









import numpy as np
import pandas as pd
import scipy.stats
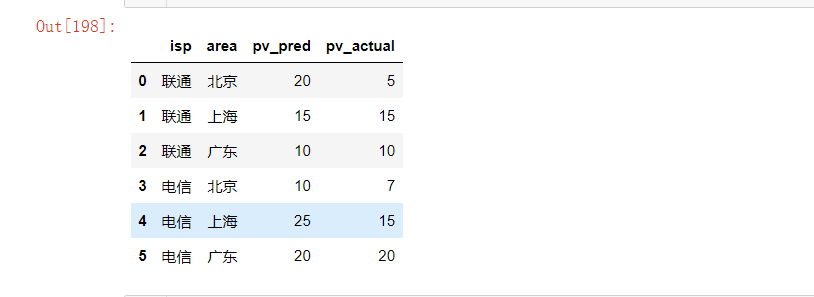
lists = [['联通', '北京', 20, 5],
['联通', '上海', 15, 15],
['联通', '广东', 10, 10],
['电信', '北京', 10, 7],
['电信', '上海', 25, 15],
['电信', '广东', 20, 20]]
df = pd.DataFrame(lists, columns=['isp', 'area', 'pv_pred', 'pv_actual'])
# 这里要分析当pv实际的数值跟预测的数值有差距的时候,到底是哪个维度的数据出了问题
def js_divergence(p, q):
p = np.array(p)
q = np.array(q)
m = (p + q) / 2
# 方法一:自定义函数
js1 = 0.5 * np.sum(p * np.log(p / m)) + 0.5 * np.sum(q * np.log(q / m))
# 方法二:调用scipy包
js2 = 0.5 * scipy.stats.entropy(p, m) + 0.5 * scipy.stats.entropy(q, m)
return round(float(js1), 6)
def root_cause_analysis(dframe):
'''
数据总共有两个维度,分别为isp和area,isp维度下共有两个值,分别为联通、电信,area维度下有三个值,分别为北京、上海、广东
'''
pv_sum = dframe.sum(numeric_only=True)
# 先计算isp维度的
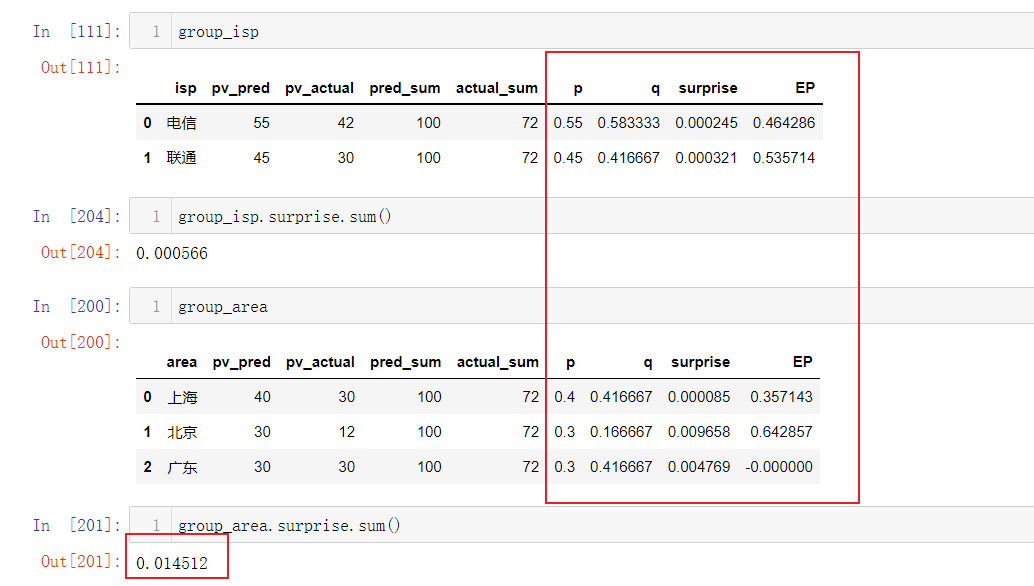
group_isp = dframe.groupby('isp').sum()
group_isp = group_isp.reset_index()
group_isp['pred_sum'] = pv_sum['pv_pred']
group_isp['actual_sum'] = pv_sum['pv_actual']
group_isp['p'] = group_isp['pv_pred'] / group_isp['pred_sum']
group_isp['q'] = group_isp['pv_actual'] / group_isp['actual_sum']
# 再计算area维度下的
group_area = dframe.groupby('area').sum()
group_area = group_area.reset_index()
group_area['pred_sum'] = pv_sum['pv_pred']
group_area['actual_sum'] = pv_sum['pv_actual']
group_area['p'] = group_area['pv_pred'] / group_area['pred_sum']
group_area['q'] = group_area['pv_actual'] / group_area['actual_sum']
# 第1步:分别计算两个维度下,不同维值的Surprise
group_isp['surprise'] = group_isp[['p', 'q']].apply(lambda x: js_divergence(x['p'], x['q']), axis=1)
group_area['surprise'] = group_area[['p', 'q']].apply(lambda x: js_divergence(x['p'], x['q']), axis=1)
# 第2步:计算每个维度下每个维值的EP值
group_isp['EP'] = group_isp[['pv_pred', 'pv_actual', 'pred_sum', 'actual_sum']].apply(
lambda x: (x['pv_actual'] - x['pv_pred']) / (x['actual_sum'] - x['pred_sum']), axis=1)
group_area['EP'] = group_area[['pv_pred', 'pv_actual', 'pred_sum', 'actual_sum']].apply(
lambda x: (x['pv_actual'] - x['pv_pred']) / (x['actual_sum'] - x['pred_sum']), axis=1)
# 第3步:根据Surprise值和EP值输出不同维度下维值的影响大小,从大到小
isp_surprise = group_isp['surprise'].sum()
area_surprise = group_area['surprise'].sum()
return ('isp', group_isp[['isp', 'EP']].sort_values(by=['EP'], ascending=False)) \
if isp_surprise > area_surprise \
else ('area', group_area[['area', 'EP']].sort_values(by=['EP'], ascending=False))
dim, ep = root_cause_analysis(df)
print('root cause dim is %s' % dim)
print('dim value and ep:')
print(ep)

CK:
https://github.com/penchy-zju/code_gist/blob/master/adtributor.py


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









