






语法分析--自上而下分析
要进行语法分析,必须对语言的语法结构进行描述。
采用正规式和有限自动机可以描述和识别语言的单词符号;
用上下文无关文法来描述语法规则。
总体任务:
在词法分析识别出单词符号串的基础上,分析并判定程序的语法结构是否符合语法规则。
语法分析器地位:
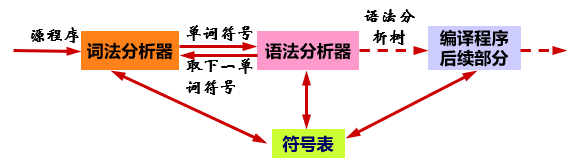
语法分析器的功能
输入
Token序列:词法分析产生的输出,是各个单词都正确的源程序,是一个有限序列
功能
按照语言的语法构成规则(文法产生式), 识别输入的符号串能否构成一个句子。
根据文法的产生式规则,从开始符号出发,看能否推导出这个输入串匹配的句子。这就需要建立与输入串匹配的语法分析树。
输出
分析树:如何表示?
错误处理信息:定位、继续编译
语法分析方法分类
自上而下分析法
从文法的开始符号出发,向下推导(使用最左推导) ,尽可能使用各种产生式,推导出与输入串匹配的句子(为输入串建立一棵语法树)。
递归下降分析、预测分析(LL)
存在问题:
① 分析过程本质是一个试探过程。一个非终结符有多个候选式会带来复杂的回溯问题。
② A → Aα , 会进入死循环。
③ 虚假匹配难消除
④ 效率低
⑤ 不能定位出错位置
所以,使用自顶向下分析,先改造文法,消除左递归和回溯。
自下而上分析法
从输入符号串开始,逐步进行归约(最右推导的逆过程),直至归约到文法的开始符号。
算符优先分析
LR分析(LR(0)、SLR(1)、LR(1)、LALR)
LL(1)分析法
左递归的消除
1.直接左递归消除

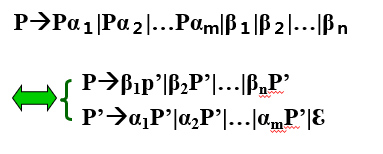
2. 消除左递归
一个文法消除左递归的条件:
不含以ε为右部的产生式
不含回路。
方法过程:
(1)排序:文法所有VN排序,按顺序执行。
(2)替换

(3)化简(2)所得的文法,去除那些从开始符号
出发永远无法到达的非终结符的产生规则.
例题:

解:
1)把文法G的所有非终结符按任意顺序排列,并编号
R、Q、S
2)按上面的排列顺序,对这些非终结符进行遍历
3)将当前处理的非终结符中的序号小于等于它的非终结符按规则3)进行替换(序号大于的按规则2)处理)
R:
R的右部中的非终结符有S;
S的下标大于R,可以暂时不处理;
所以此时R改写为:R → Sa | a
----------------------------------------------
Q:
Q的右部中的非终结符有R;
R的下标小于Q,将R的右部替换进来;
所以此时Q改写为:Q → Sab | ab | b;
S的下标大于Q,可以暂时不处理;
所以此时Q改写为:Q → Sab | ab | b;
-----------------------------------------
S:
S的右部中的非终结符有Q;
Q的下标小于S,将Q的右部替换进来;
所以此时S改写为:S → Sabc |abc | bc | c
S的下标等于S,可以暂时不处理;
所以此时S改写为:S → Sabc |abc | bc | c
4)消除i序号的非终结符的直接左递归(如果存在的话)
S → Sabc |abc | bc | c
∴ X = abc,Y = abc | bc | c
∴ 直接消除左递归的结果是:
S → abcS' | bcS' | cS'
S' → abcS' | ε
5)删除其中不可达的非终结符,这里就是Q、R了
∴ 最终消除左递归的结果是
S → abcS' | bcS' | cS'
S' → abcS' | ε
消除回溯,提取公共左因子
回溯产生的真正原因是:
某非终结符对应多个侯选式,它们左边部的第一个终结符相同(公共左因子),从而导致语法分析器选择了错误的侯选式。
消除回溯必须保证:
对文法的任何非终结符,当要它去匹配输入串时,能够根据它所面临的输入符号准确地指派它的一个候选去执行任务,并且此候选的工作结果应是确信无疑的。
若此候选获得成功匹配,那么,这种匹配决不会是虚假的;
若此候选无法完成匹配任务,则任何其它候选也肯定无法完成。
消除回溯方法:文法,提取公告左因子。
反复使用“提取公共左因子”的方法来改造文法,使得文法的每个非终结符号的各个候选式的首终结符两两不相交,来避免回溯。
FIRST(终结首符集)

消除回溯,就是:
采用提取左公共因子的方法使得非终结符的每个候选α的FIRST尽量不相交。
求法,例FIRST(X):
若X本身是终结符,则FIRST(X) = {X}
若X是非终结符,把产生式右边第一个是终结符的,全加到FISRT(X)中
若X→Y…是一个产生式且Y∈VN, 则把FIRST(Y)中的所有非ℇ元素都加到FIRST(X)中
若X→Y1Y2…Yk是一个产生式,Y1,…,Yi-1都是非终结符,而且对于任何j,1≤j≤i-1,FIRST(Yj)都含有ℇ(即Y1…Yi-1⇒ ℇ )*, 则 FIRST(Yj)中的所有非ℇ—元素都加到FIRST(X)中
特别是,若所有的FIRST(Yj)均含有ℇ ,j=1,2,…,k,则把ℇ加FIRST(X)中。
FOLLOW(后随符号集)

当非终结符A面临a时, 且a不属于A的任何侯选FIRST集,但A的某个候选FIRST中含ε,只有当a ∈ FOLLOW(A)时才能自动进行匹配。
FOLLOW集构造方法:
(1)对于文法的开始符号S, 置#于FOLLOW(S)中;
(2)若A→αBβ是一个产生式,
则把FIRST(β){ℇ}加至FOLLOW(B)中;
(3)若A→αB是一个产生式 ,
或A→αBβ是一个产生式而β⇒ℇ(即ℇ∈FIRST(β)),
则把FOLLOW(A)加至FOLLOW(B)中。
LL(1)文法
对于一个LL(1)文法,可以对其输入串进行有效的无回溯的自上而下分析。
判断条件:
(1)文法不含左递归(产生式右边的最左为非终结符)
(2)任一个非终结符的各个产生式的候选FIRST集两两不相交
(3)每个非终结符A,若它的某个候选FIRST集有ε,则
FIRST(A) ∩ FOLLOW(A) = 空集
预测分析表每个项目最多只有一个产生式,也可以判断是LL(1)文法。
LL(1)的含义:
第一个L是指从左至右扫描输入串;
第二个L是最左推导;
1代表分析时每一步只需向前查看一个符号。
LL(1)文法的自上而下分析
有效的无回溯的。

对非终结符A进行匹配,此时面临的输入符号为a:
(1)若a∈first( αi ),则指派αi去执行匹配任务;
(2)若a不属于任何一个候选首符集,则
若ℇ∈first( αi ),且a∈follow(A),则让A与ℇ自动匹配;
否则,a的出现是一种语法错误.
递归下降分析程序构造
实现思想
对应文法中每个非终结符编写一个递归过程,
每个过程的功能是识别由该非终结符推出的串,
当某非终结符的产生式有多个侯选时,
能够按LL(1)形式可唯一地确定选择某个侯选进行推导。
基本构造方法
基本构造方法:
对文法的每个非终结符号,
都根据其产生式的各个候选式的结构,
为其编写一个对应的子程序(或函数),
该子程序完成相应的非终结符对应的语法成分的识别和分析任务.
子程序功能:
对某个非终结符,用规则的右部符号串去匹配输入串。
分析过程是按文法规则自上而下
一级一级地调用有关子程序来完成
ADVANCE / SYM / ERROR
ADVANCE:把输入串指示器IP指向下一个输入符号,
即读入一个单字符号
SYM: IP当前所指的输入符号
ERROR,出错处理子程序
例:

PROCEDURE F;
IF SYM=‘i’ THEN ADVANCE
ELSE
IF SYM=‘(’ THEN
BEGIN
ADVANCE;
E;
IF SYM=‘)’ THEN ADVANCE
ELSE ERROR
END
ELSE ERROR;
主程序:
PROGRAM PARSER;
BEGIN
ADVANCE;
E;
IF SYM <>’#’ THEN
ERROR
END;
扩充的巴科斯范式:
在元符号 ” → “ 或 “ ::= ” 和 “ | ” 的基础上:
{α} 表示 a* (闭包运算)
{α}0n 表示: 可任意重复 0 到 n 次。 0跟n 可以随意改
[α] 表示: α | ε
语法图

优缺点
优点:
简单直观,易于构造.
缺点:
(1)对文法要求高,必须满足LL(1)文法;
(2)由于递归调用多,所以速度慢占用空间多.
预测分析程序
预测分析器模型:
 分析表——M[A,a]形式的矩阵表示
分析表——M[A,a]形式的矩阵表示
矩阵元素M[A,a]存放内容:一条A的产生式或出错标志;
矩阵元素—实际是相应的分析动作
(即所选用的推导的产生式)。
分析栈——用于存放分析过程中的文法符号。
总控程序
功能:
依据分析表和分析栈联合控制输入字符串的识别和分析,
它在任何时候都是根据当前分析栈的栈顶符号X和当前的
输入字符a来执行控制功能。
构造分析表的方法
(1)对每个A → α,执行第2步和第3步;
(2)对每个终结符 a ∈FIRST(α),把A → α加至M[A,a]中;
(3)若ε∈FIRST(α),则对任何b ∈FOLLOW(α),把 A → α加至M[A,b]中;
(4)把所有无定义的位置上标上“出错标志”。
预测分析过程
初始化:依次把’#’和文法开始符号压入分析栈,
栈顶符号X 将输入串第一个符号读入a;
(1)若X = a = ' # ' 分析成功,停止分析
(2)X = a ≠ ’ # “ ,X从栈顶弹出,a指向下一个输入符号
(3)若X是一个非终结符,查看分析表。
M [X , a] 存放着一个关于X的产生式,X弹出栈顶,产生式右部符号串按反序,压入栈(若右部是ε,只弹出,不压入)
贴个链接:
构造FIRST跟FOLLOW集
https://blog.csdn.net/qq_42583263/article/details/105813689?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162479844116780261985404%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=162479844116780261985404&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_v2~rank_v29-2-105813689.first_rank_v2_pc_rank_v29_1&utm_term=follo%E9%9B%86%E6%9E%84%E9%80%A0%E6%96%B9%E6%B3%95&spm=1018.2226.3001.4187















 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









