







1. Introduction
3 parts: Web Usage Mining, Web Content Mining, and Web Structure Mining (See 1.4).
The web is a global decentralized information space build on a set of technical standards for the identification, retrieval and representation of content.
Topology of the Web Today: The Classic Document Web, The Web of Data, and Web 2.0 Application
1.1 The Classic Document Web
1.1.1 Link Structure of the Web: In-Degree
The link distribution follows a power law.
- A small number of pages is target of many links
- A large number of pages is target of only a few or no links
1.1.2 Link Structure of the Web: Bow-Tie
Four mayor components
- Central Strongly Connected Component (SCC)(30%) - reach one another along directed links, like normal pages
- IN Group(20%) - can reach SCC but cannot be reached from it, like new pages or boring ones
- OUT Group(20%) - can be reached from SCC but cannot reach it, like company pages
- Tendrils(20%) - cannot reach SCC and cannot be reached by it
- Unconnected(10%)
A strongly connected component (SCC) in a directed graph is a subset of the nodes such that: every node in the subset has a path to every other node. The subset is not part of some larger set with the property that every node can reach every other.
1.2 The Web of Data
Markup Formats
- Microdata: format for annotating structured data within webpages
- RDFa
- HTML
Structured Data Formats - JSON-LD: embedding data into the HEAD of HTML pages
- Linked Data: Extend the Web with a single global data graph by using RDF to publish structured data on the Web and setting links between data items within different data sources (entities are identified with HTTP URIs)
Web Data Commons Project: extracts all Microformat, Microdata, RDFa, JSON-LD data from the Common Crawl. It analyzes and provides the extracted data for download
1.3 Web 2.0 Application
Web-based applications collect large amounts of data using proprietary schemata. It form separate data spaces that are only partly accessible from the Web via HTML interface and Web APIs.
APIs usually provide only limited access
- restricted to specific queries (canned queries)
- restricted by amount of queries / number of results
- (try to) prevent crawling
1.4 Web Mining
Non-trivial extraction of implicit, previously unknown and potentially useful information from Web content, Web structure, and Web usage data.
Sub-Fields:
1.4.1 Web Usage Mining
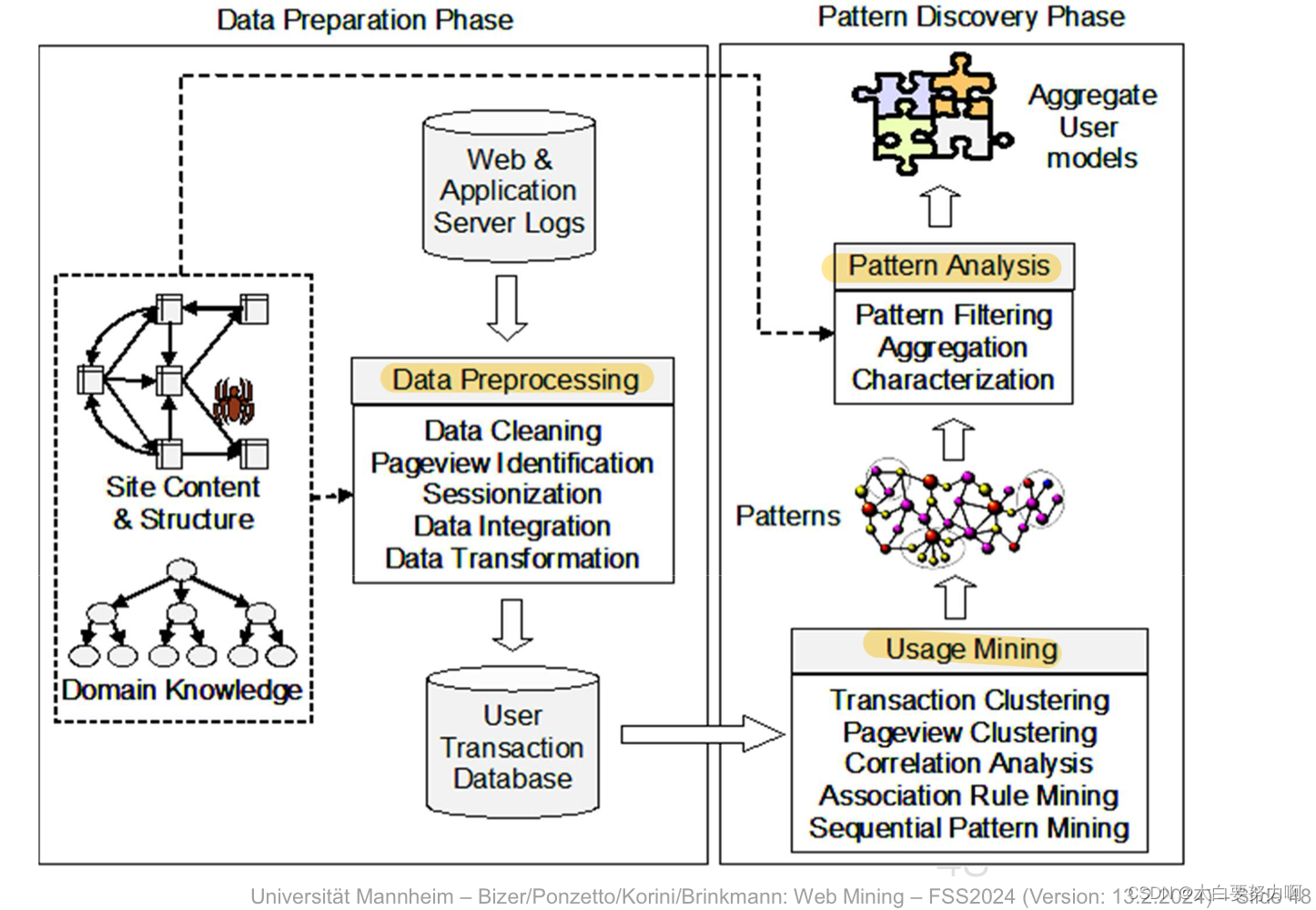
Discovery of patterns in click-streams and associated data collected or generated as a result of user interactions with one or more web sites or Web 2.0 applications.
1.4.2 Web Structure Mining
Discovery and interpretation of patterns in
- the hyperlink structure of the Web
- the social ties among actors that interact on the Web
focus on the structure, but can also be combined with content or usage mining technique
(1) Identification of Prominent Nodes
Centrality & Prestige
(2) Community Detection
A community is a set of actors between which interactions are (relatively) frequent.
Finding a community in a social network is to identify a set of nodes such that they interact with each other more frequently than with those nodes outside the group.
Methods: Components, K-Cores, Islands, …
Applications: Recommendation based on communities, visualization of huge networks
(3) Machine Learning with Graphs
Link Prediction & Node Classification
1.4.3 Web Conten tMining
Automatic extraction of useful information (facts, patterns) from Web content (text, images, multimedia).
Tasks:
(1)Content Clustering
Unsupervised Learning: Given a set of documents and a similarity measure among documents find clusters such that: documents in one cluster are more similar to one another; documents in separate clusters are less similar to one another
- Applications: Search result clustering, Topic discovery
- Techniques: Algorithms: K-Means, Hierarchical Clustering, S-BERT
- Similarity measures: Cosine, Jaccard, Text Embedding
(2)Content Classification
Previously unseen documents/images should be assigned a class as accurately as possible.
- Applications: News categorization, Product categorization, Spam detection
- Classification methods: Naive Bayes, Support Vector Machines, Deep Neural Nets, Transformers
(3)Sentiment Analysis
The basic task in sentiment analysis is classifying the polarity of a given text at the document, sentence, or feature/aspect level.
- Polarity Values: positive, neutral, negative; stars
- Applications
(a)Document-level: vote prediction from tweets
(b)Feature/Aspect-level: analysis of product reviews
(4)Hate Speech Detection / Political Scaling
Hate Speech Detection in Social Media Content
Political Scaling of Opinionated Texts
(5)Information Extraction
Goal: Automatic extraction of structured information from unstructured or semi-structured Web content.
1.4.4 Others
The Web Mining Process is equal to standard data mining process with difference that data is gathered from the Web.
Preprocessing and Transformation Methods:
- discretization and binarization
- feature subset selection / dimensionality reduction
- attribute transformation / text to term vector / embeddings
- aggregation, sampling
- integrate data from multiple sources
Actual Data Ming
Input: Preprocessed Data
Output: Model/Patterns
- Applydataminingmethod
- Evaluateresultingmodel/patterns
- Iterate
experiment with different hyperparameter settings
experiment with multiple alternative methods
improve preprocessing and feature generation
increase amount or quality of the training data
















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









