








文章目录
2.1 新闻主题分类任务
学习目标
了解有关新闻主题分类和有关数据.
掌握使用浅层网络构建新闻主题分类器的实现过程.
关于新闻主题分类任务:
以一段新闻报道中的文本描述内容为输入, 使用模型帮助我们判断它最有可能属于哪一种类型的新闻, 这是典型的文本分类问题, 我们这里假定每种类型是互斥的, 即文本描述有且只有一种类型.
新闻主题分类数据: 通过torchtext获取数据:
# 导入相关的torch工具包
import torch
import torchtext
# 导入torchtext.datasets中的文本分类任务
from torchtext.datasets import text_classification
import os
# 定义数据下载路径, 当前路径的data文件夹
load_data_path = "./data"
# 如果不存在该路径, 则创建这个路径
if not os.path.isdir(load_data_path):
os.mkdir(load_data_path)
# 选取torchtext中的文本分类数据集'AG_NEWS'即新闻主题分类数据, 保存在指定目录下
# 并将数值映射后的训练和验证数据加载到内存中
train_dataset, test_dataset = text_classification.DATASETS['AG_NEWS'](root=load_data_path)
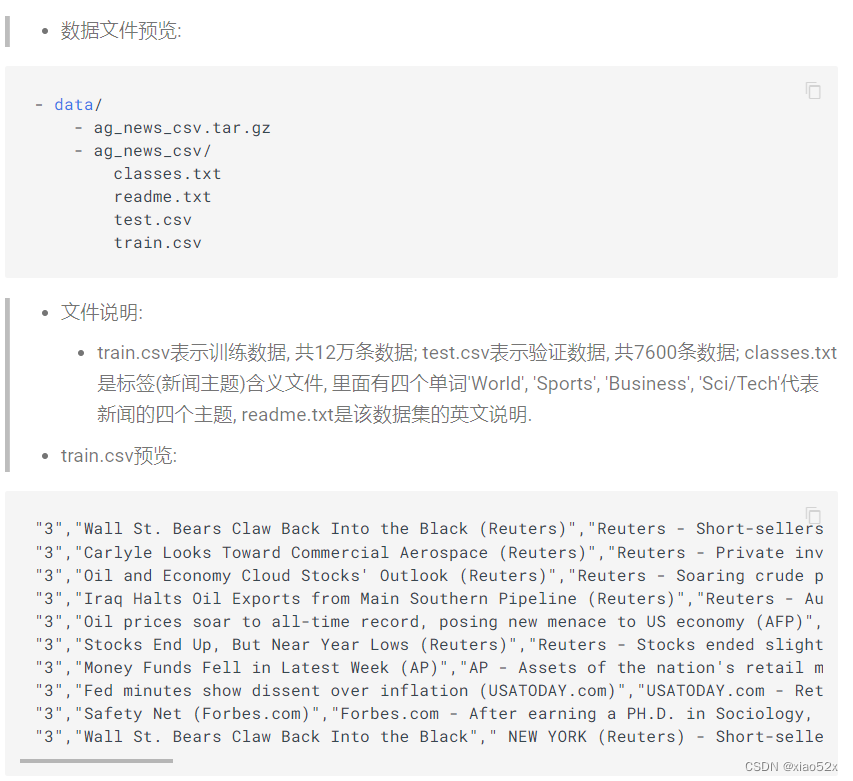
文件内容说明:
- train.csv共由3列组成, 使用’,'进行分隔, 分别代表: 标签, 新闻标题, 新闻简述; 其中标签用"1", “2”, “3”, "4"表示, 依次对应classes中的内容.
- test.csv与train.csv内容格式与含义相同.
2.2 整个案例的实现可分为以下五个步骤
第一步: 构建带有Embedding层的文本分类模型.
第二步: 对数据进行batch处理.
第三步: 构建训练与验证函数.
第四步: 进行模型训练和验证.
第五步: 查看embedding层嵌入的词向量.
第一步: 构建带有Embedding层的文本分类模型.
# 导入必备的torch模型构建工具
import torch.nn as nn
import torch.nn.functional as F
# 指定BATCH_SIZE的大小
BATCH_SIZE = 16
# 进行可用设备检测, 有GPU的话将优先使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class TextSentiment(nn.Module):
"""文本分类模型"""
def __init__(self, vocab_size, embed_dim, num_class):
"""
description: 类的初始化函数
:param vocab_size: 整个语料包含的不同词汇总数
:param embed_dim: 指定词嵌入的维度
:param num_class: 文本分类的类别总数
"""
super().__init__()
# 实例化embedding层, sparse=True代表每次对该层求解梯度时, 只更新部分权重.
self.embedding = nn.Embedding(vocab_size, embed_dim, sparse=True)
# 实例化线性层, 参数分别是embed_dim和num_class.
self.fc = nn.Linear(embed_dim, num_class)
# 为各层初始化权重
self.init_weights()
def init_weights(self):
"""初始化权重函数"""
# 指定初始权重的取值范围数
initrange = 0.5
# 各层的权重参数都是初始化为均匀分布
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
# 偏置初始化为0
self.fc.bias.data.zero_()
def forward(self, text):
"""
:param text: 文本数值映射后的结果
:return: 与类别数尺寸相同的张量, 用以判断文本类别
"""
# 获得embedding的结果embedded
# >>> embedded.shape
# (m, 32) 其中m是BATCH_SIZE大小的数据中词汇总数
embedded = self.embedding(text)
# 接下来我们需要将(m, 32)转化成(BATCH_SIZE, 32)
# 以便通过fc层后能计算相应的损失
# 首先, 我们已知m的值远大于BATCH_SIZE=16,
# 用m整除BATCH_SIZE, 获得m中共包含c个BATCH_SIZE
c = embedded.size(0) // BATCH_SIZE
# 之后再从embedded中取c*BATCH_SIZE个向量得到新的embedded
# 这个新的embedded中的向量个数可以整除BATCH_SIZE
embedded = embedded[:BATCH_SIZE*c]
# 因为我们想利用平均池化的方法求embedded中指定行数的列的平均数,
# 但平均池化方法是作用在行上的, 并且需要3维输入
# 因此我们对新的embedded进行转置并拓展维度
embedded = embedded.transpose(1, 0).unsqueeze(0)
# 然后就是调用平均池化的方法, 并且核的大小为c
# 即取每c的元素计算一次均值作为结果
embedded = F.avg_pool1d(embedded, kernel_size=c)
# 最后,还需要减去新增的维度, 然后转置回去输送给fc层
return self.fc(embedded[0].transpose(1, 0))
- 实例化模型:
# 获得整个语料包含的不同词汇总数
VOCAB_SIZE = len(train_dataset.get_vocab())
# 指定词嵌入维度
EMBED_DIM = 32
# 获得类别总数
NUN_CLASS = len(train_dataset.get_labels())
# 实例化模型
model = TextSentiment(VOCAB_SIZE, EMBED_DIM, NUN_CLASS).to(device)
第二步: 对数据进行batch处理.
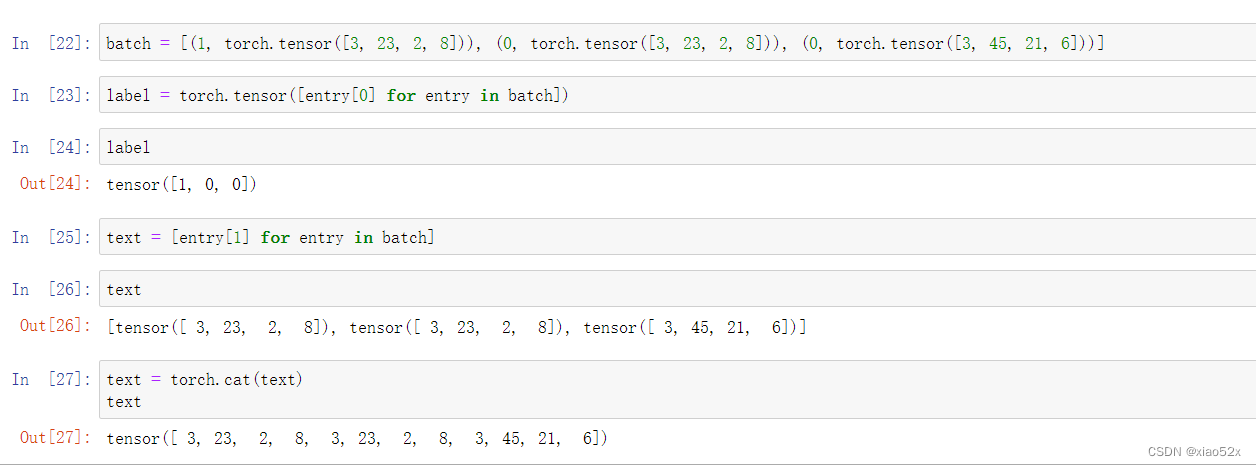
def generate_batch(batch):
"""
description: 生成batch数据函数
:param batch: 由样本张量和对应标签的元组组成的batch_size大小的列表
形如:
[(label1, sample1), (lable2, sample2), ..., (labelN, sampleN)]
return: 样本张量和标签各自的列表形式(张量)
形如:
text = tensor([sample1, sample2, ..., sampleN])
label = tensor([label1, label2, ..., labelN])
"""
# 从batch中获得标签张量
label = torch.tensor([entry[0] for entry in batch])
# 从batch中获得样本张量
text = [entry[1] for entry in batch]
text = torch.cat(text)
# 返回结果
return text, label
调用:
# 假设一个输入:
batch = [(1, torch.tensor([3, 23, 2, 8])), (0, torch.tensor([3, 45, 21, 6]))]
res = generate_batch(batch)
print(res)
# 对应输入的两条数据进行了相应的拼接
(tensor([ 3, 23, 2, 8, 3, 45, 21, 6]), tensor([1, 0]))
第三步: 构建训练与验证函数.
# 导入torch中的数据加载器方法
from torch.utils.data import DataLoader
def train(train_data):
"""模型训练函数"""
# 初始化训练损失和准确率为0
train_loss = 0
train_acc = 0
# 使用数据加载器生成BATCH_SIZE大小的数据进行批次训练
# data就是N多个generate_batch函数处理后的BATCH_SIZE大小的数据生成器
data = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True,
collate_fn=generate_batch)
# 对data进行循环遍历, 使用每个batch的数据进行参数更新
for i, (text, cls) in enumerate(data):
# 设置优化器初始梯度为0
optimizer.zero_grad()
# 模型输入一个批次数据, 获得输出
output = model(text)
# 根据真实标签与模型输出计算损失
loss = criterion(output, cls)
# 将该批次的损失加到总损失中
train_loss += loss.item()
# 误差反向传播
loss.backward()
# 参数进行更新
optimizer.step()
# 将该批次的准确率加到总准确率中
train_acc += (output.argmax(1) == cls).sum().item()
# 调整优化器学习率
scheduler.step()
# 返回本轮训练的平均损失和平均准确率
return train_loss / len(train_data), train_acc / len(train_data)
def valid(valid_data):
"""模型验证函数"""
# 初始化验证损失和准确率为0
loss = 0
acc = 0
# 和训练相同, 使用DataLoader获得训练数据生成器
data = DataLoader(valid_data, batch_size=BATCH_SIZE, collate_fn=generate_batch)
# 按批次取出数据验证
for text, cls in data:
# 验证阶段, 不再求解梯度
with torch.no_grad():
# 使用模型获得输出
output = model(text)
# 计算损失
loss = criterion(output, cls)
# 将损失和准确率加到总损失和准确率中
loss += loss.item()
acc += (output.argmax(1) == cls).sum().item()
# 返回本轮验证的平均损失和平均准确率
return loss / len(valid_data), acc / len(valid_data)
第四步: 进行模型训练和验证.
# 导入时间工具包
import time
# 导入数据随机划分方法工具
from torch.utils.data.dataset import random_split
# 指定训练轮数
N_EPOCHS = 10
# 定义初始的验证损失
min_valid_loss = float('inf')
# 选择损失函数, 这里选择预定义的交叉熵损失函数
criterion = torch.nn.CrossEntropyLoss().to(device)
# 选择随机梯度下降优化器
optimizer = torch.optim.SGD(model.parameters(), lr=4.0)
# 选择优化器步长调节方法StepLR, 用来衰减学习率
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.9)
# 从train_dataset取出0.95作为训练集, 先取其长度
train_len = int(len(train_dataset) * 0.95)
# 然后使用random_split进行乱序划分, 得到对应的训练集和验证集
sub_train_, sub_valid_ = \
random_split(train_dataset, [train_len, len(train_dataset) - train_len])
# 开始每一轮训练
for epoch in range(N_EPOCHS):
# 记录概论训练的开始时间
start_time = time.time()
# 调用train和valid函数得到训练和验证的平均损失, 平均准确率
train_loss, train_acc = train(sub_train_)
valid_loss, valid_acc = valid(sub_valid_)
# 计算训练和验证的总耗时(秒)
secs = int(time.time() - start_time)
# 用分钟和秒表示
mins = secs / 60
secs = secs % 60
# 打印训练和验证耗时,平均损失,平均准确率
print('Epoch: %d' %(epoch + 1), " | time in %d minutes, %d seconds" %(mins, secs))
print(f'\tLoss: {train_loss:.4f}(train)\t|\tAcc: {train_acc * 100:.1f}%(train)')
print(f'\tLoss: {valid_loss:.4f}(valid)\t|\tAcc: {valid_acc * 100:.1f}%(valid)')
120000lines [00:06, 17834.17lines/s]
120000lines [00:11, 10071.77lines/s]
7600lines [00:00, 10432.95lines/s]
Epoch: 1 | time in 0 minutes, 36 seconds
Loss: 0.0592(train) | Acc: 63.9%(train)
Loss: 0.0005(valid) | Acc: 69.2%(valid)
Epoch: 2 | time in 0 minutes, 37 seconds
Loss: 0.0507(train) | Acc: 71.3%(train)
Loss: 0.0005(valid) | Acc: 70.7%(valid)
Epoch: 3 | time in 0 minutes, 36 seconds
Loss: 0.0484(train) | Acc: 72.8%(train)
Loss: 0.0005(valid) | Acc: 71.4%(valid)
Epoch: 4 | time in 0 minutes, 36 seconds
Loss: 0.0474(train) | Acc: 73.4%(train)
Loss: 0.0004(valid) | Acc: 72.0%(valid)
Epoch: 5 | time in 0 minutes, 36 seconds
Loss: 0.0455(train) | Acc: 74.8%(train)
Loss: 0.0004(valid) | Acc: 72.5%(valid)
Epoch: 6 | time in 0 minutes, 36 seconds
Loss: 0.0451(train) | Acc: 74.9%(train)
Loss: 0.0004(valid) | Acc: 72.3%(valid)
Epoch: 7 | time in 0 minutes, 36 seconds
Loss: 0.0446(train) | Acc: 75.3%(train)
Loss: 0.0004(valid) | Acc: 72.0%(valid)
Epoch: 8 | time in 0 minutes, 36 seconds
Loss: 0.0437(train) | Acc: 75.9%(train)
Loss: 0.0004(valid) | Acc: 71.4%(valid)
Epoch: 9 | time in 0 minutes, 36 seconds
Loss: 0.0431(train) | Acc: 76.2%(train)
Loss: 0.0004(valid) | Acc: 72.7%(valid)
Epoch: 10 | time in 0 minutes, 36 seconds
Loss: 0.0426(train) | Acc: 76.6%(train)
Loss: 0.0004(valid) | Acc: 72.6%(valid)
第五步: 查看embedding层嵌入的词向量.
# 打印从模型的状态字典中获得的Embedding矩阵
print(model.state_dict()['embedding.weight'])
tensor([[ 0.4401, -0.4177, -0.4161, ..., 0.2497, -0.4657, -0.1861],
[-0.2574, -0.1952, 0.1443, ..., -0.4687, -0.0742, 0.2606],
[-0.1926, -0.1153, -0.0167, ..., -0.0954, 0.0134, -0.0632],
...,
[-0.0780, -0.2331, -0.3656, ..., -0.1899, 0.4083, 0.3002],
[-0.0696, 0.4396, -0.1350, ..., 0.1019, 0.2792, -0.4749],
[-0.2978, 0.1872, -0.1994, ..., 0.3435, 0.4729, -0.2608]])


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









