







1,项目概况
项目名称:
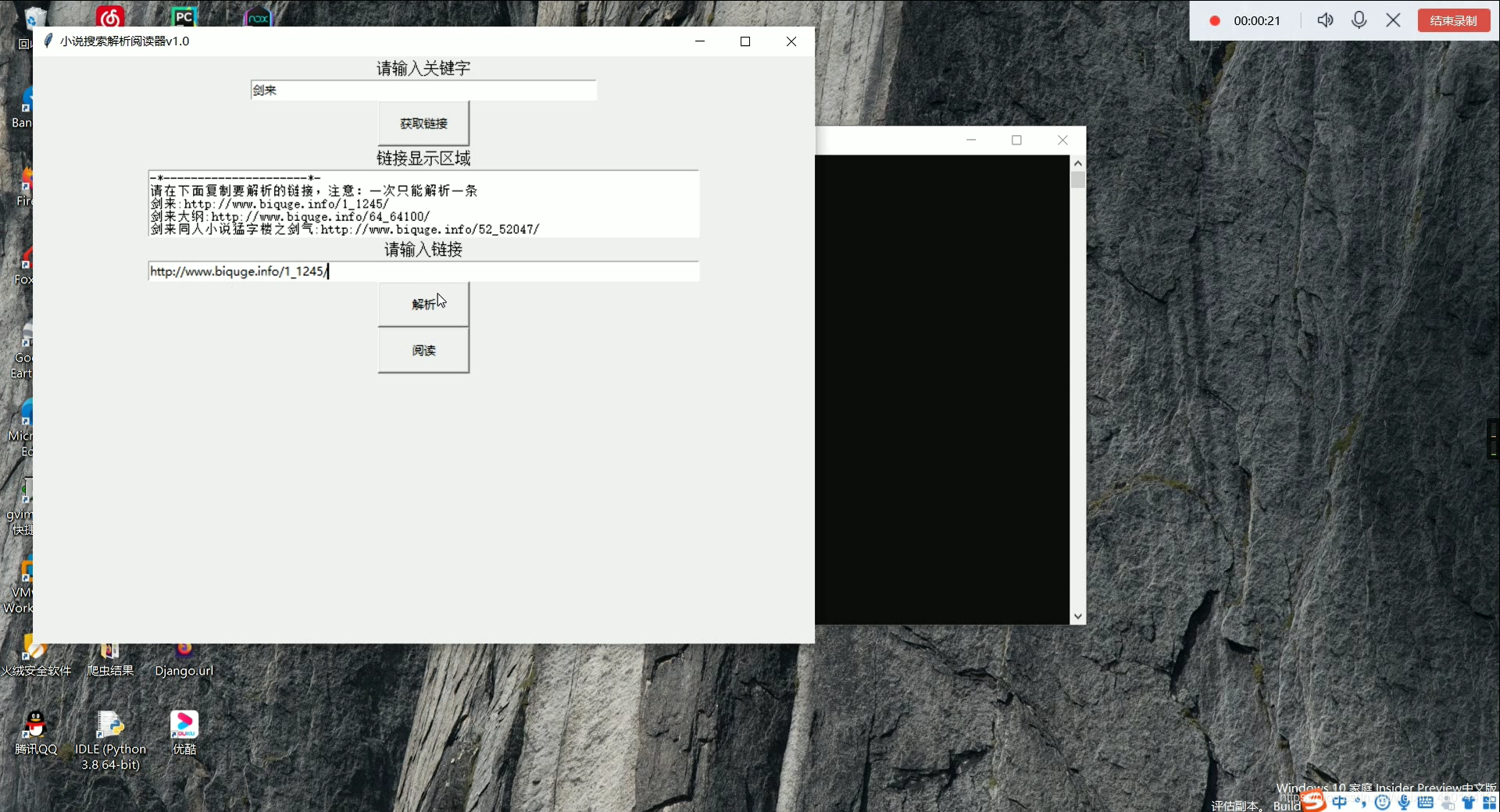
小说在线阅读器
项目需求:
1,根据关键字检索,实现从互联网获取所需链接。
2,对获取的链接进行解析,获取二级链接,获取的链接以文件的形式保存。
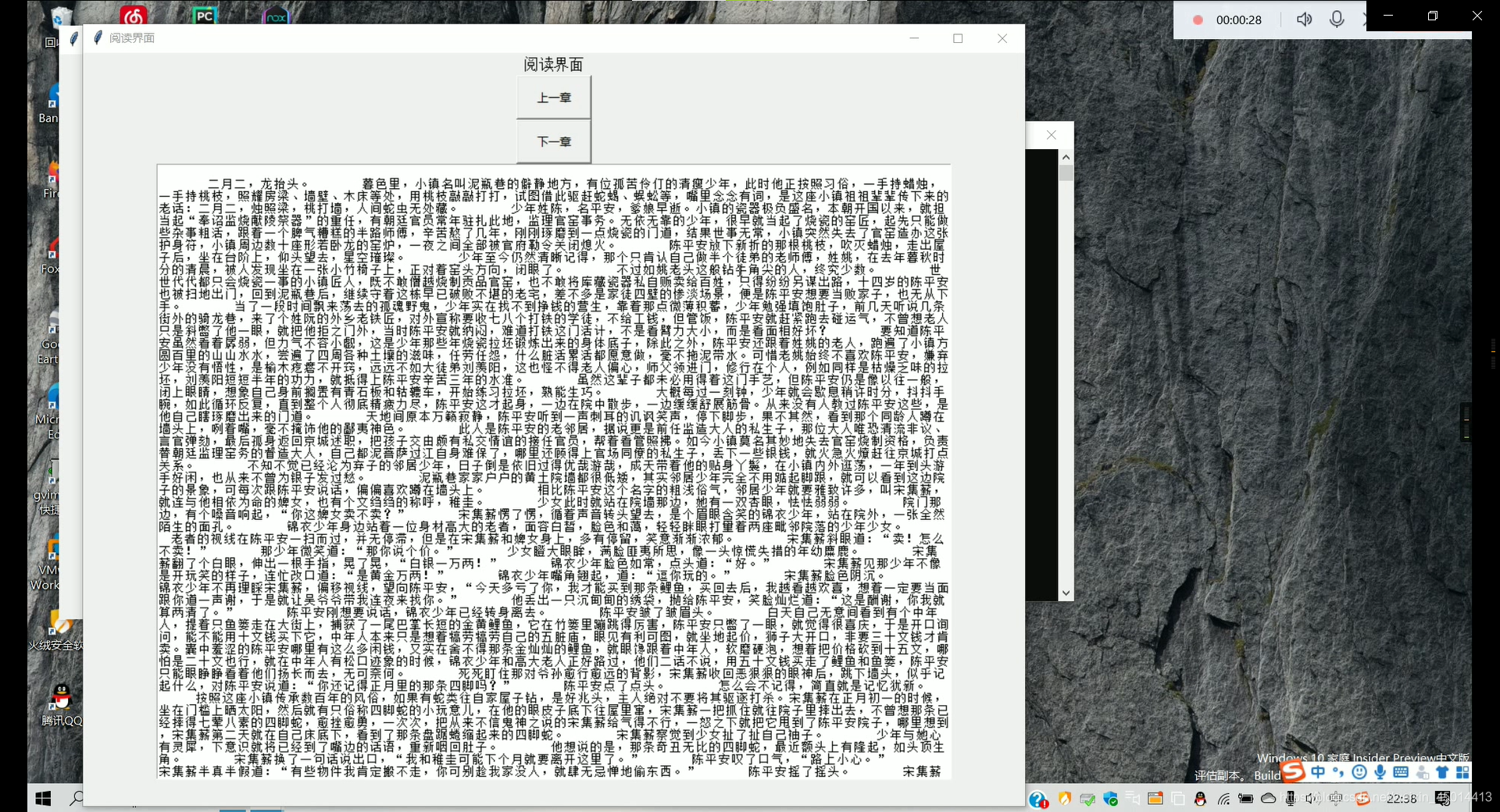
3,实现小说在线阅读。
所需技术:
Python基本爬虫,Python tkinter GUI设计
2,项目代码:
from fake_useragent import UserAgent
from bs4 import BeautifulSoup as Bp
import tkinter as tk
import tkinter.messagebox
import requests as req
import re
import os
#弹出窗口提示,说明使用须知。
tkl = tk.Tk()
tkl.title('验证窗口')
tkl.geometry('250x100')
tkinter.messagebox.showinfo(title='使用须知',message='''1,本软件需要连接网络才能够正常使用,使用本软件时请先连接网络!\n2,本软件仅供学习交流使用,请勿私自传播!\n3,鉴于本人水平有限,本软件若有不足之处,望见谅。\n4,在软件获取链接或者解析时请勿操作软件,否则可能会导致软件无响应!''')
tlable = tk.Label(tkl,text='阅读须知后请关闭此窗口!!!',font=('Arial',12))
tlable.pack()
tkl.mainloop()
#创建主窗口
app = tk.Tk()
app.title('小说搜索解析阅读器v1.0')
app.geometry('800x600')
lable = tk.Label(app,text='请输入关键字',font=('Arial',12))
lable.pack()
#定义搜索框
search_entry = tk.Entry(app,show=None,width=50)
search_entry.pack()
#定义功能函数
def getdata():
st.delete(1.0,tk.END)
url = 'http://www.biquge.info/modules/article/search.php'
#伪装头部
ua = UserAgent()
header = {'User-Agent':ua.random}
key = search_entry.get()
#爬取链接
try:
r = req.post(url,{'searchkey':key},headers=header)
except Exception as e:
tkinter.messagebox.showinfo(title='警告!',message='获取链接失败,请点击按钮重试!')
return
r.raise_for_status()
r.encoding = r.apparent_encoding
re_list = []
soup = Bp(r.text,'html.parser')
data = soup.find_all('a')
for item in data:
try:
if re.findall(key,item.text):
re_list.append(item.text + ':' + 'http://www.biquge.info' + item['href'])
except:
continue
if not re_list:
st.insert('insert','没有发现!')
dvar = '-*---------------------*-\n请在下面复制要解析的链接,注意:一次只能解析一条\n' + '\n'.join(re_list)
st.insert('insert',dvar)
return
#定义按钮实现功能
search_button = tk.Button(app,text='获取链接',width=12,
height=2,command=getdata)
search_button.pack()
lable1 = tk.Label(app,text='链接显示区域',font=('Arial',12))
lable1.pack()
st = tk.Text(app,width=80,height=5)
st.pack()
lable2 = tk.Label(app,text='请输入链接',font=('Arial',12))
lable2.pack()
read_entry = tk.Entry(app,show=None,width=80)
read_entry.pack()
#定以函数,用以实现相关按钮功能
def readlink():
url = read_entry.get()
try:
rd = req.get(url)
rd.raise_for_status()
rd.encoding = rd.apparent_encoding
soup = Bp(rd.text,'html.parser')
readdata = soup.find_all('a')
read_re_data = []
for item in readdata:
try:
if 'html' in item['href'] and 'http' not in item['href']:
read_re_data.append(url + item['href'])
else:
continue
except:
continue
with open('read.txt','w') as wfile:
wfile.write('\n'.join(read_re_data))
wfile.close()
except:
tkinter.messagebox.showinfo(title='警告', message='发生错误,请重试!')
return
read_button = tk.Button(app,text='解析',width=12,
height=2,command=readlink)
read_button.pack()
#readapp用于设置阅读窗口
def readapp():
readapp = tk.Tk()
readapp.title('阅读界面')
readapp.geometry('1000x800')
lable = tk.Label(readapp,text='阅读界面',font=('Arial',12))
lable.pack()
if not os.path.exists('read.txt'):
tkinter.messagebox.showinfo(title='错误',message='未找到文件!')
readapp.destroy()
return
with open('page.tmp','w') as file:
file.write('1')
file.close()
def downd():
if not os.path.exists('page.tmp'):
tkinter.messagebox.showinfo(title='错误', message='请重试!')
rf = open('page.tmp','r')
page = int(eval(rf.read()))
page += 1
rf.close()
page_str = str(page)
rfs = open('page.tmp','w')
rfs.write(page_str)
rfs.close()
readt.delete(1.0,tk.END)
rfile = open('read.txt', 'r')
url = rfile.readlines()
rfile.close()
readr = req.get(url[page][:-1:])
readr.raise_for_status()
readr.encoding = readr.apparent_encoding
soup = Bp(readr.text, 'html.parser')
data = soup.find_all('div', id='content')
for item in data:
readt.insert('insert', item.text)
return
def upd():
if not os.path.exists('page.tmp'):
tkinter.messagebox.showinfo(title='错误', message='请重试!')
rf = open('page.tmp', 'r')
page = int(eval(rf.read()))
rf.close()
if page <= 1:
tkinter.messagebox.showinfo(title='错误', message='没有上一章了!')
return
page -= 1
page_str = str(page)
rfs = open('page.tmp', 'w')
rfs.write(page_str)
rfs.close()
readt.delete(1.0, tk.END)
rfile = open('read.txt', 'r')
url = rfile.readlines()
rfile.close()
readr = req.get(url[page][:-1:])
readr.raise_for_status()
readr.encoding = readr.apparent_encoding
soup = Bp(readr.text, 'html.parser')
data = soup.find_all('div', id='content')
for item in data:
readt.insert('insert', item.text)
return
button1 = tk.Button(readapp,text='上一章',width=10,height=2,command=upd)
button1.pack()
button2 = tk.Button(readapp,text='下一章',width=10,height=2,command=downd)
button2.pack()
readt = tk.Text(readapp, width=120, height=50)
rfile = open('read.txt','r')
url = rfile.readlines()
rfile.close()
readr = req.get(url[1][:-1:])
readr.raise_for_status()
readr.encoding = readr.apparent_encoding
soup = Bp(readr.text,'html.parser')
data = soup.find_all('div',id='content')
for item in data:
readt.insert('insert',item.text)
readt.pack()
readapp.mainloop()
read_button1 = tk.Button(app,text='阅读',width=12,
height=2,command=readapp)
read_button1.pack()
app.mainloop()
3,项目效果:















 3119
3119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









