







组合数据类型
集合类型
集合与Java中的集合定义相同,都是组合的数据类型,将数据以某种方式进行存储,可以是链表(LinkedList),可以是数组(ArrayList),可以是哈希表(HashMap),可以是堆(PriorityQueue)。
在Python中,集合类型与数学上的集合概念一致,集合元素之间无序,唯一,不可重复 , 并且集合中的元素不能被修改,不能是可变的数据类型!
因为如果集合类型中的数据可以被改变,在定义的时候,集合的元素是:1,2,3,4,5. 没有问题,但是如果把1 改为2 ,那么这个就不是一个集合了!
不可变数据类型:整形,浮点型,复数,字符串,元组等等,都是不可变类型
集合用 {} 表示,元素之间用逗号分隔
建立集合类型用 {} 或者 set()
(使用空集合必须用set())
#("python",123) 是一个元组
#用{}建立集合
A = {
"python",123,("python",123)}
# A集合的元素,就是 {123,"python",("python",123)}
# 用set() 建立集合
B = set("pytpyt123")
# B 集合的元素,是 “p”,1,“y”,3,“t”,2,
#因为字符串中pty 都是重复的,所以会直接去重,与Java中的HashSet是一样的,并且无序
#其实使用括号,也会有去重的效果
集合特性:用{} 或者set 去定义,元素用 , 分隔;唯一,无序,不可改变
集合之间的运算
交 并 差 补 这四种运算是集合中一定有的
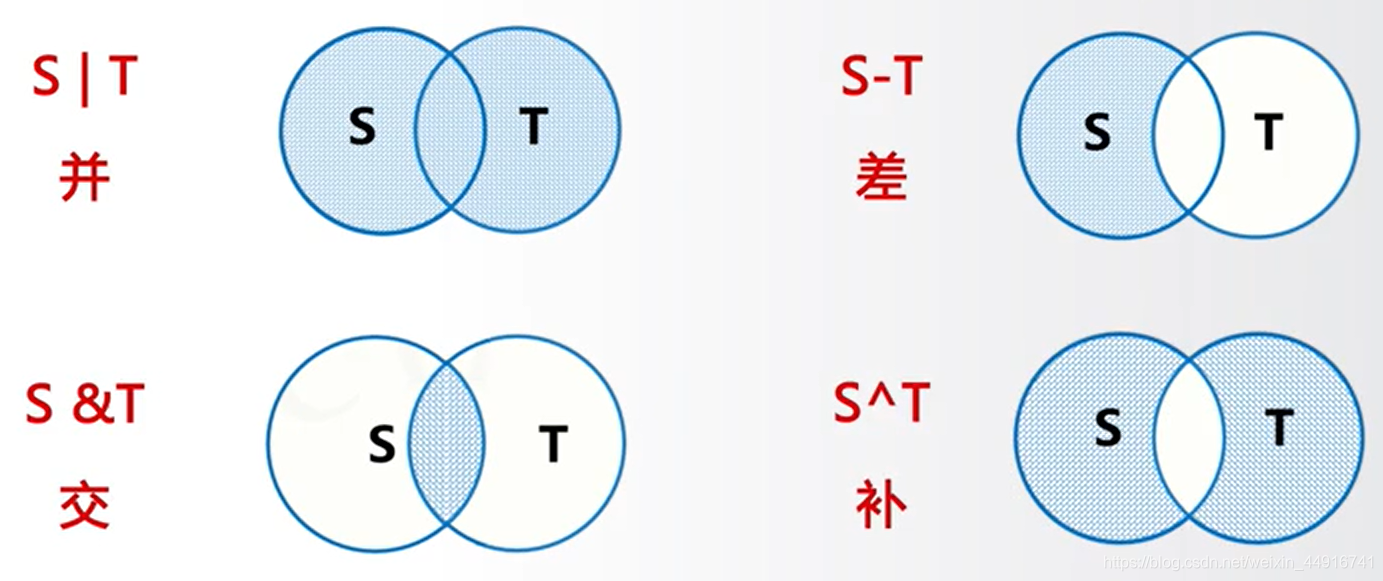
A = {
1,2,3,4}
B = {
2,3,5,"a","b"}
#并集
print(A|B)
# 包含在A ,但不包含在B 的差集
print(A-B)
# 交集
print(A&B)
# 返回A 和 B 中不相同的元素
print(A^B)
# 返回True / False 判断A 和 B 的子集关系
S = {
1,2,3}
T={
1,2}
print(S <= T)
print(S < T)
# 判断A 和 B 的包含关系
print(S >= T)
print(S > T)
结果:

增强操作符
除了交集 并集的操作,还有四种增强操作符,来更新集合

C = {
1,2,3,4,6}
D = {
2,3,7,8}
C |= D
print(C)
#结果: 1, 2, 3, 4, 6, 7, 8
集合的十大方法
S.add(x) :向集合S 中添加 x 元素
S.discard(x) :删除集合S 中 x 元素,如果x 不存在,不会报错
S.remove(x) :删除S集合中的 x 元素,如果x不存在,产生 keyError 的异常
S.clear() : 清空集合S
S.pop():随机拿出一个元素,并且更新集合,将此元素删除,如果S集合为空,就会产生KeyError异常
S.copy() :返回S 的一个副本
len(S) : 返回集合S 的个数
x in S : 判断 x 是否在S 中,如果在返回True,否则返回False
x not in S : 判断 x 不在S 中, 如果不在,那么返回True,否则返回False
set(x) : 将 x 转为集合类型
遍历集合元素:
for item in A:
print(item,end=",")
应用场景
1.包含关系的比较
判断一个数据是否在整个集合中,或者一组数组是否在一个集合中。
#1.判断单个元素
"p" in {
"p","y",123}
#结果True
#2.判断一组数据
# >= 前一个集合是否包含 后一个集合
{
"p","y"} >= {
"p","y",123}
#结果 False
2.数据去重
相信学过Java的一定有整个印象,如果要对一个集合进行去重,直接放到HashSet中就行了 。
而python的集合本身就具备整个特性,所以如果我们有一组数据,要进行去重,直接使用 set()函数,将它转为集合就可以了。
#定义一个列表,有重复的数据
a = [1,2,3,4,4,4,4,5,3]
A = set(a)
print(A)
#结果:{1,2,3,4,5}
# 如果还想将它以列表的方式去操作
#使用list() 即可
IS = list(A)
print(IS)
#结果: [1,2,3,4,5]
序列类型及操作
序列类型的定义
序列:具有一定先后关系的一组元素
可以理解为序列是一维元素向量,元素类型可以不同(可以对应Java中的ArrayList,但是序列类型的底层不是数组,后续的高级学习中,我会尽量的去找python关于解释器层面的知识,理解并学习)
序列是一个基类类型,也就是基本数据类型。但是一般使用的时候并不会使用序列类型,而是使用衍生的类型,字符串类型,元组类型,列表类型。
这三个类型都是序列类型的衍生,序列操作的对于这三个都是适用的,我们可以这样理解,序列类型,相当于一个父接口,而字符串,元组,列表,都是它的具体实现子类,子类总是比父类更强大的,所以也具备自己独特的操作。
序列类型的典型操作,索引,正向与反向的索引,对于这三个类型都是通用的。
序列类型的通用操作符
x in s :如果 x 是序列 s 的元素,返回True,否则返回False
x not in s : 如果 x 不是序列 s 的元素,返回False,否则返回True
s + t : 连接两个序列 s 和 t ,返回一个新的序列(s+=t 也可以使用,将s + t 的列表直接返回s)
s*n 或者 n*s : 将序列 s 赋值 n 次
s[i]:返回 s列表中 i 号索引的元素
s[i:j] 或者s[i:j:k] :切片,返回s序列中 第 i 到 j 以k为步长的子序列([ i ,j )左闭右开区间 )
另外的取反
ls[::-1] 或者 strs[::-1] 都是对整个序列进行取反
5个序列通用方法:
len(s) :返回序列 s 的长度
min(s) :返回序列 s 中的最小值 ,序列中的元素一定要可比较,否则直接抛出异常
max(s) : 返回序列 s 中的最大值
s.index(x) 或者 s.index(x,i,j) 返回序列 s 从i 开始到 j 位置中,第一次出现元素x 的位置
s.count(x) 返回序列中出现 x 的总次数
元组类型的定义和操作
元组是序列类型的扩展,元组一旦被创建则不能被修改。
使用小括号() 或者 tuple() 创建, 元素之间用 逗号 分隔。
可以使用也可以不使用小括号
之前我们返回多组数据,也就是 return x,y 实际上就是返回的一个元组
元组类型的元素可以是元组类型。
例如
crearture = "cat" , "dog" , "tiger" ,"human"
print(creature)
#结果 ( "cat" , "dog" , "tiger" ,"human")
color = (0x001100,"blue",creature)
print(color)
# 结果(4352,“blue”,( "cat" , "dog" , "tiger" ,"human"))
元组类型就是将元素进行简单排列,并且用小括号来组织
列表类型的定义和操作
列表是序列类型的一个扩展,与元组类型非常相似,经常被使用。
使用方括号 【】 或者 list() 来创建,元素间用逗号 分隔。
列表中元素类型可以不想通过,没有长度限制
ls = ["cat","dog",1024]
print(ls)
#结果: ["cat","dog",1024]
lt = ls
print(lt)
#结果: ["cat","dog",1024]
在这里要注意,如果是直接以等号相连的两个列表,实际上是对【“cat”,“dog”,1024】 进行了浅拷贝,也就是现在又另一个引用来引用整个列表,用lt 也能对 ls 进行改变,也就是引用的是同一个内存地址
常用的操作函数和方法
ls[i] = x : 替换列表 ls 第 i 个元素为 x
ls[i:j:k] = it : 用列表lt 替换 ls 切片后所对应元素子列表也就是将ls 先进行切片,把【i,j) 给拿出来,然后重新赋值为 lt
del ls[i] : 删除列表中 ls 中 第 i 个元素
del ls[i:j:k] :删除列表 ls 中【i,j) 中以K为步长的元素
ls += lt :更新ls 列表,将 lt 添加到 ls 的尾部
ls *= n : 更新列表ls ,其元素重复n 次
ls.append(x) : 在列表的最后增加一个元素x
ls.clear() : 将列表清空
ls.copy() : 生成一个新的列表,赋值为ls 的所有元素
ls.insert(i,x) :在列表ls 的第 i 位置增加元素x
ls.pop(i) :取出列表 ls 中的第 i 号下标元素
ls.remove(x) : 将列表ls 中出现的第一个元素 x 删除
ls.reverse() : 将列表中的元素进行反转
序列类型的应用场景
1.数据表示
表示一组有序的数据,进而进行操作,就可以是用列表。
如果作为多个返回值,那么就使用元组。
有了这些表示之后,就很容易的进行遍历。
2.数据保护
如果不希望程序对某些数据进行修改,直接转换为元组类型即可。
ls = ["cat","dog","tiger",1024]
lt = tuple(ls)
print(lt)
#结果 : ("cat","dog","tiger",1024)
如此以来这些元素就变得不可更改了
练习:基本统计值计算

总个数:len()
求和 for in
平均值,求和 / 平均值
方差:各数据与平均数差的平方的和的平均值
中位数:排序之后,元素个数为奇数,就找最中间,为偶数个,找中间两个取平均
#先获取用户的输入
def getNum():
nums = []
iNumstr = i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









