







文章目录
一、直接调用xgb的库
1.调用xgb的库
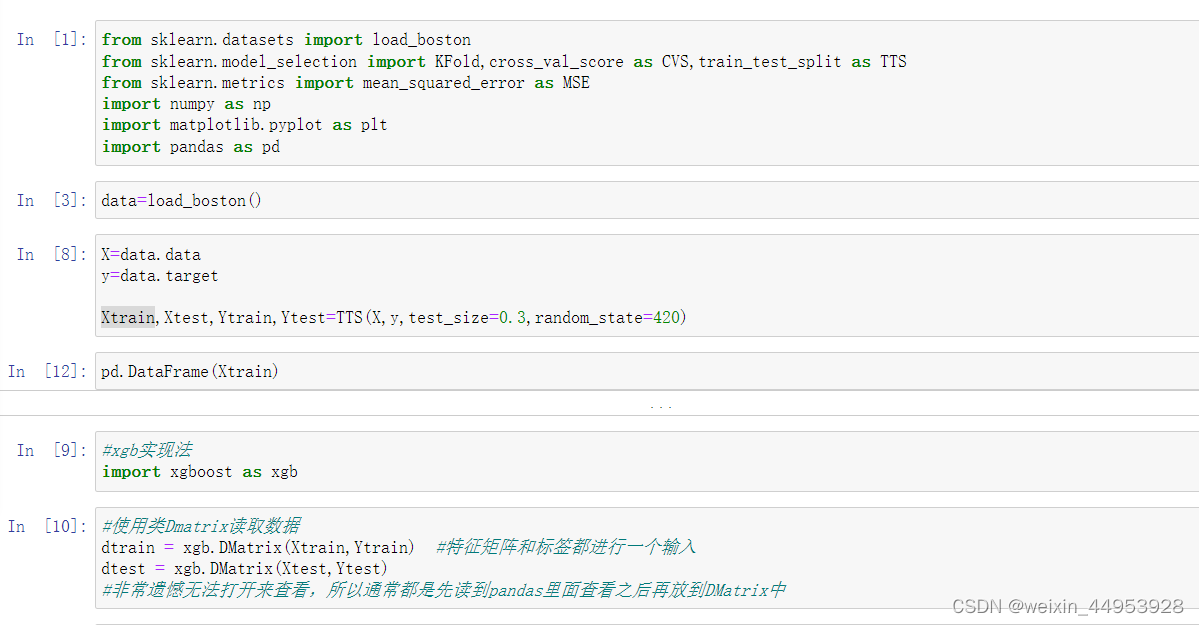
导入数据
from sklearn.datasets import load_boston
from sklearn.model_selection import KFold,cross_val_score as CVS,train_test_split as TTS
from sklearn.metrics import mean_squared_error as MSE
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
data=load_boston()
X=data.data
y=data.target
Xtrain,Xtest,Ytrain,Ytest=TTS(X,y,test_size=0.3,random_state=420)
pd.DataFrame(Xtrain)
导入XGBoost库
#xgb实现法
import xgboost as xgb
#使用类Dmatrix读取数据
dtrain = xgb.DMatrix(Xtrain,Ytrain) #特征矩阵和标签都进行一个输入
dtest = xgb.DMatrix(Xtest,Ytest)
#非常遗憾无法打开来查看,所以通常都是先读到pandas里面查看之后再放到DMatrix中
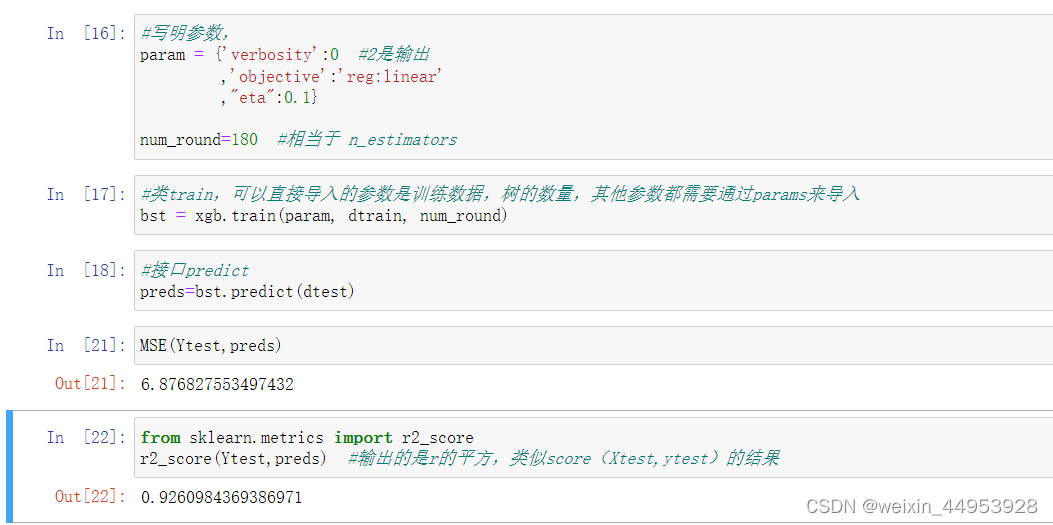
#写明参数,
param = {'verbosity':0 #2是输出
,'objective':'reg:linear'
,"eta":0.1}
num_round=180 #相当于 n_estimators
#类train,可以直接导入的参数是训练数据,树的数量,其他参数都需要通过params来导入
bst = xgb.train(param, dtrain, num_round)
#接口predict
preds=bst.predict(dtest)
MSE(Ytest,preds)
#6.876827553497432
from sklearn.metrics import r2_score
r2_score(Ytest,preds) #输出的是r的平方,类似score(Xtest,ytest)的结果
#0.9260984369386971
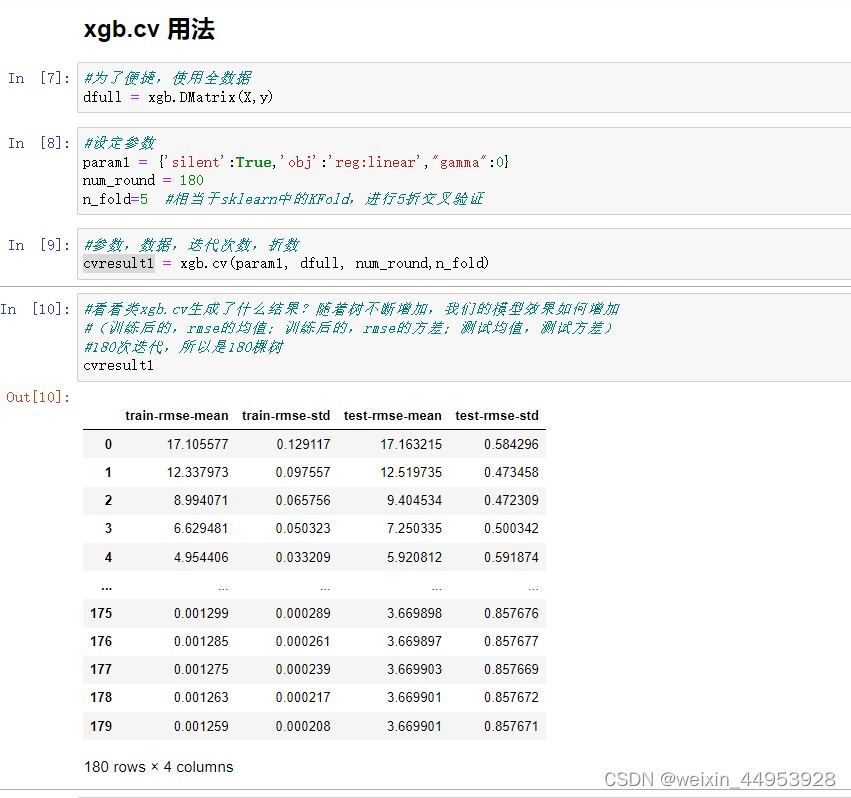
2.xgb.cv(param1, dfull, num_round,n_fold)
有了xgboost.cv这个工具,我们的参数调整就容易多了。这个工具可以让我们直接看到参数如何影响了模型的泛化能
力。接下来,我们将重点讲解如何使用xgboost.cv这个类进行参数调整。
参数,数据,迭代次数,折数
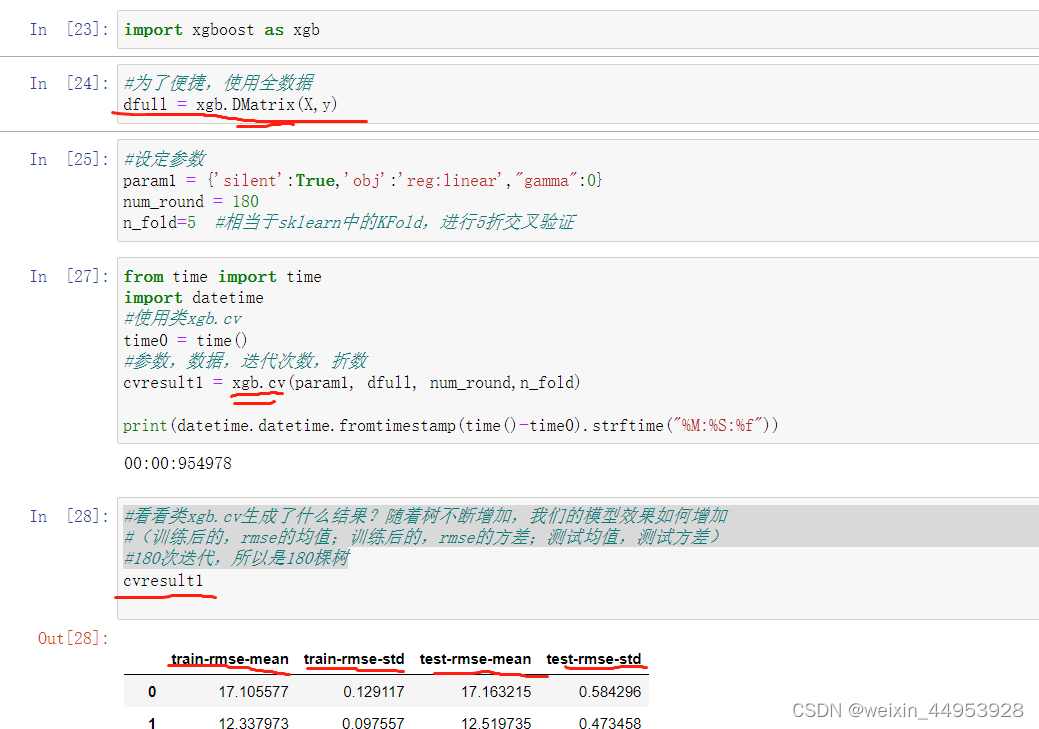
看看类xgb.cv生成了什么结果?随着树不断增加,我们的模型效果如何增加
(训练后的,rmse的均值;训练后的,rmse的方差;测试均值,测试方差)
180次迭代,所以是180棵树
import xgboost as xgb
#为了便捷,使用全数据
dfull = xgb.DMatrix(X,y)
#设定参数
param1 = {'silent':True,'obj':'reg:linear',"gamma":0}
num_round = 180
n_fold=5 #相当于sklearn中的KFold,进行5折交叉验证
#参数,数据,迭代次数,折数
cvresult1 = xgb.cv(param1, dfull, num_round,n_fold)
#看看类xgb.cv生成了什么结果?随着树不断增加,我们的模型效果如何增加
#(训练后的,rmse的均值;训练后的,rmse的方差;测试均值,测试方差)
#180次迭代,所以是180棵树
cvresult1
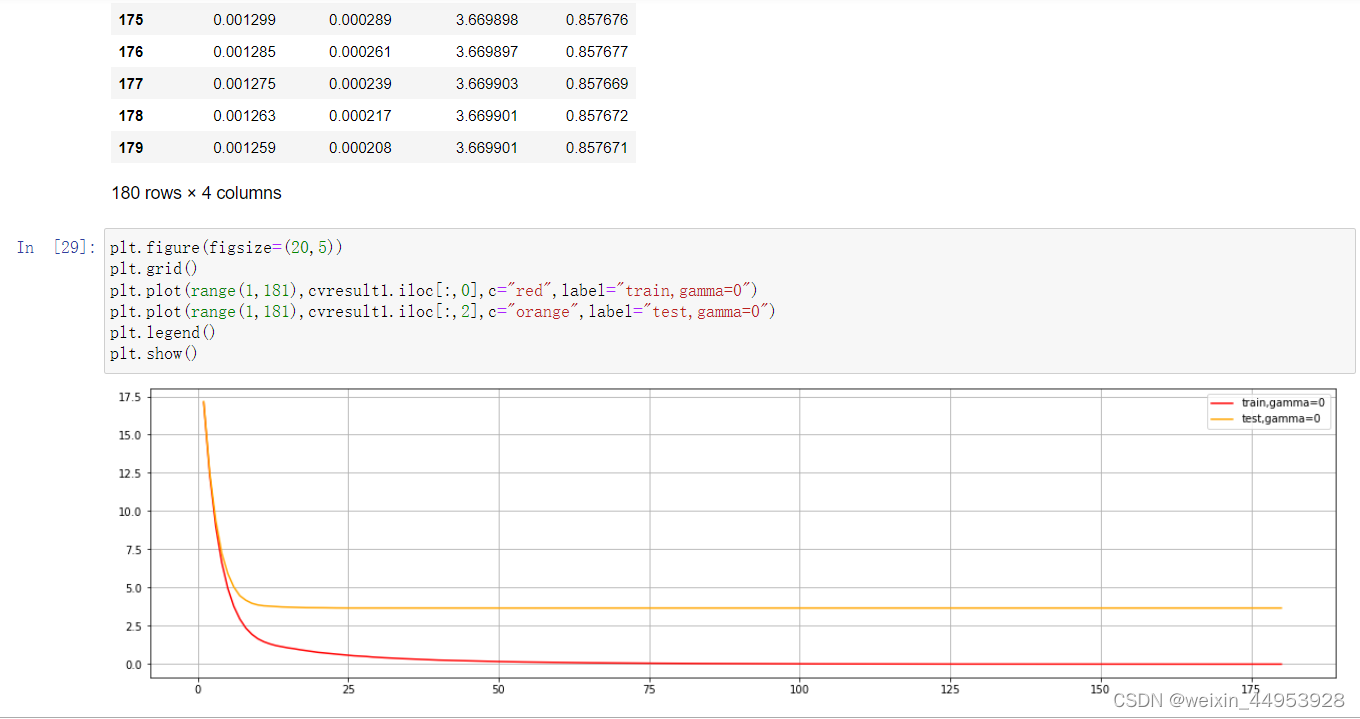
plt.figure(figsize=(20,5))
plt.grid()
plt.plot(range(1,181),cvresult1.iloc[:,0],c="red",label="train,gamma=0")
plt.plot(range(1,181),cvresult1.iloc[:,2],c="orange",label="test,gamma=0")
plt.legend()
plt.show()
param1 = {'silent':True,'obj':'reg:linear',"gamma":0,"eval_metric":"mae"}
cvresult1 = xgb.cv(param1, dfull, num_round,n_fold)
plt.figure(figsize=(20,5))
plt.grid()
plt.plot(range(1,181),cvresult1.iloc[:,0],c="red",label="train,gamma=0")
plt.plot(range(1,181),cvresult1.iloc[:,2],c="orange",label="test,gamma=0")
plt.legend()
plt.show()
#从这个图中,我们可以看出什么?
#怎样从图中观察模型的泛化能力?
#从这个图的角度来说,模型的调参目标是什么?
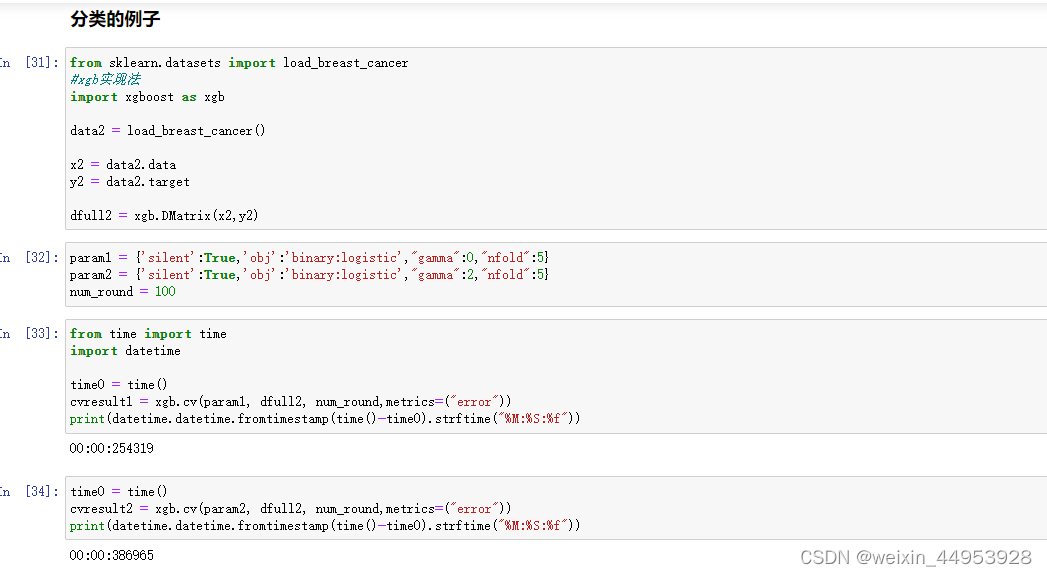
3.分类算法使用
from sklearn.datasets import load_breast_cancer
#xgb实现法
import xgboost as xgb
data2 = load_breast_cancer()
x2 = data2.data
y2 = data2.target
dfull2 = xgb.DMatrix(x2,y2)
param1 = {'silent':True,'obj':'binary:logistic',"gamma":0,"nfold":5}
param2 = {'silent':True,'obj':'binary:logistic',"gamma":2,"nfold":5}
num_round = 100
from time import time
import datetime
time0 = time()
cvresult1 = xgb.cv(param1, dfull2, num_round,metrics=("error"))
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
time0 = time()
cvresult2 = xgb.cv(param2, dfull2, num_round,metrics=("error"))
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
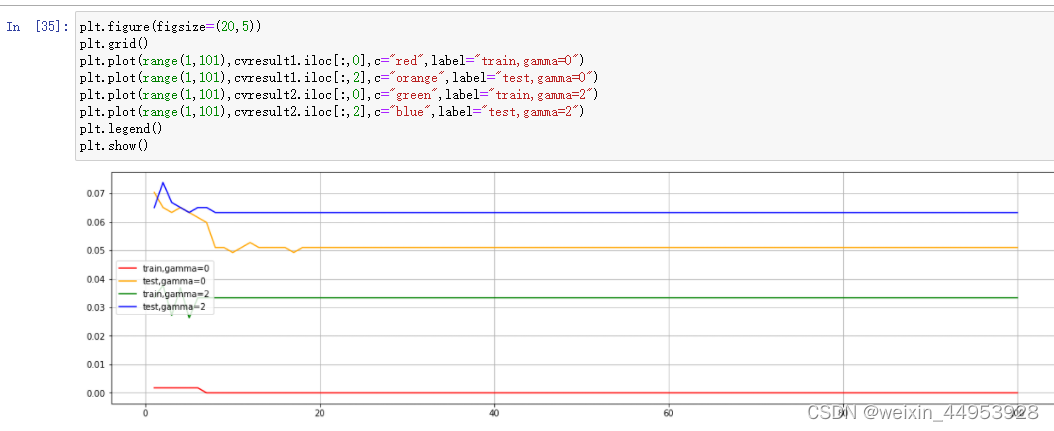
plt.figure(figsize=(20,5))
plt.grid()
plt.plot(range(1,101),cvresult1.iloc[:,0],c="red",label="train,gamma=0")
plt.plot(range(1,101),cvresult1.iloc[:,2],c="orange",label="test,gamma=0")
plt.plot(range(1,101),cvresult2.iloc[:,0],c="green",label="train,gamma=2")
plt.plot(range(1,101),cvresult2.iloc[:,2],c="blue",label="test,gamma=2")
plt.legend()
plt.show()
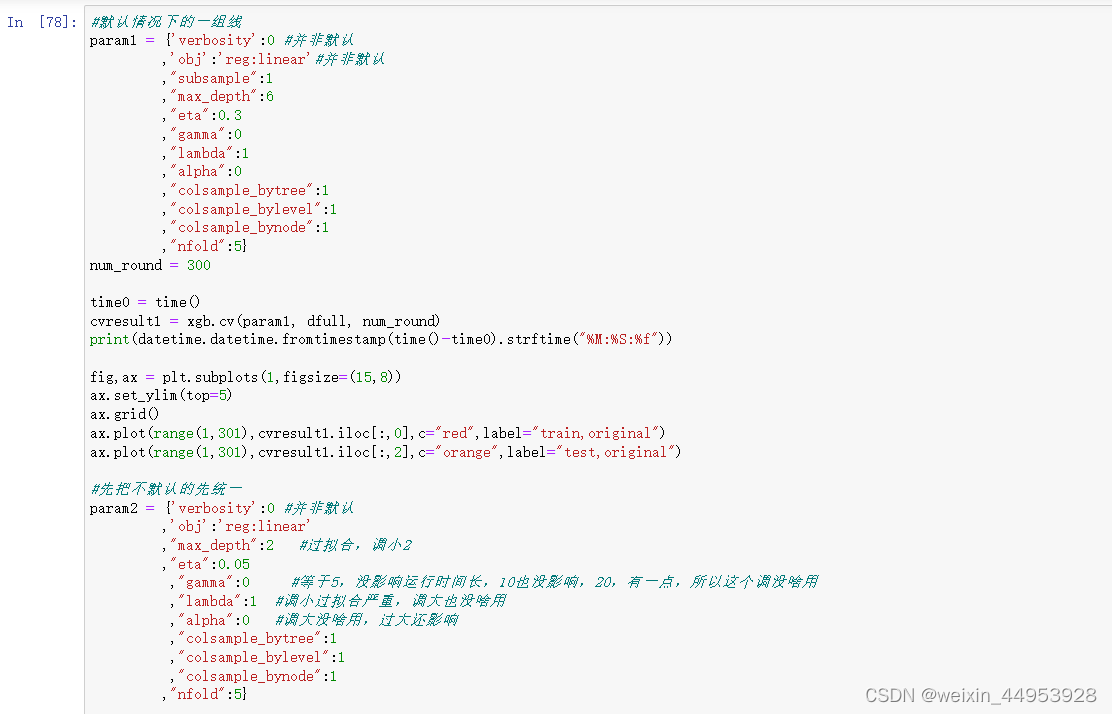
综合调参:使用 xgb.cv调参
#默认情况下的一组线
param1 = {'verbosity':0 #并非默认
,'obj':'reg:linear'#并非默认
,"subsample":1
,"max_depth":6
,"eta":0.3
,"gamma":0
,"lambda":1
,"alpha":0
,"colsample_bytree":1
,"colsample_bylevel":1
,"colsample_bynode":1
,"nfold":5}
num_round = 300
time0 = time()
cvresult1 = xgb.cv(param1, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
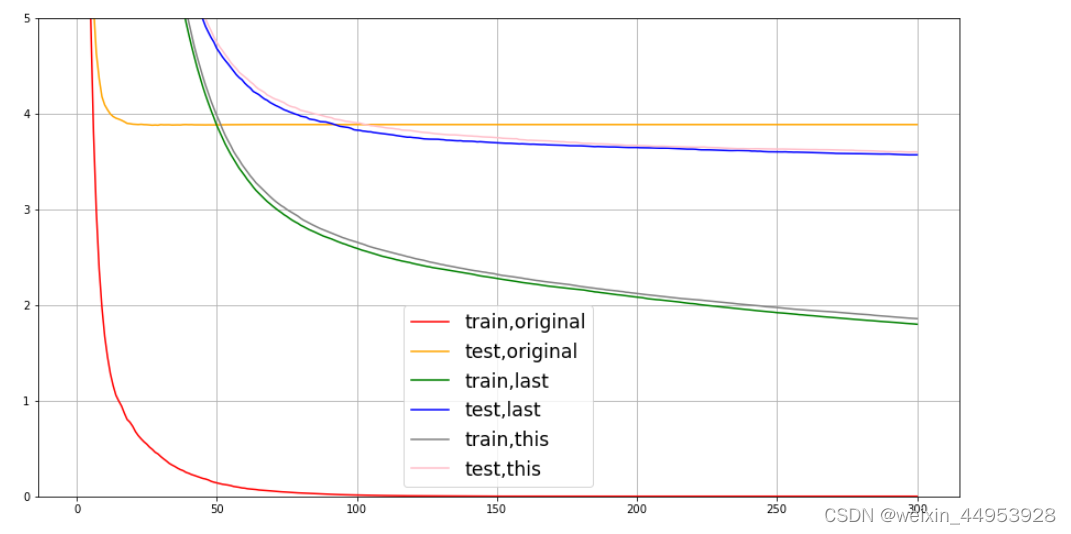
fig,ax = plt.subplots(1,figsize=(15,8))
ax.set_ylim(top=5)
ax.grid()
ax.plot(range(1,301),cvresult1.iloc[:,0],c="red",label="train,original")
ax.plot(range(1,301),cvresult1.iloc[:,2],c="orange",label="test,original")
# ax.legend(fontsize="xx-large")
# plt.show()
#先把不默认的先统一
param2 = {'verbosity':0 #并非默认
,'obj':'reg:linear'
,"max_depth":2 #过拟合,调小2
,"eta":0.05
,"gamma":0 #等于5,没影响运行时间长,10也没影响,20,有一点,所以这个调没啥用
,"lambda":1 #调小过拟合严重,调大也没啥用
,"alpha":0 #调大没啥用,过大还影响
,"colsample_bytree":1
,"colsample_bylevel":1
,"colsample_bynode":1
,"nfold":5}
param3 = {'verbosity':0 #并非默认
,'obj':'reg:linear'
,"max_depth":2 #过拟合,调小3,与上面对比,看到没有2好,在换成1看看,不好
,"eta":0.05
,"gamma":0
,"lambda":1
,"alpha":1
,"colsample_bytree":1
,"colsample_bylevel":1
,"colsample_bynode":0.5
,"nfold":5}
time0 = time()
cvresult2 = xgb.cv(param2, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
time0 = time()
cvresult3 = xgb.cv(param3, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
ax.plot(range(1,301),cvresult2.iloc[:,0],c="green",label="train,last")
ax.plot(range(1,301),cvresult2.iloc[:,2],c="blue",label="test,last")
ax.plot(range(1,301),cvresult3.iloc[:,0],c="gray",label="train,this")
ax.plot(range(1,301),cvresult3.iloc[:,2],c="pink",label="test,this")
ax.legend(fontsize="xx-large")
plt.show()

xgb.CV输出的结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









