







CombineTextInputFormat切片机制
-
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小都会是一个单独切片,都会交给一个MapTask,如果有大量小文件,就会产生大量的MapTask,处理效率十分低下
-
应用场景
- CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样多个小文件可以交给一个MapTask处理
-
虚拟存储切片最大值设置
- CombineTextInputFormat.setMaxInputSplitSize(job,4194304) ##4M
-
虚拟存储过程
- 设置setMaxInputSize值为4M
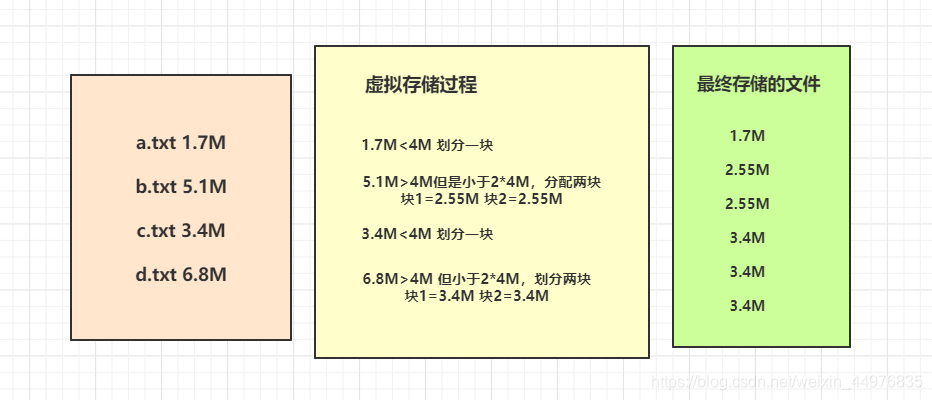
- 最终会形成三个切片,大小分别为:
(1.7+2.55)M (2.55+3.4)M (3.4+3.4)M
-
切片过程
- 判断虚拟存储的文件大小是否大于setMaxInputSize值,大于等于则单独形成一个切片
- 如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片
在Driver中设置CombineTextInputFormat
我们就模拟上方案例,设置虚拟存储切片最大值为4M
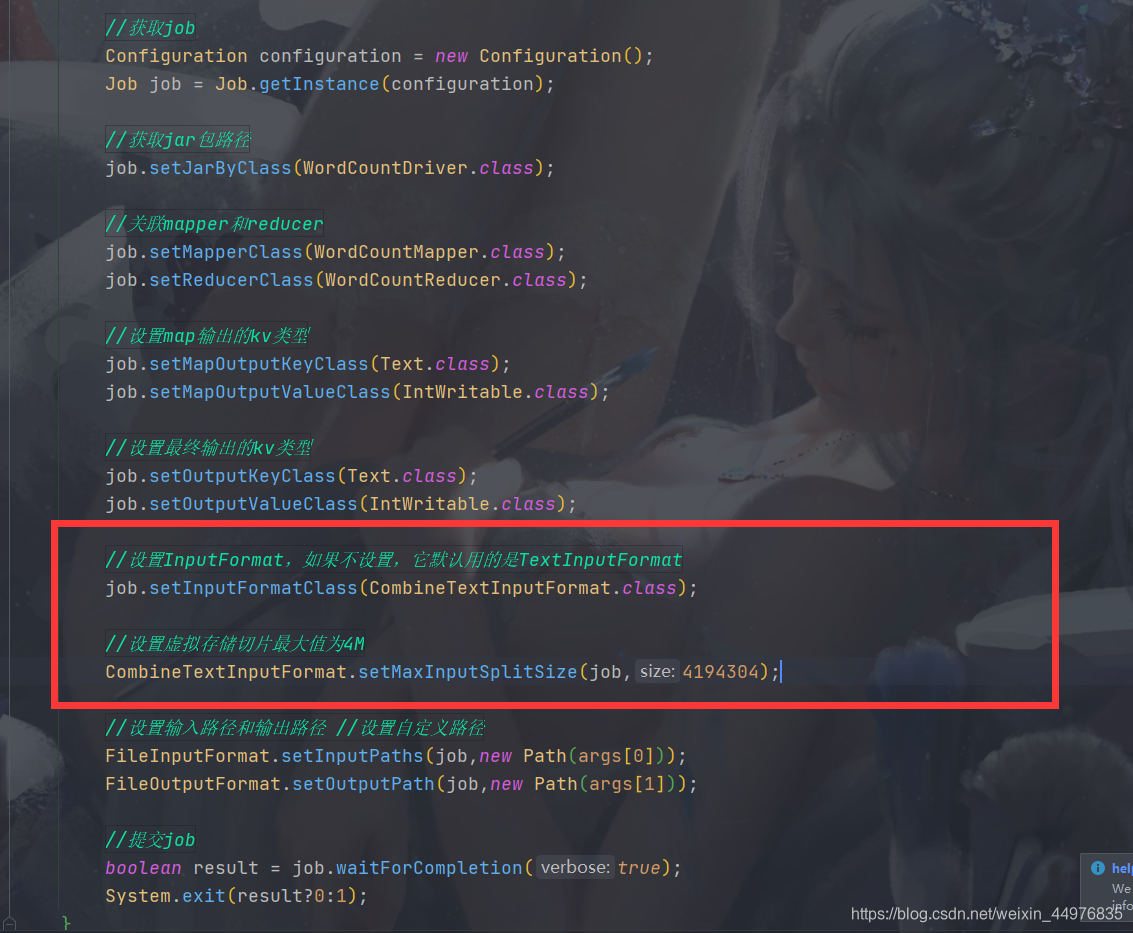
在Driver代码中添加InputFormat设置,如下图:
- Driver全部代码为:
public class WordCountDriver {
public static void main(String[] args) throws IOException,Exception {
//获取job
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//获取jar包路径
job.setJarByClass(WordCountDriver.class);
//关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置InputFormat,如果不设置,它默认用的是TextInputFormat
job.setInputFormatClass(CombineTextInputFormat.class);
//设置虚拟存储切片最大值为4M
CombineTextInputFormat.setMaxInputSplitSize(job,4194304);
//设置输入路径和输出路径 //设置自定义路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交job
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
下面是Mapper和Reducer代码:
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行
String line = value.toString();
//切割,获得单词
String[] words = line.split(" ");
//封装为Text和IntWritable类型
//循环写出
for (String word : words) {
outK.set(word);
context.write(outK,outV);
}
}
}
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
//获取传进来的值 累加
for (IntWritable value : values) {
sum+=value.get();
}
outV.set(sum);
//写出
context.write(key,outV);
}
}
设置完再执行上方的案例1.7M 5.1M 3.4M 6.8M就会发现切成了三片,如果不设置CombineTextInputFormat,那么采用默认的TextInputFormat,就会发现切成了四片。
我们在处理小文件的时候经常会使用到CombineTextInputFormat
















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











