







The Boyer–Moore string search algorithm is a particularly efficient string searching algorithm. It was developed by Bob Boyer and J Strother Moore in 1977. The algorithm preprocesses the target string (key) that is being searched for, but not the string being searched (unlike some algorithms which preprocess the string to be searched, and can then amortize the expense of the preprocessing by searching repeatedly). The execution time of the Boyer-Moore algorithm can actually be sub-linear: it doesn’t need to actually check every character of the string to be searched but rather skips over some of them. Generally the algorithm gets faster as the key being searched for becomes longer. Its efficiency derives from the fact that, with each unsuccessful attempt to find a match between the search string and the text it’s searching in, it uses the information gained from that attempt to rule out as many positions of the text as possible where the string could not match.
How the algorithm works
What people frequently find surprising about the Boyer-Moore algorithm when they first encounter it is that its verifications – its attempts to check whether a match exists at a particular position – work backwards. If it starts a search at the beginning of a text for the word “ANPANMAN”, for instance, it checks the eighth position of the text to see if it contains an “N”. If it finds the “N”, it moves to the seventh position to see if that contains the last “A” of the word, and so on until it checks the first position of the text for a “A”. Why Boyer-Moore takes this backward approach is clearer when we consider what happens if the verification fails – for instance, if instead of an “N” in the eighth position, we find an “X”. The “X” doesn’t appear anywhere in “ANPANMAN”, and this means there is no match for the search string at the very start of the text – or at the next seven positions following it, since those would all fall across the “X” as well. After checking just one character, we’re able to skip ahead and start looking for a match starting at the ninth position of the text, just after the “X”. This explains why the best-case performance of the algorithm, for a text of length N and a fixed pattern of length M, is N/M: in the best case, only one in M characters needs to be checked. This also explains the somewhat counter-intuitive result that the longer the pattern we are looking for, the faster the algorithm will be usually able to find it. The algorithm precomputes two tables to process the information it obtains in each failed verification: one table calculates how many positions ahead to start the next search based on the identity of the character that caused the match attempt to fail; the other makes a similar calculation based on how many characters were matched successfully before the match attempt failed. (Because these two tables return results indicating how far ahead in the text to “jump”, they are sometimes called “jump tables”, which should not be confused with the more common meaning of jump tables in computer science.)

the first table
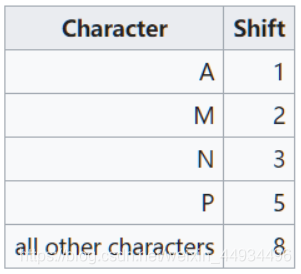
The first table is easy to calculate: Start at the last character of the sought string and move towards the first character. Each time you move left, if the character you are on is not in the table already, add it; its Shift value is its distance from the rightmost character. All other characters receive a count equal to the length of the search string.
Example: For the string ANPANMAN, the first table would be as shown (for clarity, entries are shown in the order they would be added to the table):(The N which is supposed to be zero is based on the 2nd N from the right because we only calculate from letters m-1)
The amount of shift calculated by the first table is sometimes called the “bad character shift”[1].
the second table
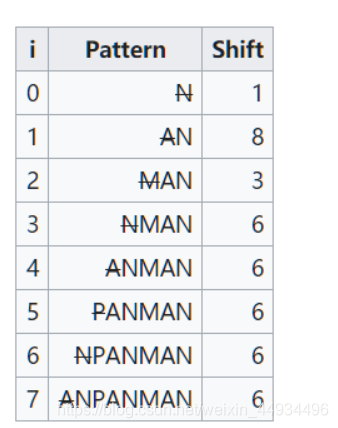
The second table is slightly more difficult to calculate: for each value of i less than the length of the search string, we must first calculate the pattern consisting of the last i characters of the search string, preceded by a mis-match for the character before it; then we initially line it up with the search pattern and determine the least number of characters the partial pattern must be shifted left before the two patterns match. For instance, for the search string ANPANMAN, the table would be as follows: (N signifies any character that is not N)

The amount of shift calculated by the second table is sometimes called the “good suffix shift”[2] or “(strong) good suffix rule”. The original published Boyer-Moor algorithm [1] uses a simpler, weaker, version of the good suffix rule in which each entry in the above table did not require a mis-match for the left-most character. This is sometimes called the “weak good suffix rule” and is not sufficient for proving that Boyer-Moore runs in linear worst-case time.
Performance of the Boyer-Moore string search algorithm
The worst-case to find all occurrences in a text needs approximately 3N comparisons, hence the complexity is O(n), regardless whether the text contains a match or not. The proof is due to Richard Cole, see R. COLE,Tight bounds on the complexity of the Boyer-Moore algorithm,Proceedings of the 2nd Annual ACM-SIAM Symposium on Discrete Algorithms, (1991) for details. This proof took some years to determine. In the year the algorithm was devised, 1977, the maximum number of comparisons was shown to be no more than 6N; in 1980 it was shown to be no more than 4*N, until Cole’s result in 1991.
输入
two lines and only characters “ACGT” in the string. the first line
is string (< = 102000) the second line is text(< = 700000)
输出
position of the string in text else -1
样例输入
GGCCTCATATCTCTCT
CCCATTGGCCTCATATCTCTCTCCCTCCCTCCCCTGCCCAGGCTGCTTGGCATGG
样例输出
6
- 不要被这一大片英文吓到了,它就是介绍这个算法的。
- 这道题的主要问题就是叫你用Boyer–Moore–Horspool算法 在一个text中找有没有目标str,如果有就输出str的首个字符在txet中的位置,否则输出-1
Boyer–Moore–Horspool算法有两个启发规则:
坏字符启发法和好后缀启发法
这道题相对简单,就只用坏字符启发法
这里是boyer-moore的讲解
下面是本道题的步骤:
- 先建立一个字母表,用来储存str中出现的每个字符最后一次出现的位置,比如:str="SIPPLE"中S最后出现的位置是0、I最后出现的位置是1,P是3,L是4,E是5
- 开始比较,将str和text左对齐,从str的最右边开始比较。如果比较都匹配就返回str的开头字符的位置,否则就把str向右移(规则就是坏字符启发法)直到到达text的最右边

比如:
UGOOD
AUOODAUGOOD - 这是在G和U处遇到不匹配的,U是text中的,所以U是坏字符,
- U在模式中失配的位置(也就是在和str比较时第几位出现了不匹配)是 1,
- U在模式中最后一次出现的位置是(也就是看str里面有没有U,找str中U最后出现的位置,如果没有U,那位置就是-1)0
- 所以后移位数为1-0=1

然后又用相同的办法来寻找匹配
#include<iostream>
#include<cstring>
using namespace std;
int form[26];//用来记录 str中的字母 最后一次出现的位置
int match(string str,string text)
{
int length_str,length_text;
length_str = str.length();
length_text = text.length();
for(int i=0;i<length_str - 1;i++)
{
form[str[i]-'A'] = i;
//form[str[i] - 'A'] = length_str - i - 1;
}
int p = length_str - 1; //用来记录str最后一个字母 在text中 开始对比的位置
while(p<length_text)
{
int j=0;
while(str[length_str-1-j] == text[p-j]&&j<length_str)//从右到左对比
{
j++;
}
if(j==length_str)
{
return (p + 1 - length_str);
}
//p += form[text[p]-'A'];
int shipei = length_str-j-1; //坏字符在模式中失配的位置
int last_show = form[text[p-j]-'A'];//坏字符在模式中最后一次出现的位置
if(shipei>=last_show) //可能会出现 last_show>shipei的情况 比如str:SIMPLE text:SPMPLESIMPLE ,导致str无法向右移动
p += (shipei-last_show);//模式后移位数 = 坏字符在模式中失配的位置 - 坏字符在模式中最后一次出现的位置
else p++;
//p += form[text[p]-'A'];
}
return -1;
}
int main()
{
memset(form, -1, sizeof(form));//置-1
string aim,text;
cin >> aim >> text;
cout <<match(aim,text)<<endl;
return 0;
}

















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









