






Nosql 介绍
Nosql 一些分布式非关系型数据库的统称
非关系型数据库对比关系型数据库有什么区别?
对比关系型数据库而言:
1.NoSQL数据库会采用非关系的数据模型
2.弱化模式或表结构、弱化完整性约束、弱化甚至取消事务机制
3.可能无法全部支持,或不能完整的支持SQL语句
4.目的是实现强大的分布式部署能力——一般包括分区容错性、伸缩性和访问效率(可用性)等
NoSQL常见的存储模式?
键值数据库 redis
列族数据库 Hbase
文档数据库 mongoDB
图数据库 neo4j
mongoDB简介
MongoDB是一个开源、高性能、无模式的文档型数据库
特点:1操作简单和容易
2文档中设置任何字段的索引来实现更快的排序
3添加分片实现自动水平扩展和路由
4支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组
5允许存储大文件对象
6支持各种编程语言
应用场景:
游戏场景
社交场景
物流场景
直播场景
体系结构:
collection 集合 (相当于表)
document 文档 (相当于行)
mongoDB 数据库操作命令
查看数据库
show dbs
/
show databases
选择和创建数据库
use 数据库
查看当前数据库
db
数据库的删除
db.dropDatabase()
mongoDB集合操作
单个文档插入 .insertOne()
db.collection.insertOne({"K":"V","K1":"V1"})
批量文档插入 .insertMany()
db.collection.insertMany([{"K":"V","K1":"V1"},{}])
文档的基本查询 .find()
//查询comment集合的所有文档
db.comment.find({})
//查询过滤条件
//查询id = 10001 且 name = sss 的文档
db.comment.find({id:"10001",name:"sss"})
分页查询 .limit() .skip()
//top3
db.comment.find().limit(3)
//前N个不要
db.comment.find().skip(N)
排序查询 .sort()
//对userid降序排列,并对likenum进行升序排列
db.comment.find().sort({userid:-1,likenum:1})
比较查询 $gt $lt
db.collection.find({ "field" : { $gt: value }}) // 大于: field > value
db.collection.find({ "field" : { $lt: value }}) // 小于: field < value
db.collection.find({ "field" : { $gte: value }}) // 大于等于: field >= value
db.collection.find({ "field" : { $lte: value }}) // 小于等于: field <= value
db.collection.find({ "field" : { $ne: value }}) // 不等于: field != value
示例:查询评论点赞数量大于700的文档
db.comment.find({likenum:{$gt:700}})
包含查询 $in $nin
//包含使用$in操作符。 示例:查询评论的集合中userid字段包含1003或1004的文档
db.comment.find({userid:{$in:["1003","1004"]}})
//不包含使用$nin操作符。 示例:查询评论集合中userid字段不包含1003和1004的文档
db.comment.find({userid:{$nin:["1003","1004"]}})
条件连接查询 $and $or
示例:查询评论集合中likenum大于等于700 并且小于2000的文档:
db.comment.find({$and:[{likenum:{$gte:700}},{likenum:{$lt:2000}}]})
统计查询 .count()
//统计记录数
//条件统计
db.comment.count({k:v})
文档更新 update()
//修改_id为2的记录,浏览量为889:
db.comment.updateOne({_id:"2"},{$set:{likenum:NumberInt(889)}})
更新所有用户为 1003 的用户的昵称为 凯撒大帝:
db.comment.updateMany({userid:"1003"},{$set:{nickname:"凯撒大帝"}})
更换文档 replace
//更新_id为3的文档
db.comment.replaceOne({_id:"3"},{userid:"9999"})
删除文档 delete
//删除_id为3的文档
db.comment.deleteMany({_id:"3"})
游标
插入数据
for (var i=0;i<10000;i++){
db.items.insert({"name":i,"age":20+i})
}
// forEach()
var myCursor = db.items.find({$and:[{age:{$gt:500}},{age:{$lt:520}}]})
myCursor.forEach(printjson);
读取数据
var myCursor = db.items.find({$and:[{age:{$gt:500}},{age:{$lt:520}}]})
while(myCursor.hasNext()){
var text =myCursor.next();
printjson(text);
}
数据导入导出
导出为json格式文件:mongoexport -d <数据库名称> -c <collection名称> -o <json文件名称>
导出为csv格式文件:mongoexport -d <数据库名称> -c <collection名称> --type csv - f <key字段> - o <csv文件名称>
导入json格式文件数据:
mongoimport -d <数据库名称> -c <collection名称> --file <要导入的json文件名称>
导入csv格式文件数据:mongoimport -d <数据库名称> -c <collection名称> --type csv --headerline --file <csv文件名称>
–headerline :这个参数很重要,加上这个参数后创建完成后的内容会以 CSV 文件第一行的内容为字段名(导入json文件不需要这个参数)
数据备份恢复
使用mongodump命令来备份MongoDB数据。使用mongorestore命令来恢复MongoDB数据。
聚合
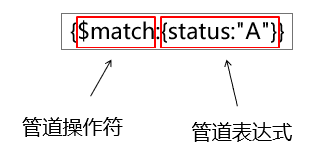
管道表达式
db.test.aggregate()
|
| mongodb | mysql |
|---|
| 管道操作符 | sql关键词 |
|---|---|
| $group | group by |
| $match | having |
| $project | select |
| $sort | order by |
| $limit | limit |
| $sum | sum / count |
| $lookup | join |
| 管道表达式操作符 | 简述 | |
| ************布尔操作符************ | ||
| $and | 逻辑与操作符,当他的表达式中所有值都是true的时候,才返回true。 用法:{ $and: [ <\expression1>, <\expression2>, ... ] }。 | |
| $or | 逻辑或操作符,当他的表达式中有值是true的时候,就会返回true。用法:{ $or: [ <\expression1>, <\expression2>, ... ] } | |
| $not | 取反操作符,返回表达式中取反后的布尔值。用法:{ $not: [ <\expression> ] } | |
| ************比较操作符************ | ||
| $cmp | 比较操作符,比较表达式中两个值的大小,如果第一个值小于第二个值则返回-1,相等返回0,大于返回1。用法{ $cmp: [ <\expression1>, <\expression2> ] } | |
| $eq | 比较表达式中两个是否相等,是则返回true,否则返回false。用法{ $eq: [ <\expression1>, <\expression2> ] } | |
| $gt | 比较表达式中两个是否相等,是则返回true,否则返回false。用法{ $eq: [ <\expression1>, <\expression2> ] } | |
| $gte | ||
| $lt | ||
| $lte | ||
| $ne | 比较表达式中两个是否相等,不过返回值与eq相反,是则返回false,否则返回true。用法`{ne: [ <\expression1>, <\expression2> ] } | |
| ************数学操作符************ | ||
| $abs | { $abs: } | |
| $add | 求和操作符,返回所有表达式相加起来的结果。用法:{ $add: [ <\expression1>, <\expression2>, ... ] } | |
| $ceil | 进一法取整操作符 用法:{ $ceil: <\number> } | |
| $divide | 求商操作符,返回表达式1除以表达式2的商。用法:{ $divide: [ <\expression1>, <\expression2> ] } | |
| $subtract | 求差操作符,返回表达式1减去表达式2的结果。用法:{ $subtract: [ <\expression1>, <\expression2> ] } | |
| $multiply | 求积操作符,操作如上 | |
| $mod | 求余操作符,操作如上 | |
| ************字符串操作符************ | ||
| $concat | 连接操作符 | |
| $split | 切割操作符 | |
| $toLower | 用于返回字符串的小写形式 | |
| $toUpper | 用于返回字符串的大写形式。 | |
| $substr | 用于返回子字符串,v3.4+版本不建议使用,应该使用substrBytes或substrCP,v3.4+版本使用的话,相当于substrBytes。用法:{ $substr: [ <\string>, <\start>, <\length> ] } | |
| $substrBytes | 用于根据UTF-8下的字节位置返回子字符串(起始位置为0),于v3.4新增。用法:{ $substrBytes: [ <\string expression>, <\byte index>, <\byte count> ] } | |
| $substrCP | 用于根据UTF-8下的Code Point位置返回子字符串(起始位置为0),于v3.4新增。用法:{ $substrCP: [ <\string expression>, <\code point index>, <\code point count> ] } | |
| ************日期操作符************ | ||
| $dayOfYear | 返回一年中的一天,值在1和366(闰年)之间。用法:{ $dayOfYear:<\expression> } | |
| $dayOfMonth | 返回一个月中的一天,值在1和31之间 | |
| $dayOfWeek | 返回一周中的一天,值在1(周日)和7(周六)之间 | |
| $year | 返回年份, | |
| $month | 返回月份,值在1和12之间 | |
| $week | 返回周 ,值在0和53之间。 | |
| $hour | 返回时 ,值在0和23之间。 | |
| $minute | 返回分 ,值在0和59之间。 | |
| $second | 返回秒,值在0和60之间(闰秒) | |
eg:
db.order.aggregate([
{
$project:{ trade_no:1, all_price:1 }
}
])
查找价钱在80到100之前的订单,并且只显示trade_no和all_price
db.order.aggregate([
{
$project:{ trade_no:1, all_price:1 }
},
{
$match:{$and:[{all_price:{$gt:80}},{all_price:{$lt:100}}]}
}
])
查找价钱大于90的订单,只显示trade_no和all_price,并且按照all_price排序,只取第一名
db.order.aggregate([
{$project:{ trade_no:1, all_price:1 }},
{$match:{"all_price":{$gte:90}}},
{$sort:{"all_price":-1}},
{$limit:1}
])
索引
查看执行计划
db.comment.find({userid:"1003"}).explain()
在comment集合userid字段上创建降序索引
db.comment.createIndex( { userid: -1 } )
//索引的默认名称是索引键和索引中每个键的方向(即1或-1)的连接,使用下划线作为分隔符。例如,在{ userid: -1 }上创建的索引名称为userid_-1。
您可以创建具有自定义名称的索引,比默认名称更易于阅读的索引。
db.comment.createIndex(
{ userid: 1, state: -1 } ,
{ name: "state for userid" }
)
可以通过getIndexes()或者getIndexSpecs()函数查看集合中的所有索引信息
语法格式:db.collection.getIndexes()
语法格式:db.collection.getIndexSpecs()
查看索引键
语法格式:db.collection.getIndexKeys()
删除索引
语法格式:db.collection.dropIndex(“索引名称”)
删除全部索引
db.comment.dropIndexes()
:
下列关于MongoDB数据库,描述错误的是?
MongoDB 字段值可以是数组及文档数组,但是不能包含其他文档
MongoDB分片集中,下列说法错误的是?
A MongoDB支持两种分片策略来实现分片集群中的分布数据,哈希分片和范围分片
B 每个shard(分片)包含被分片的数据集中的一个子集。每个分片可以被部署为副本集架构。
C 理想的分片键允许MongoDB在整个集群中均匀地分布所有文档
D chunksize越大,数据均衡时迁移速度更快,数据分布更均匀。数据分裂频繁,路由节点消耗更多资源。















 4998
4998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









