






一、ELASTICSEARCH
1.什么叫搜索?
2.为什么mysql不适合全文检索
美丽的%风景
缺点:全表扫描,效率低
3.什么是全文检索倒排索引打分
===========================
1.中国 教育
2.中国 教育 小学
3.中国 教育 中学
4.中国 教育 高中
5.中国 教育 大学
关键词 ids
中国 1,2,3,4,5
教育 1,2,3,4,5
小学 2,3
初中 2
高中 3
大学 4
==========================
4.es的应用场景
- 电商搜索
- 站内搜索
- 代码高亮
- 日志收集
5.es特点
- 分布式
- 高性能
- 高可用
- 容易拓展
- 对运维极其友好
- 配置文件简单
6.es安装部署
安装java rpm包
rpm -ivh jdk-8u102-linux-x64.rpm
查询java版本
java -version
安装elastic search
rpm -ivh elasticsearch-6.6.0.rpm
systemctl daemon-reload
systemctl start elasticsearch.service
tail -f /var/log/elasticsearch/elasticsearch.log
netstat -lntup|grep 9200
curl 127.0.0.1:9200
7.关键配置文件
[root@lb01 ~]# rpm -qc elasticsearch
/etc/elasticsearch/elasticsearch.yml #主配置文件
/etc/elasticsearch/jvm.options #java虚拟机配置文件
/etc/init.d/elasticsearch #init.d的启动文件
/etc/sysconfig/elasticsearch #与环境变量相关的设置,不需要动
/usr/lib/sysctl.d/elasticsearch.conf #最大连接数,不需要动
/usr/lib/systemd/system/elasticsearch.service #systemd启动文件
8.配置文件解读
修改内存大小
[root@lb01 ~]# grep "\-Xm" /etc/elasticsearch/jvm.options
-Xms512m
-Xmx512m
主配置文件
[root@lb01 ~]# egrep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
node.name: node-1 #节点名称,每个节点不一样
path.data: /var/lib/elasticsearch #数据目录
path.logs: /var/log/elasticsearch #日志目录
bootstrap.memory_lock: true #锁定内存设置
network.host: 10.0.0.5,127.0.0.1 #监听网卡地址
http.port: 9200
重新启动会失败
systemctl restart elasticsearch
报错内容:
tail -f /var/log/elasticsearch/elasticsearch.log
[2019-08-29T10:07:29,126][ERROR][o.e.b.Bootstrap ] [node-1] node validation exception
[1] bootstrap checks failed
[1]: memory locking requested for elasticsearch process but memory is not locked
9.解决内存锁定
官方解决方案:
systemctl edit elasticsearch
[Service]
LimitMEMLOCK=infinity
重启服务
systemctl daemon-reload
systemctl restart elasticsearch
10.测试访问
[root@lb01 ~]# curl 127.0.0.1:9200
{
"name" : "node-1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "3Koiaj64TWmo51Cv50W4YQ",
"version" : {
"number" : "6.6.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "a9861f4",
"build_date" : "2019-01-24T11:27:09.439740Z",
"build_snapshot" : false,
"lucene_version" : "7.6.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
11.开放防火墙端口
oot@lb01 ~]# netstat -lntup|grep java
tcp6 0 0 10.0.0.5:9200 :::* LISTEN 10831/java
tcp6 0 0 127.0.0.1:9200 :::* LISTEN 10831/java
tcp6 0 0 10.0.0.5:9300 :::* LISTEN 10831/java
tcp6 0 0 127.0.0.1:9300 :::* LISTEN 10831/java
12.交互方式
- es-head #稍复杂,功能多
- kibana #最简单,功能一般
- curl #最复杂,最难用的一种
es-head插件安装
1.拓展程序-开发者模式
2.加载已解压的拓展程序
3.选中解压后的文件夹
4.连接-10.0.0.5
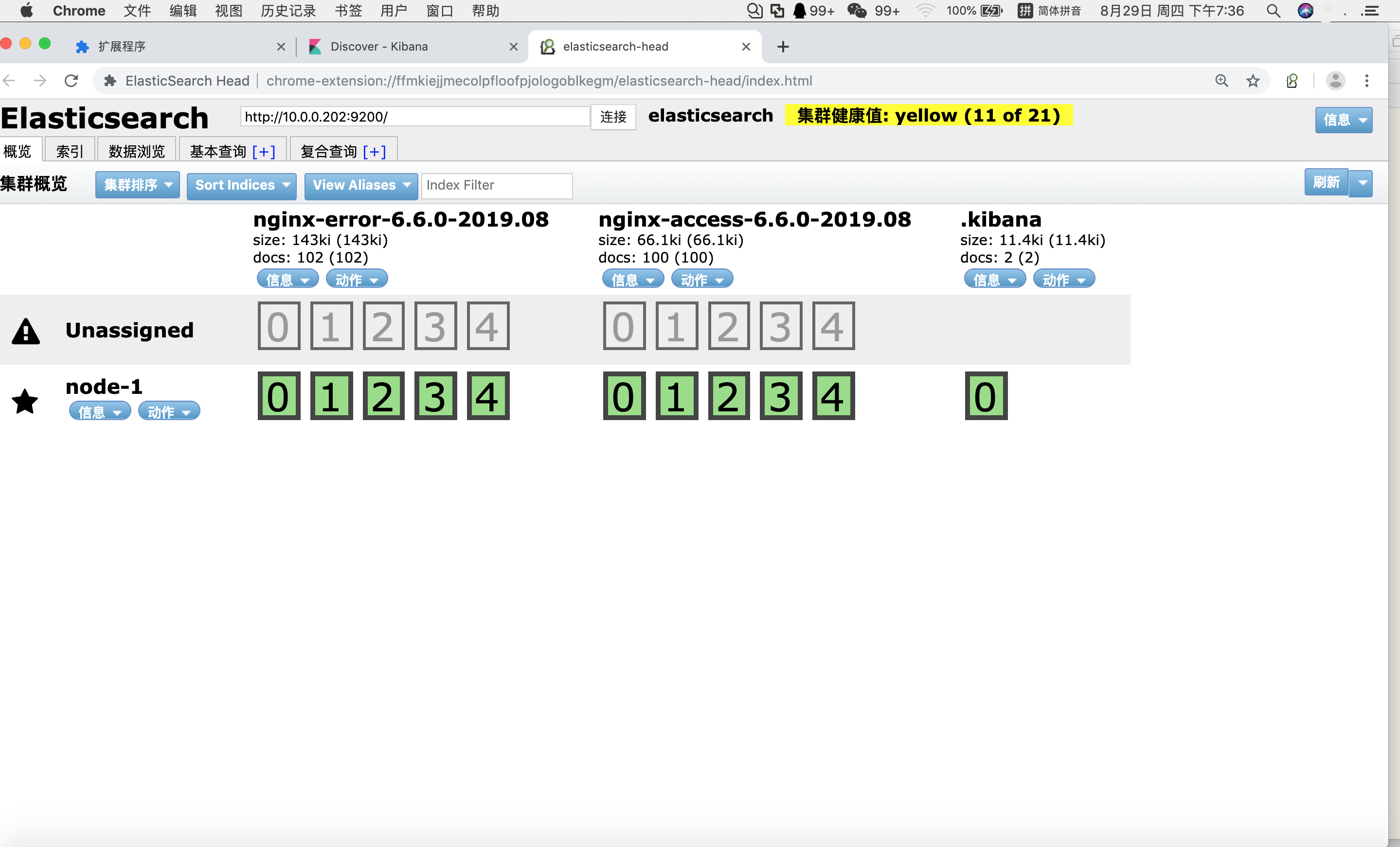
上图即安装配置成功
kibana安装
11.相关术语概念
- 索引
- 分片
- 副本
- 节点
- 集群
- 集群状态
Elasticsearch 数据库
Index - 索引 库
Type - 类型 表
Document - 文档 行
12.操作命令CRUD
- get
- post
- put
- delete
特点:
不需要提前创建索引,如果插入的索引没有,就会自动创建
创建索引
curl -XPUT 'localhost:9200/user?pretty'
解读
ES地址 索引名称/类型/ID
localhost:9200/vipinfo/user/1?pretty
插入数据
curl -XPUT 'localhost:9200/vipinfo/user/1?pretty' -H 'Content-Type: application/json' -d'
{
"first_name" : "John",
"last_name": "Smith",
"age" : 25,
"about" : "I love to go rock climbing", "interests": [ "sports", "music" ]
}
'
curl -XPUT 'localhost:9200/vipinfo/user/2?pretty' -H 'Content-Type: application/json' -d' {
"first_name": "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums", "interests": [ "music" ]
}'
curl -XPUT 'localhost:9200/vipinfo/user/3?pretty' -H 'Content-Type: application/json' -d' {
"first_name": "Douglas", "last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets", "interests": [ "forestry" ]
}'
curl -XPUT 'localhost:9200/vipinfo/user/?pretty' -H 'Content-Type: application/json' -d' {
"first_name": "Douglas", "last_name" : "Fir",
"age" : 33,
"about": "I like to build cabinets", "interests": [ "forestry" ]
}'
如果不指定ID,es会自动生成随机ID
如何解决es随机ID和mysql的Id对应的关系
curl -XPUT 'localhost:9200/vipinfo2/user/?pretty' -H 'Content-Type: application/json' -d' {
"id": 1
"first_name": "Douglas", "last_name" : "Fir",
"age" : 33,
"about": "I like to build cabinets", "interests": [ "forestry" ]
}'
curl -XGET 'localhost:9200/vipinfo/user/_search?pretty' -H 'Content-Type: application/json' -d'{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {"age" : { "gt" : 30 }
}
}
}
}
}'
PUT更新,需要填写完整的信息
curl -XPUT 'localhost:9200/vipinfo/user/1?pretty' -H 'Content-Type: application/json' -d'
{
"first_name" : "John",
"last_name": "Smith",
"age" : 25,
"about" : "I love to go rock climbing", "interests": [ "sports", "music" ]
}
POST更新,只需要填写需要更改的信息
curl -XPOST 'localhost:9200/vipinfo/user/1?pretty' -H 'Content-Type: application/json' -d'
{
"age" : 29
}
13.集群配置文件解读
cluster.name: linux59 #集群名称
node.name: node-2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.0.0.6,127.0.0.1
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.0.0.5", "10.0.0.6"] #集群发现节点IP,注意!不需要写所有的IP,只需要自己本身和集群内任意一台的IP
discovery.zen.minimum_master_nodes: 2 #与选举有关,大多数节点的个数
分片: 存储的数据,提供读写
副本分片: 主分片的备份,只提供读
主节点: 负责调度请求分发到哪台机器
工作节点: 负责处理处理数据的节点
默认主节点也是工作节点
默认分片和副本设置为: 1副本,5分片
集群健康状态:
绿色: 所有副本都满足,所有数据都存在
黄色: 所有数据都存在,但是副本可能不满足
红色: 有的索引数据不完整
默认情况: 索引一旦创建了,分片数就不能更改了,但是可以更改副本数
动态调整副本数:
curl -XPUT 'localhost:9200/index2/user/1?pretty
curl -XPUT 'localhost:9200/user/_settings?pretty' -H 'Content-Type: application/json' -d'
{
"settings" : {
"number_of_replicas" : 2
}
}'
14.集群相关操作API
- 查看集群健康状态
- 查看集群的索引状态
- 查看集群的节点状态
[root@lb02 ~]# curl -XGET 'http://localhost:9200/_cat/health'
1567052431 04:20:31 linux59 green 2 2 20 10 0 0 0 0 - 100.0%
[root@lb02 ~]# curl -XGET 'http://localhost:9200/_cat/nodes?human&pretty'
10.0.0.6 13 97 3 0.31 0.50 0.31 mdi * node-2
10.0.0.7 21 93 1 0.01 0.23 0.25 mdi - node-3
15.模拟故障现象
3台机器关掉1台
3台机器关掉2台
16.kibana管理es集群
17.中文分词器(啃出来)
所有ES节点都需要安装中文分词器
所有ES节点都需要重启
18.优化
内存优化: 最大不要超过32G
场景: 64G内存
12G
16G
30G
只有30G
系统一半
ES一半
硬盘: SSD 2块SSD RAID0
治本: 加机器















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









