






解决scrapy中创建请求,部分url丢失的情况
先感受一下发生的问题
def parse(self, response):
# print(response.text)
book_url = response.xpath('//*[@class="r"]/ul/li/span[1]/a/@href').extract()
print(len(book_url)) #30
for url in book_url:
yield scrapy.Request(url, callback=self.parse_book, dont_filter=True)
def parse_book(self, response):
print(response.url)
遍历url_list中的url,分别创建请求进行二次访问。看一下令人头疼的结果。
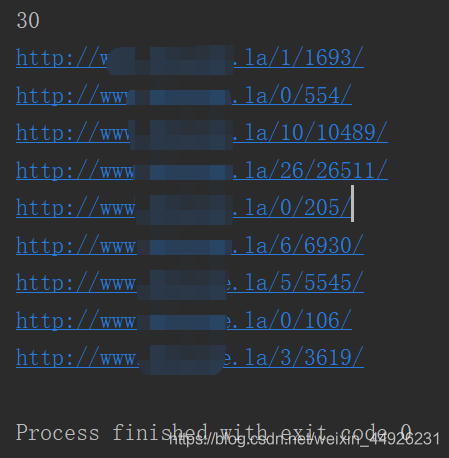
30个url请求成功9个,丢失率超过2/3。
解决方法:
-
1、 添加参数 dont_filter=True
`yield scrapy.Request(url, callback=self.parse_book, dont_filter=True)` -
2、修改配置文件中的参数
# Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: CONCURRENT_REQUESTS_PER_DOMAIN = 16 CONCURRENT_REQUESTS_PER_IP = 16 -
3、降低delay
# Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs # DOWNLOAD_DELAY = 3 DOWNLOAD_DELAY = 0.5 # The download delay setting will honor only one of: CONCURRENT_REQUESTS_PER_DOMAIN = 16 CONCURRENT_REQUESTS_PER_IP = 16
验证
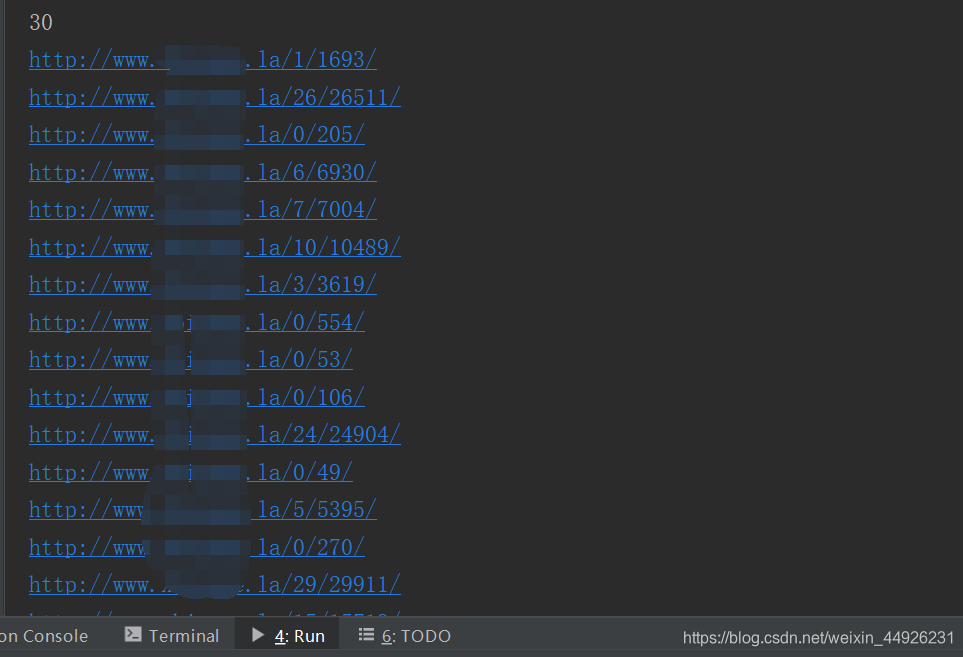














 1595
1595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









