






conf文件
chrome_options.py
'''
options类或者是函数的形态,专门用于管理options相关设置。一定记得在末尾要使用return来返回。
'''
from selenium import webdriver
def options():
# 创建一个options对象,进行浏览器的设置项定义。什么 options = webdriver.ChromeOptions()浏览器就创建对应的options对象即可
options = webdriver.ChromeOptions()
# 页面加载策略
# options.page_load_strategy = 'normal'
# 想要添加设置项的时候,常用的两个添加设置方法
# options.add_experimental_option() # 添加试验性质的参数,意味着可能存在不稳定的情况,但是实际上没有发现有什么不稳定。
# options.add_argument() # 添加常规参数
# 窗体最大化
options.add_argument('start-maximized')
# 窗体的指定坐标启动:该方法只能针对未最大化窗体的浏览器进行设置。
# options.add_argument('window-position=300,600')
# 窗体的初始化尺寸定义
# options.add_argument('window-size=1000,1200')
# 自动化测试黄条警告去除
options.add_experimental_option('excludeSwitches', ['enable-automation', 'enable-logging'])
# options.add_experimental_option('disable-infobars') # 只有python27的版本才有效,现在看到可以直接忽略。
# 无头模式:浏览器不以界面形态来运行。但是实际上,该执行的相关操作依旧还是会正常执行。这种模式可以降低GPU和CPU资源的耗费。无头模式在特定的场景下可能会出现BUG
# options.add_argument('--headless')
# 账号密码保存弹窗的去除
prefs = {
'credentials_enable_service': False,
'profile.password_manager_enable': False
}
options.add_experimental_option('prefs', prefs)
# 加载用户本地缓存信息
'''
selenium默认启动的浏览器,是不会加载本地缓存信息的。也就意味着Selenium启动的浏览器是完全全新且独立的浏览器,不会与本地的数据进行任何的交互
1. 全新浏览器访问系统时会有验证码的风险。
2. 验证码本身是用于防止自动化脚本恶意访问的,所以Selenium不处理验证码
如果想要避免验证码的风险,其中一种手段就是加载本地缓存信息。
想要绕过登录,加载本地缓存是一个最直接的方法,但是前提是网站本身具备有保存登录状态的功能。
要通过Selenium调用本地缓存,一定要提前将浏览器全部关闭,再启动自动化脚本,否则会报错。
'''
# options.add_argument(r'--user-data-dir=C:\Users\15414\AppData\Local\Google\Chrome\User Data')
# 启动隐身模式
# options.add_argument('incognito')
# 去除控制台的多余信息:首选此方法
# options.add_experimental_option('excludeSwitches', ['enable-logging'])
# 进一步去除系统多余信息,去除多余日志的第二道保险
options.add_argument('--log_level=3')
options.add_argument('--disable-gpu')
options.add_argument('--ignore-certificate-errors')
# 对options设置好以后一定要记得用return返回。
return options
log_conf.ini
[loggers]
keys = root
[handlers]
keys = fileHandler,streamHandler
[formatters]
keys = simpleFormatter
[logger_root]
level = DEBUG
handlers = fileHandler,streamHandler
[handler_fileHandler]
class = FileHandler
level = DEBUG
formatter = simpleFormatter
args = ('log_conf.log','a','utf-8')
[handler_streamHandler]
class = StreamHandler
level = DEBUG
formatter = simpleFormatter
[formatter_simpleFormatter]
format = %(levelname)s %(asctime)s %(filename)s %(module)s %(funcName)s %(lineno)s : %(message)slogging_conf.py
'''
读取ini配置文件中的logging,实现日志的输出和记录
要读取配置文件,需要通过logging.config来实现
配置ini文件的相对绝对路径,就是根据工程路径来获取它的绝对路径。
基于pathLib库来实现文件路径的获取
'''
import logging.config
import pathlib
# 封装日志记录器的函数
def getLogger():
# 读取配置文件
# logging.config.fileConfig(path, encoding='utf-8')
# 获取当前文件所在的路径
file_path = pathlib.Path(__file__)
# 获取当前文件的上一级
dir = file_path.parents[0].resolve() # 返回路径对象
# 基于上一级获取到log_conf.ini文件
file = dir / 'log_conf.ini'
logging.config.fileConfig(file, encoding='utf-8')
# 获取记录器
logger = logging.getLogger()
return logger # 一定记得要return,不然无法获取logger对象,来实现日志的输出记录
# 获取记录器
# logger = getLogger()
# logger.debug('这是配置文件的debug')
# logger.info('这是配置文件的info')
# logger.error('这是配置文件的error')
# file_path = pathlib.Path(__file__)
# print(file_path)
# dir = file_path.parents[0].resolve() # 返回路径对象
# print(dir)
# print(type(dir))
# file = dir / 'log_conf.ini'
# print(file)
excel_driver文件
excel_driver.py
'''
Excel数据驱动关联关键字驱动实现自动化测试流程
'''
import openpyxl
from excel_driver.excel_style import pass_, failed
from web_keys.web import WebKeys
# log = getLogger()
# 定义数据初始化
success = 0
fail = 0
fail_list = []
# 参数解析函数
def argument(value):
# 参数解析处理,将str的xxx=xxx的格式转换为字典的形态,然后通过**的方式传入到对应的操作方法之中
da = dict()
if value: # 因为value可能为none,所以要提前判断一下
str_temp = value.split(';') # 可能参数有多个,基于;进行分割,所以提前分割好参数的数量
for temp in str_temp:
# temp: by=id value=kw txt=xxxxx
t = temp.split('=', 1) # 基于=进行1次分割操作
da[t[0]] = t[1] # 将分割后的t的两个元素,作为key和value,进行保存
# data["type_"] = "Chrome" # 对字典中的指定key进行value的赋值,于是data={"type_":"Chrome"}
return da
def run(log, file):
global success, fail
# 实现Excel文件的内容读取
excel = openpyxl.load_workbook(file)
# sheet = excel['Sheet1']
sheets = excel.sheetnames # 获取所有的sheet页的名字
log.info(f'****************开始执行{file}测试用例********************')
for name in sheets: # 基于不同sheet页的名字,进行不同sheet页内容的获取
sheet = excel[name]
log.info(f'进入到{name}的sheet页,进行测试操作')
# 用例内容的处理
for values in sheet.values:
# 只要第一个单元格是int类型,则输出
if type(values[0]) is int:
# print(values)
# 参数:每一个操作行为对应的参数内容,将所有的参数转为字典格式,以便于后续的**方式的传参
data = argument(values[2])
# 描述:用于当前执行步骤的日志信息
log.info("正在执行操作行为:" + values[3])
# 操作行为:每一行用例的最终执行行为
# 实例化浏览器对象
if values[1] == 'open_browser':
wk = WebKeys(log=log, **data) # 实例化wk对象
# 因为断言会有返回值,需要结合返回值来执行相关对应的操作,所以断言作为独有的一个判断机制。
elif 'assert' in values[1]:
status = getattr(wk, values[1])(expected=values[4], **data) # 只要是断言都会有返回值
if status:
# 单元格写入pass
pass_(sheet.cell(row=values[0] + 2, column=6))
success += 1
else:
# 单元格写入failed
failed(sheet.cell(row=values[0] + 2, column=6))
fail += 1
fail_list.append(f'失败用例为{file}文件中的{name}Sheet页')
# 因为有断言的写入,所以需要进行文件的保存
excel.save(file)
# 基于实例化浏览器对象进行的常规操作行为
else:
status = getattr(wk, values[1])(**data) # 基于反射机制,满足所有的操作行为
excel.close()
log.info('测试执行完毕,正在退出中。。。。。。')
# log.warning(f'''
# 用例执行总数:{success + fail}
# 成功用例为:{success}个,
# 失败用例为:{fail}个,失败用例集:{fail_list}
# ''')
# 数据的结果输出
def sum_info(log):
log.warning(f'''
用例执行总数:{success + fail}
成功用例为:{success}个,
失败用例为:{fail}个,失败用例集:{fail_list}
''')
excel_style.py
'''
单元格写入的样式封装
'''
from openpyxl.styles import PatternFill, Font
# PASS配置
def pass_(cell):
# 设置pass值.
cell.value = 'PASS'
# 定义单元格的颜色和样式:绿色底,字体加粗
cell.fill = PatternFill('solid', fgColor='AACF91') # 单元格填充绿色底
cell.font = Font(bold=True) # 加粗
# FAILED配置
def failed(cell):
# 设置failed值.
cell.value = 'FAILED'
# 定义单元格的颜色和样式:红色底,字体加粗
cell.fill = PatternFill('solid', fgColor='FF0000') # 单元格填充红色底
cell.font = Font(bold=True) # 加粗
test_data文件
web_keys文件
web.py
'''
关键字驱动类,属于逻辑代码类。
只是基本业务逻辑的封装,本身不参与到任何实际的测试行为之中,单独运行不会有任何的意义。只有在被调用了之后才会产生作用。
关键字驱动类的逻辑代码实现:
关键字驱动又叫做Selenium的二次封装。其实体现的就是面向对象编程思维逻辑。
Selenium本身具备有非常多的方法,来提供给到自动化测试。关键字驱动就是将Selenium中常用的操作行为进行提取。封装成各种对应的关键字。
从而实现在后续的实际测试过程中,通过调用中这些关键字,来解决实际的自动化测试需要。
常用的操作行为:
1. 访问url
2. 定位元素
3. 输入
4. 点击
。。。。。
关键字驱动类,常规而言都是基于操作行为来提取和封装,同时也可以基于业务流程来进行封装,也可以考虑做公共流程的关键字封装。
不同企业的测试需求不同,所以自动化测试框架在实现的时候也会有不同。一定不要认为一套固定的测试框架可以解决所有企业的需求。
关键字驱动类,一般来说,是不会单独进行使用的。在平时测试过程中,都是会结合到其他的模块一同使用。最最起码的是会关联到数据驱动。
本身就是一种基本的行为封装类。没有什么很特别的东西。也不会存在很难的所谓的难点知识。
1. 关联到数据驱动和测试用例来一同使用
2. 结合企业的实际需要,进行定制化框架研发。
所有的所谓高级的技术,其实就是多个基础知识叠加在一起,最终就变成了高级技术。真正的难,在于设计思维的培养。
代码一定没有十全十美的。也不可能一次性把所有的关键字都封装好。如果遇到实际业务需要特定的操作行为,我们再去封装到关键字之中即可。
'''
import traceback
from time import sleep
from selenium import webdriver
from conf.chrome_options import options
from conf.logging_config import getLogger
# log = getLogger()
# driver对象生成
def open_browser(type_):
if type_.capitalize() == 'Chrome':
driver = webdriver.Chrome(options=options())
else:
try:
driver = getattr(webdriver, type_.capitalize())()
except:
driver = webdriver.Chrome()
return driver
class WebKeys:
# 定义临时driver对象
# driver = webdriver.Chrome()
# 构造方法
def __init__(self, type_, log):
self.driver = open_browser(type_)
self.driver.implicitly_wait(5)
self.log = log
# 访问url
def open(self, url):
self.driver.get(url)
# 定位元素
def locator(self, by, value):
return self.driver.find_element(by, value)
# 输入
def input(self, by, value, txt):
# self.driver.find_element().send_keys()
el = self.locator(by, value)
el.clear()
el.send_keys(txt)
# 点击
def click(self, by, value):
self.locator(by, value).click()
# 关闭
def quit(self):
self.driver.quit()
# 强制等待
def wait(self, time_):
sleep(int(time_))
# 文本断言
def assert_in(self, expected, by, value):
try:
reality = self.locator(by, value).text
assert expected in reality, f'''
断言失败:
expected:{expected}
reality:{reality}
expected != reality
'''
return True
except:
self.log.error(traceback.format_exc())
return False
log_conf.log
ERROR 2023-10-15 21:36:12,065 main.py main <module> 29 : 这不是测试用例.txt文件不是测试用例,本次不执行
WARNING 2023-10-15 21:36:12,066 excel_driver.py excel_driver sum_info 83 :
用例执行总数:0
成功用例为:0个,
失败用例为:0个,失败用例集:[]
INFO 2023-10-15 21:36:12,070 excel_driver.py excel_driver run 37 : ****************开始执行./test_data/test_fecmall.xlsx测试用例********************
INFO 2023-10-15 21:36:12,071 excel_driver.py excel_driver run 40 : 进入到Sheet1的sheet页,进行测试操作
INFO 2023-10-15 21:36:12,071 excel_driver.py excel_driver run 49 : 正在执行操作行为:创建一个chrome浏览器
INFO 2023-10-15 21:36:12,074 excel_driver.py excel_driver run 37 : ****************开始执行./test_data/test_demo.xlsx测试用例********************
INFO 2023-10-15 21:36:12,074 excel_driver.py excel_driver run 40 : 进入到Sheet1的sheet页,进行测试操作
INFO 2023-10-15 21:36:12,075 excel_driver.py excel_driver run 49 : 正在执行操作行为:创建一个chrome浏览器
INFO 2023-10-15 21:36:13,268 excel_driver.py excel_driver run 49 : 正在执行操作行为:访问Fecmall的登录页
INFO 2023-10-15 21:36:13,318 excel_driver.py excel_driver run 49 : 正在执行操作行为:访问百度首页
INFO 2023-10-15 21:36:14,679 excel_driver.py excel_driver run 49 : 正在执行操作行为:输入账号:2375154305@qq.com
INFO 2023-10-15 21:36:14,742 excel_driver.py excel_driver run 49 : 正在执行操作行为:输入密码:hcc123456
INFO 2023-10-15 21:36:14,806 excel_driver.py excel_driver run 49 : 正在执行操作行为:点击登录按钮
INFO 2023-10-15 21:36:15,008 excel_driver.py excel_driver run 49 : 正在执行操作行为:断言登录是否成功
INFO 2023-10-15 21:36:15,029 excel_driver.py excel_driver run 49 : 正在执行操作行为:强制等待3秒
INFO 2023-10-15 21:36:15,156 excel_driver.py excel_driver run 49 : 正在执行操作行为:在百度搜索框中输入”黄财财教你Excel数据驱动“
INFO 2023-10-15 21:36:15,562 excel_driver.py excel_driver run 49 : 正在执行操作行为:点击百度一下按钮
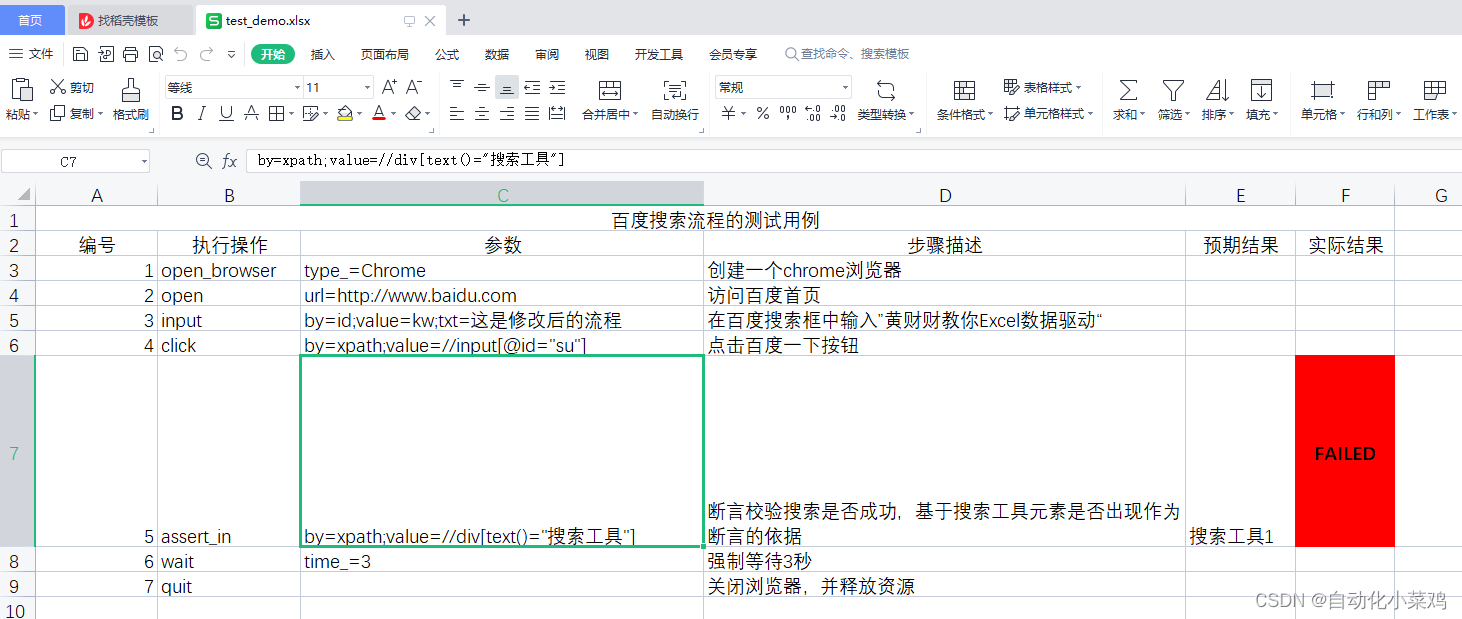
INFO 2023-10-15 21:36:15,701 excel_driver.py excel_driver run 49 : 正在执行操作行为:断言校验搜索是否成功,基于搜索工具元素是否出现作为断言的依据
INFO 2023-10-15 21:36:16,171 excel_driver.py excel_driver run 49 : 正在执行操作行为:强制等待3秒
INFO 2023-10-15 21:36:18,044 excel_driver.py excel_driver run 49 : 正在执行操作行为:关闭浏览器,并释放资源
INFO 2023-10-15 21:36:19,174 excel_driver.py excel_driver run 49 : 正在执行操作行为:关闭浏览器,并释放资源
INFO 2023-10-15 21:36:20,120 excel_driver.py excel_driver run 73 : 测试执行完毕,正在退出中。。。。。。
INFO 2023-10-15 21:36:21,287 excel_driver.py excel_driver run 40 : 进入到Sheet3的sheet页,进行测试操作
INFO 2023-10-15 21:36:21,287 excel_driver.py excel_driver run 49 : 正在执行操作行为:创建一个chrome浏览器
INFO 2023-10-15 21:36:26,538 excel_driver.py excel_driver run 49 : 正在执行操作行为:访问百度首页
INFO 2023-10-15 21:36:27,332 excel_driver.py excel_driver run 49 : 正在执行操作行为:在百度搜索框中输入”黄财财教你Excel数据驱动“
INFO 2023-10-15 21:36:27,490 excel_driver.py excel_driver run 49 : 正在执行操作行为:点击百度一下按钮
INFO 2023-10-15 21:36:27,598 excel_driver.py excel_driver run 49 : 正在执行操作行为:断言校验搜索是否成功,基于搜索工具元素是否出现作为断言的依据
ERROR 2023-10-15 21:36:28,032 web.py web assert_in 96 : Traceback (most recent call last):
File "D:\pyworkspace\web_ui_vip3\web_keys\web.py", line 88, in assert_in
assert expected in reality, f'''
AssertionError:
断言失败:
expected:搜索工具1
reality:搜索工具
expected != reality
INFO 2023-10-15 21:36:28,042 excel_driver.py excel_driver run 49 : 正在执行操作行为:强制等待3秒
INFO 2023-10-15 21:36:31,047 excel_driver.py excel_driver run 49 : 正在执行操作行为:关闭浏览器,并释放资源
INFO 2023-10-15 21:36:33,180 excel_driver.py excel_driver run 73 : 测试执行完毕,正在退出中。。。。。。















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









