







分类
加载数据
书上的代码根本运行不了,所以百度下载了数据文件。MNIST数据是.mat文件(matlab文件),读写.mat文件使用scipy.io模块
import scipy.io as sio
import os
path1 = r'C:\Users\点解\scikit_learn_data\mldata'
mat_path = os.path.join(path1, 'mnist-original.mat')
mnist = sio.loadmat(mat_path)
mnist
可以看见,data键,包含一个数组,每个实例为一行,每个特征为一列;label键,包含一个带有标记的数组。
X = mnist["data"].T
y = mnist["label"].T
print(X.shape)
print(y.shape)
输出:
(70000, 784)
(70000, 1)
这里注意需要转置一下。将每行表示为一个实例,每列表示一个实例所包含的特征值。这里表示,共有7万张图片,每张图片有784个特征.(2828=784),表示图片是2828像素的,每个特征代表了一个点的像素强度,从0(白色)到255(黑色)。
我们可以显示一个图片来看看:
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
some_digit = X[36000]
some_digit_image = some_digit.reshape(28, 28)
plt.imshow(some_digit_image, cmap = matplotlib.cm.binary, interpolation = "nearest")
plt.axis("off")
plt.show()
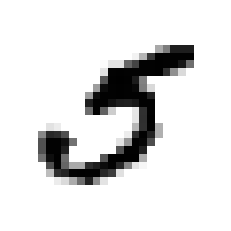
验证一下:
y[36000]
输出:
array([5.])
可见确实是5。
将数据集分成训练集和测试集
创建测试集和训练集。前6万张图像设为训练集,最后1万张图像设为测试集。并将训练数据洗牌,以保证交叉验证时所有折叠都差不多。
import numpy as np
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
X_train ——>训练集数据 X_test ——>测试集数据
y_train ——>训练集标记 y_test ——>测试集标记
首先训练一个二分类器(检测5与非5)
创建标志:当y_train = =5时,y_train_5表示1否则为0
y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5)
数据已经准备好了,可以选择模型来训练了。
1、初始选择:随机梯度下降分类器
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state = 42)
sgd_clf.fit(X_train, y_train_5.ravel())
验证一下前面显示的5是否能被准确预测:
sgd_clf.predict(some_digit.reshape(1, -1))
输出:
array([ True])
可见被准确预测。
训练好后我们要讨论这个模型是否是最佳的需要性能考核&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









