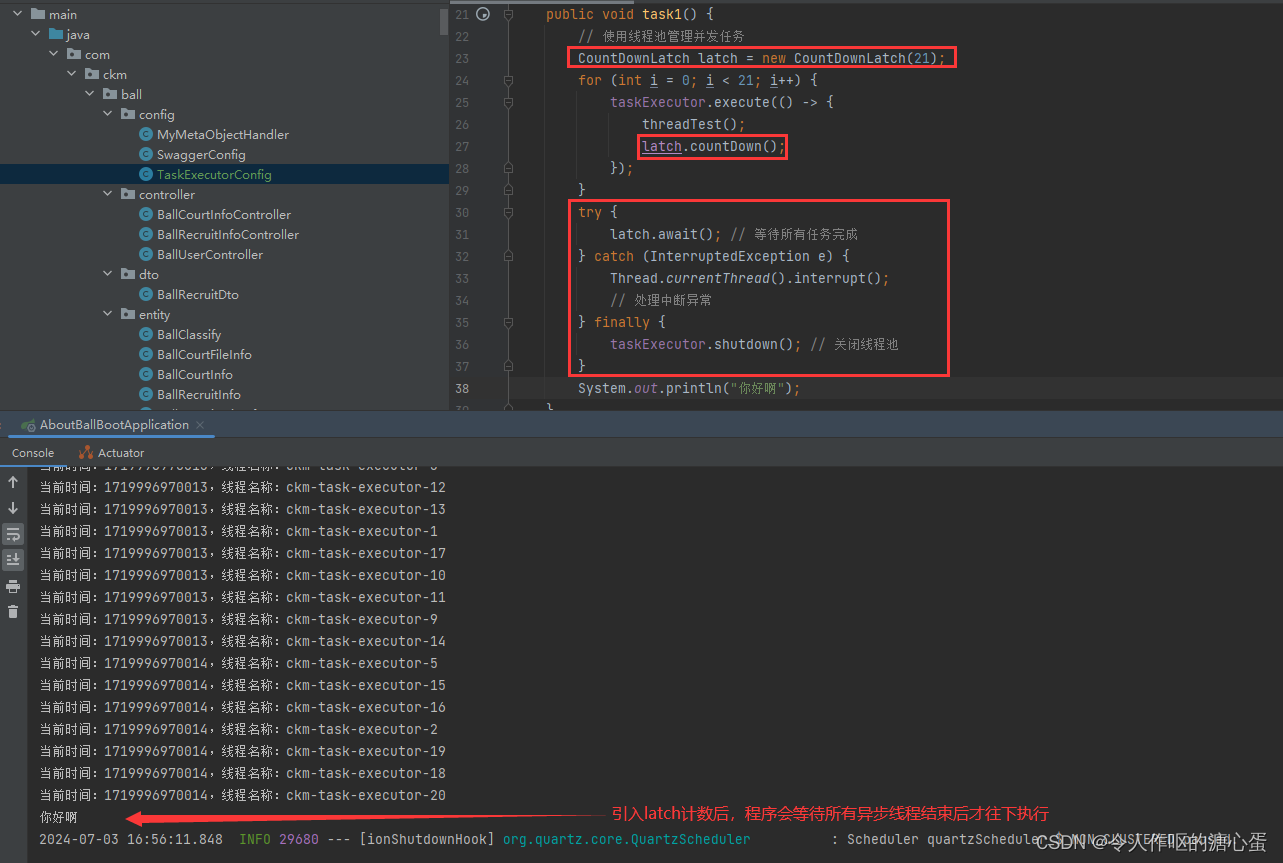
如果你想等待异步执行结束后才执行后续代码,可以添加CountDownLatch计数
package com.ckm.ball.task;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.concurrent.CountDownLatch;
@Component
@EnableScheduling
public class ScheduledTasks01 {
@Resource
private ThreadPoolTaskExecutor taskExecutor;
// 第一个定时任务,每隔10秒执行一次
@Scheduled(cron = "*/10 * * * * *")
public void task1() {
// 使用线程池管理并发任务
CountDownLatch latch = new CountDownLatch(21);
for (int i = 0; i < 21; i++) {
taskExecutor.execute(() -> {
threadTest();
latch.countDown();
});
}
try {
latch.await(); // 等待所有任务完成
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
// 处理中断异常
} finally {
taskExecutor.shutdown(); // 关闭线程池
}
System.out.println("你好啊");
}
public void threadTest(){
System.out.println("当前时间:" + System.currentTimeMillis()+",线程名称:"+Thread.currentThread().getName());
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











