







定义
HBase 是一个开源的、基于列族存储、分布式的 NoSQL 数据库,它是 Apache Hadoop 生态系统中的重要组成部分,具有高可靠性、高性能、高扩展性等特点,主要用于海量结构化数据的读写操作。
HBase 的设计目标是面向海量数据的存储和访问,它采用分布式架构,将数据存储在多个节点上,并通过水平扩展的方式增加节点数量,从而实现数据的高可靠性和高性能。HBase 支持数据的自动分区、数据的压缩和缓存、数据的批量读写等特性,可以有效地处理大规模数据的存储和分析需求。
HBase 的数据模型是基于 Bigtable 的数据模型设计的,采用了列族存储的方式,数据按照行键有序存储,可以支持多维度的数据访问和查询。HBase 还提供了多种客户端接口,包括 Java API、REST API、Thrift API 等,可以方便地集成到不同的应用系统中,实现数据的高效读写和查询。
HBase 在互联网、金融、电信、物流等领域得到了广泛的应用和推广,是一款强大的分布式 NoSQL 数据库,为处理海量数据和实现实时分析提供了可靠、高效的解决方案。
行存储VS列存储
| 对比项 | 行存储 | 列存储 |
|---|---|---|
| 数据存储方式 | 按行存储,每行包含多列数据 | 按列存储,每列包含多行数据 |
| 访问方式 | 适合读取整行数据 | 适合读取部分列数据 |
| 数据写入 | 效率较低,需要将整行数据写入 | 效率较高,只需要写入部分列数据 |
| 数据更新 | 效率较高,只需要更新部分列数据 | 效率较低,需要更新整列数据 |
| 存储空间 | 占用存储空间较大 | 占用存储空间较小 |
| 数据压缩 | 压缩效果较好 | 压缩效果较差 |
| 数据分析 | 适合 OLTP 场景下的数据读写 | 适合 OLAP 场景下的数据分析 |
总的来说,行存储和列存储各有优缺点,需要根据实际的业务需求和数据特性进行选择和使用。如果需要频繁地读写整行数据,可以选择行存储;如果需要进行复杂的数据分析和查询,可以选择列存储。一些分布式数据库如 HBase 和 Cassandra 采用了列族存储的方式,既能兼顾整行读取的效率,又能支持部分列读取的需求,具有较好的数据存储和访问能力。
应用场景
HBase 是一款强大的分布式 NoSQL 数据库,具有高可靠性、高性能、高扩展性等特点,主要用于海量结构化数据的存储和分析。下面列举了一些 HBase 的应用场景:
日志管理
HBase 可以高效地存储海量的日志数据,并支持实时分析和查询。比如,可以将 Web 服务器或者应用服务器产生的日志数据存储到 HBase 中,通过 HBase 的 MapReduce 或者 Spark 等分布式计算框架进行实时分析和处理。
在线用户行为分析
HBase 可以高效地存储用户的行为数据,如用户的点击、浏览、购买等行为,支持对用户行为数据进行实时分析和查询。比如,可以将电商网站的用户行为数据存储到 HBase 中,通过 HBase 的数据查询和聚合功能,得出用户的喜好和购买偏好,从而实现个性化推荐和营销。
物联网数据管理
HBase 可以高效地存储传感器和设备产生的海量数据,并支持实时查询和分析。比如,可以将智能家居设备或者工业传感器产生的数据存储到 HBase 中,通过 HBase 的数据查询和聚合功能,得出设备的运行状态和工作效率,从而实现设备的远程监控和管理。
金融数据存储和分析
HBase 可以高效地存储金融行业的交易数据、用户数据等,支持实时查询和分析。比如,可以将银行的交易数据和用户数据存储到 HBase 中,通过 HBase 的数据查询和聚合功能,实现风险评估、反欺诈等业务需求。
总的来说,HBase 的应用场景非常广泛,可以用于各种海量结构化数据的存储和分析需求,尤其在互联网、金融、物联网等领域得到了广泛的应用和推广。
数据模型
| 概念 | 含义 | 关系 | 作用 | 相当于 Hive 中的什么 |
|---|---|---|---|---|
| Table | 表示一个 HBase 表 | 一个 Table 包含多个 HRegion | 包含多个 HRegion,对外提供数据读写服务 | 表 |
| HRegion | 表的分区,存储一部分的数据 | 一个 HRegion 包含多个 Store | 分散数据,提高读写性能 | 分区 |
| Store | HRegion 中的一个列族 | 一个 Store 包含多个 memStore 和多个 StoreFile | 存储一类数据 | 列族 |
| memStore | Store 中数据的内存缓存 | 一个 memStore 存储一段时间内的数据 | 临时存储新写入的数据 | 内存缓存 |
| StoreFile | Store 中数据的磁盘文件 | 一个 StoreFile 包含多个 HFile 块 | 持久化存储数据 | 磁盘文件 |
| HFile | 存储 HBase 数据的文件 | 一个 HFile 对应一个 StoreFile | 按照行键、列族、列限定符、时间戳的顺序存储数据 | 数据文件 |
| Column Family | HBase 表中的一部分,由多个列组成 | 一个表包含多个 Column Family | 存储一类数据 | 列族 |
| Column | Column Family 中的一个列 | 一个 Column 包含一个 Column Qualifier | 存储一项数据 | 列 |
| Column Qualifier | 列的限定符,用于表示列的具体含义 | 一个 Column Qualifier 对应一个数据值 | 区分不同的列 | 列限定符 |
| RowKey | HBase 表中数据的主键,由一个或多个列组成(行键) | 一个表中每行数据的 RowKey 唯一 | 唯一标识一行数据 | 主键 |
| Version Number | 数据的版本号 | 每个数据项可以有多个版本 | 记录数据的修改记录 | 版本号 |
| HLog | Write-Ahead Log,记录所有的写操作 | 每个 HRegion Server 包含多个 HLog | 防止数据丢失 | 日志文件 |
| HRegion Server | 管理 HRegion 的服务,负责读写请求的处理 | 一个 HRegion Server 可以管理多个 HRegion | 维护 HRegion,提供读写服务 | 服务节点 |
| BlockCache | 存储 HFile 中数据块的内存缓存 | 每个 HRegion Server 包含一个 BlockCache | 提高数据读取速度 | 内存缓存 |
这个表格的顺序按照数据在 HBase 中的存储顺序,从表到列限定符。这样可以更好地反映数据在 HBase 中的组织方式和层次结构,方便理解和记忆。 需要注意的是,HBase 的概念和 Hive 中的概念并不完全一致,只是在某些方面有相似之处。HBase 是一个面向列族的数据库,而 Hive 是一个基于 Hadoop 的数据仓库,两者的设计思路和应用场景有所不同。
读写流程
HBase 的读写流程主要包括以下几个步骤:
- 客户端向 HBase 的 ZooKeeper 发送请求,获取存储目标数据的 HRegion Server 地址。
- 客户端根据数据的行键信息,向对应的 HRegion Server 发送读取或写入请求。
- HRegion Server 根据请求类型,查询或修改对应的 HRegion 中的数据。
- 如果是读取请求,HRegion Server 将数据从 HDFS 或者 BlockCache 中读取出来,并返回给客户端。
- 如果是写入请求,HRegion Server 先将数据写入 memStore 中,然后根据 memStore 的大小或者时间限制,将其中的数据刷写到磁盘上的 HFile 文件中。
- 如果 memStore 中的数据已经刷写到 HFile 文件中,HRegion Server 会将 HLog 中相应的写操作标记为已完成。
- 如果需要将 HFile 文件合并或者删除过期的数据,HBase 会启动一个后台线程进行相应的处理。
总的来说,HBase 的读写流程比较简单,但是其中涉及到很多细节和优化,比如数据的缓存、数据的刷写、数据的合并等,都需要进行适当的配置和调优,才能发挥 HBase 的最佳性能。
读写性能
HBase 是一款基于 Hadoop 的分布式、可扩展、实时的 NoSQL 数据库,具有高可靠性、高可用性和高性能等特点。HBase 的数据读写性能在海量数据场景下表现出色,能够支持高并发、快速的数据访问和操作,特别适合于存储结构化或半结构化数据。
HBase 的读操作性能非常高,因为数据是按照行键1有序存储的,可以通过扫描行键范围或者行键前缀来快速定位数据2。此外,HBase 支持在读取数据时进行缓存,可以将数据缓存到内存中,从而减少磁盘 I/O 操作,提高读取数据的速度。
HBase 的写操作性能也很高,因为数据是按照列族和列限定符有序存储的,可以将相同列族和列限定符的数据存储在一起,减少磁盘寻址和存储操作,提高写入数据的速度。此外,HBase 还支持将新写入的数据先缓存到内存中,等到缓存满了或者达到一定时间后再一起刷写到磁盘中,从而减少磁盘 I/O 操作,提高写入数据的效率。
另外,HBase 还支持数据的自动分区和负载均衡,可以将数据均匀地分布到不同的节点上,避免了热点数据的问题,提高了系统的可扩展性和吞吐量。
总的来说,HBase 的数据读写性能非常高,可以满足大规模数据存储和处理的需求。但是,要想发挥 HBase 的最佳性能,需要根据实际场景进行调优和优化,比如合理设计表结构、优化 HBase 集群的配置、调整缓存策略等。
性能优化
优化 HBase 的性能需要从多个方面进行考虑和调整,下面列举了一些常见的优化方法:
表结构设计
合理的表结构设计可以大大提高 HBase 的性能,比如将相同的列族和列限定符的数据存储在一起,避免了磁盘寻址和存储操作,提高了写入数据的效率。另外,对于一些不需要经常查询的列,可以考虑将其存储为稀疏列,从而减少存储空间的占用。
行键设计
行键的设计直接影响了数据在表中的存储和访问方式,因此需要根据实际业务需求进行合理的设计和优化。比如,可以将行键设计为有意义的字符串或数字,控制行键的长度,避免过长导致数据存储位置分散,增加查询时间。另外,可以根据数据的访问模式和分布情况,合理划分行键的分区,提高数据的查询效率。
集群配置优化
HBase 集群的配置也是优化性能的重要环节,需要根据实际情况进行合理的配置和调优。比如,可以调整 HBase 的内存和 CPU 使用情况,增加 HBase 的缓存大小,优化 HDFS 的读写操作等。此外,还可以根据数据的访问模式和分布情况,对 HBase 集群进行水平或垂直扩展,提高系统的吞吐量和性能。
数据访问优化
数据访问是 HBase 性能优化的重要环节,需要根据实际的业务需求进行合理的优化。比如,可以采用批量读取的方式,减少网络传输的开销;利用 HBase 的过滤器机制,只查询需要的数据;合理设计 HBase 的缓存机制,将热点数据缓存到内存中,减少磁盘操作等。
数据清理和维护
HBase 中的数据清理和维护也是优化性能的重要环节,可以提高系统的稳定性和可靠性。比如,可以定期清理过期的数据、合并 HFile 文件、优化 HBase 的垃圾回收机制等。
总的来说,优化 HBase 的性能需要综合考虑多个方面,包括表结构设计、行键设计、集群配置优化、数据访问优化以及数据清理和维护等。需要根据实际的业务需求和数据分布情况,采用不同的优化方法和调优策略,才能发挥 HBase 的最佳性能。
请用一个表格说明HRegion,HRegion server,Region,Table,Store,memStor,StoreFile,Hlog,HStore,HFile,BlockCache,RowKey,Column Family,Column, Version Number的概念,关系,作用,相当于Hive中的什么
Compaction,Split
在HBase中,Compaction和Split是两个重要的维护操作,用于维护表的性能和可用性。
-
Compaction
在HBase中,数据是按照HFile(HBase的底层存储格式)的方式存储的。随着数据的写入和删除操作,HFile文件会变得越来越大,这会对读取性能和存储空间产生影响。为了解决这个问题,HBase提供了Compaction(合并)操作,将多个小的HFile文件合并成一个较大的HFile文件,以减少HFile文件的数量和尺寸,从而提高读取性能和节省存储空间。
在HBase中,Compaction是自动执行的,HBase会根据一定的策略(如时间、文件大小等)定期或触发式地执行Compaction操作。也可以通过手动触发Compaction操作来加速合并过程,例如使用
major_compactcompact命令来执行一次全局的Compaction操作。-
major_compact命令``major_compact`命令用于执行一次全局的Compaction操作,将所有的HFile文件进行合并。其语法如下:
major_compact 'table_name' ``` 其中,`table_name`是要执行Compaction操作的表的名称。 下面是一个示例,演示了如何使用`major_compact`命令在HBase Shell中执行一次全局的Compaction操作: ````bash hbase(main):001:0> major_compact 'my_table' ``` 在这个示例中,我们使用`major_compact`命令执行了名为`my_table`的表的一次全局Compaction操作。 -
compact命令``compact`命令用于执行一次指定表或指定Region的Compaction操作。其语法如下:
compact 'table_name', 'region_name' ``` 其中,`table_name`是要执行Compaction操作的表的名称,`region_name`是要执行Compaction操作的Region的名称。 下面是一个示例,演示了如何使用`compact`命令在HBase Shell中执行一次指定表的Compaction操作: ````bash hbase(main):001:0> compact 'my_table' ``` 在这个示例中,我们使用`compact`命令执行了名为`my_table`的表的一次Compaction操作。
-
-
Split
HBase表数据是分布式存储的,数据存储在一个或多个Region中。当一个Region的大小超过一定阈值时,HBase会自动执行Split(分裂)操作,将一个Region分裂成两个或多个更小的Region,以便提高查询和写入性能,同时也可以更好地利用分布式存储的优势。
在HBase中,Split操作是自动执行的,HBase会根据一定的策略(如Region大小、负载均衡等)定期或触发式地执行Split操作。也可以通过手动触发Split操作来加速分裂过程,例如使用
split命令来手动分裂一个Region为两个或多个更小的Region。split命令用于手动触发一个Region的分裂操作,其语法如下:split 'table_name', 'split_point'其中,
table_name是要分裂的表的名称,split_point是要分裂的Region的分裂点,即新Region的起始行键。分裂点可以是一个RowKey,也可以是一个完整的行键。
需要注意的是,Compaction和Split操作都会对HBase集群产生一定的负载,因此需要谨慎使用。如果不是必要的操作,建议使用默认的自动触发策略,避免手动触发操作对集群造成不必要的负担。如果遇到Compaction或Split操作频繁、耗时过长等问题,可以考虑调整HBase的配置参数或升级硬件来提高性能。
容错机制
HBase 的容错机制主要包括以下几个方面:
数据冗余
HBase 采用分布式架构,将数据存储在多个节点上,通过数据的冗余和备份,可以保证数据的可靠性和容错性。HBase 中的数据会自动分区和复制,将数据复制到不同的节点上,从而实现数据的高可用和容错。
ZooKeeper 协同
HBase 利用 ZooKeeper 进行集群的协同和管理,ZooKeeper 可以在集群节点之间共享数据和状态信息,从而实现集群的监控和管理。当 HBase 集群中的节点出现故障或者失效时,ZooKeeper 可以自动检测到节点的状态变化,并通知其他节点进行相应的调整和处理,从而保证整个集群的稳定性和可靠性。
数据恢复
HBase 采用 WAL(Write-Ahead-Log)的方式记录数据的更新操作,保证数据的一致性和持久性。当某个节点出现故障或者失效时,HBase 可以通过 WAL 日志进行数据恢复,将数据恢复到故障节点之前的状态,从而避免数据的丢失和损坏。
RegionServer 自动重启
HBase 的 RegionServer 是存储数据的主要节点,当某个 RegionServer 出现故障或者失效时,HBase 可以自动重启该节点,从而恢复数据的访问和操作能力。
总的来说,HBase 的容错机制是比较完善的,通过数据的冗余和备份、ZooKeeper 的协同和管理、数据恢复等多个方面来保证数据的可靠性和集群的稳定性。在实际应用中,还可以通过数据备份和灾备等措施来进一步提高 HBase 的容错性和鲁棒性。
数据备份
HBase 的数据备份可以通过多种方式实现,下面介绍几种常用的备份方法:
HBase Export
HBase Export 是 HBase 自带的备份工具,在备份数据时可以将数据导出为 Hadoop 文件系统(HDFS)上的文件,或者直接导出到本地文件系统。HBase Export 可以指定备份的表名、时间范围、目标文件路径等参数,支持增量备份和全量备份两种方式。HBase Export 适合于周期性备份或者恢复单个表的数据。
Hadoop DistCP3
Hadoop DistCP 是 Hadoop 自带的分布式数据复制工具,可以将 HDFS 上的数据复制到其他 HDFS 集群或者本地文件系统。因为 HBase 的数据实际上也存储在 HDFS 上,因此可以使用 Hadoop DistCP 实现 HBase 数据的备份和恢复。Hadoop DistCP 支持增量备份和全量备份两种方式,可以根据实际需求进行选择。
第三方备份工具
除了 HBase 自带的备份工具之外,还有一些第三方备份工具可以用于备份 HBase 数据。比如,Apache Phoenix 提供的 Phoenix Backup 工具,可以将 HBase 数据备份到本地文件系统或者远程存储系统;HBase Backup 提供了类似于 MySQL 的备份和恢复功能,支持增量备份和全量备份等操作。
总的来说,HBase 的数据备份可以通过多种方式实现,可以根据实际需求和数据规模选择合适的备份工具和备份策略。在进行备份时,需要考虑数据的一致性和可靠性,避免数据丢失和损坏。同时,还需要进行备份数据的测试和恢复,确保备份数据的可用性和有效性。
备份数据时如何确保数据的一致性和可靠性?
在备份数据时,确保数据的一致性和可靠性是非常重要的,下面介绍一些方法来保证数据备份的一致性和可靠性:
停止写入
在进行全量备份时,可以先停止写入数据,等备份完成后再恢复写入。这样可以确保备份数据的一致性和完整性,避免备份过程中数据的丢失和损坏。
增量备份
增量备份是指只备份更新的数据,可以减少备份数据的量,缩短备份时间。在进行增量备份时,需要记录上一次备份的时间戳或者版本号,只备份更新的数据。增量备份可以频繁进行,以保证备份数据的及时性和可靠性。
多副本备份
在进行备份时,可以将备份数据保存到多个节点上,增加数据的冗余和备份。多副本备份可以提高备份数据的可靠性和容错性,避免数据的丢失和损坏。
数据检验
在备份数据完成后,需要对备份数据进行检验,确保备份数据的完整性和正确性。可以使用校验和或者哈希值等方法对备份数据进行检验,比对备份数据和源数据的校验和或者哈希值,以确保备份数据的一致性和可靠性。
定期测试
在备份数据完成后,需要进行备份数据的测试和恢复,以确保备份数据的可用性和有效性。可以定期测试备份数据的恢复过程,以验证备份数据的正确性和完整性。
总的来说,数据备份是非常重要的,需要采取多种方法来确保备份数据的一致性和可靠性。在备份数据时,需要根据实际情况选择合适的备份策略和备份工具,同时需要进行备份数据的检验和测试,以确保备份数据的有效性和可用性。
特殊的表
hbase:meta 表
hbase:meta 表是 HBase 中比较特殊的表之一,它存储了 HBase 集群中所有表的元数据信息。在 HBase 中,表被分成多个 Region,每个 Region 存储一部分数据。hbase:meta 表中存储了所有 Region 的元数据信息,包括表名、Region 名称、Region 范围、存储该 Region 的 RegionServer 等信息。当客户端要查询或者操作某个表中的数据时,会先从 hbase:meta 表中查询对应的 Region 的位置和存储该 Region 的 RegionServer,然后再到对应的 RegionServer 上进行数据的读写操作。
hbase:namespace 表
hbase:namespace 表是 HBase 中另外一个比较特殊的表,它存储了 HBase 集群中所有命名空间(Namespace)的信息。在 HBase 中,命名空间是一种逻辑上的分组方式,用于将表分组管理。一个命名空间下可以包含多个表,不同命名空间的表之间相互独立。hbase:namespace 表中存储了所有命名空间的信息,包括命名空间名称、命名空间 ID、创建时间等信息。当客户端要查询或者操作某个表时,需要先根据表名获取对应的命名空间,然后再到对应的 RegionServer 上进行数据的读写操作。
总的来说,是 HBase 中比较特殊的表,
hbase:root 表
也称为 root 表。这个表存储了整个 HBase 集群的元数据信息,包括 HBase 集群的版本信息、hbase:meta 表的位置信息等。
与 hbase:meta 表不同的是,hbase:root 表只有一个 Region,该 Region 存储在 HBase 集群中第一个启动的 RegionServer 上。当客户端要查询或者操作某个表时,会先从 hbase:root 表中获取 hbase:meta 表的位置信息,然后再到对应的 RegionServer 上进行数据的读写操作。
需要注意的是,hbase:root 表中存储的信息不应该被直接修改,否则可能会导致 HBase 集群的不可用。如果需要修改 HBase 集群的元数据信息,应该使用 HBase 提供的 API 或者工具进行操作,确保修改的正确性和安全性。
总的来说,hbase:root 表是 HBase 中比较特殊的表之一,存储了整个 HBase 集群的元数据信息,hbase:meta 表和 hbase:namespace 表分别存储了集群中所有表的元数据信息和命名空间的信息,对于 HBase 集群的正常运行和管理起到了重要的作用。
HBase Shell
create / list / describe
create 'table_name', 'column_family'
# table_name是你想创建的表的名称,column_family是表中列族的名称。你可以在表中定义多个列族。
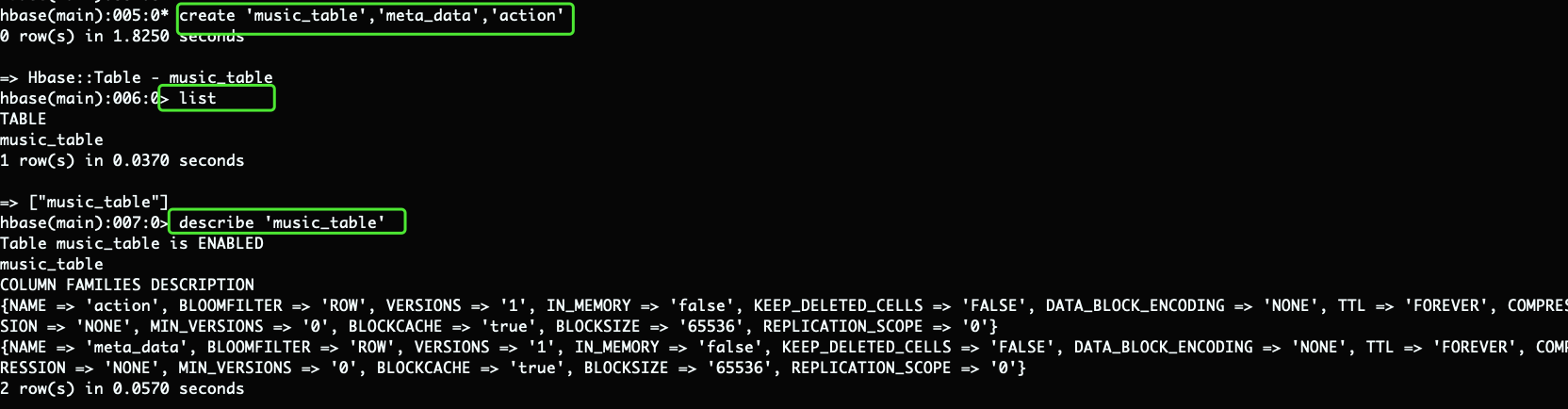
list命令用于列出所有已经存在的表。在HBase shell中执行list命令,会列出所有已经存在的HBase表。需要注意的是,list命令只能在HBase shell中使用,不能在HBase客户端API中使用。如果要在代码中列出所有表,可以使用HBase Admin类中的listTables()方法。
describe命令用于获取表的元数据信息,包括表名、列族信息等。在HBase shell中执行describe命令,会输出有关指定表的元数据信息。需要注意的是,describe命令只能在HBase shell中使用,不能在HBase客户端API中使用。如果要在代码中获取表的元数据信息,可以使用HBase Admin类中的getTableDescriptor()方法
describe输出结果:
表的状态
表的状态指示表当前是否启用。在输出结果中,状态以ENABLED或DISABLED的形式显示。
Table music_table is ENABLED
表的名称
表的名称是指要获取元数据的表的名称。在输出结果中,表的名称以表名的形式显示。
music_table
COLUMN FAMILIES DESCRIPTION 列族的描述信息
| 键 | 值的含义 |
|---|---|
| NAME | 列族的名称 |
| BLOOMFILTER | Bloom过滤器类型 |
| VERSIONS | 列族中保存的版本数 |
| IN_MEMORY | 是否将列族保存在内存中 |
| KEEP_DELETED_CELLS | 是否保留已删除的单元格 |
| DATA_BLOCK_ENCODING | 数据块编码方式 |
| TTL | 单元格的生存时间 |
| COMPRESSION | 数据压缩类型 |
| MIN_VERSIONS | 最小版本数 |
| BLOCKCACHE | 是否缓存数据块 |
| BLOCKSIZE | 数据块的大小 |
| REPLICATION_SCOPE | 复制范围 |
需要注意的是,这只是一个常见的列族属性列表,并不是所有可能的属性。在实际使用中,可能会遇到其他属性,需要查阅当前版本的HBase文档以了解更多信息。
列族
在HBase中,列族(Column Family)是一组相关的列的集合,通常在逻辑上是一起使用的。在表中创建列族时,需要为列族指定一个名称,所有属于该列族的列都将使用该名称作为前缀。例如,如果创建一个名为my_table的表,并创建了一个名为info的列族,那么该列族中的所有列都将以info:作为前缀。
列族在HBase中有多种用途,例如:
数据组织:将相关的数据组织在一起,使得查询和检索更加高效。
数据压缩:可以对列族中的所有列进行统一的数据压缩,以节省存储空间。
数据过期:可以为列族设置TTL(生存时间),以自动删除列族中的旧数据,从而节省存储空间。
alter / disable / enable
– 凡是要修改表的结构hbase规定,必须先禁用表->修改表->启用表 直接修改会报错
– 删除表中的列簇:alter ‘music_table’,{NAME=>‘action’,METHOD=>‘delete’}
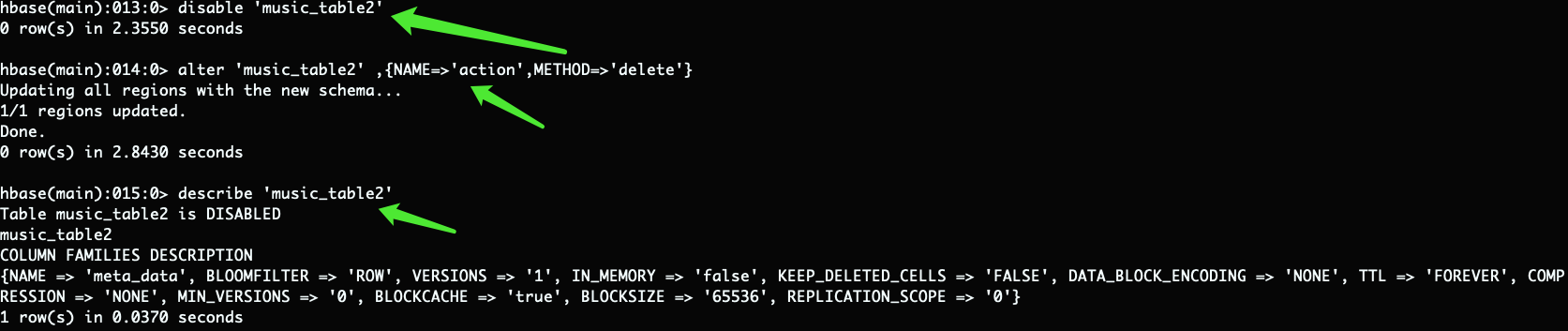
禁用表:disable 'music_table‘
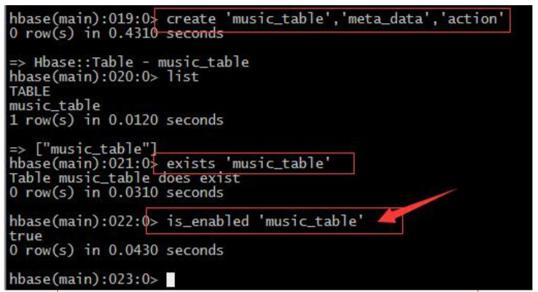
判断表是否enable或者disable
drop/delete/truncat
在HBase中,可以使用delete命令、drop命令和truncate命令来删除表或删除表中的数据。
-
delete命令用于删除指定行的数据,其语法如下:delete 'table_name', 'row_key', 'column_family:column', 'timestamp' # 其中,`table_name`是要删除数据的表的名称,`row_key`是要删除的数据的行键,`column_family`和`column`是要删除的数据的列族和列,`timestamp`是要删除的数据的时间戳。如果不指定时间戳,则删除最新版本的数据。 #下面是一个示例,演示了如何使用`delete`命令删除表中的一行数据: ````bash hbase(main):001:0> delete 'my_table', 'row_key', 'column_family:column' ``` #在这个示例中,我们使用`delete`命令删除了名为`my_table`的表中行键为`row_key`、列族为`column_family`、列为`column`的数据。 -
drop命令用于删除指定的表,其语法如下:drop 'table_name' #其中,`table_name`是要删除的表的名称。 #下面是一个示例,演示了如何使用`drop`命令删除表: ````bash hbase(main):001:0> drop 'my_table' ``` #在这个示例中,我们使用`drop`命令删除了名为`my_table`的表。 -
truncate命令用于删除指定表中的所有数据,其语法如下:truncate 'table_name' ``` # 其中,`table_name`是要删除数据的表的名称。 # 下面是一个示例,演示了如何使用`truncate`命令删除表中的所有数据: ````bash hbase(main):001:0> truncate 'my_table' ``` # 在这个示例中,我们使用`truncate`命令删除了名为`my_table`的表中的所有数据。
需要注意的是,删除数据和删除表都是不可逆的操作,因此在使用这些命令时需要谨慎操作,以免误删数据或表。在删除表之前,应该先备份数据,以便在需要恢复数据时可以使用备份数据。
插入和修改
– 对于hbase来说insert update其实没有什么区别,都是插入原理
– 在hbase中没有数据类型概念,都是“字符类型”,至于含义在程序中体现
– 每插入一条记录都会自动建立一个时间戳,由系统自动生成。也可手动“强行指定”
其语法如下:
put 'table_name', 'row_key', 'column_family:column', 'value'
其中,table_name是表的名称,row_key是要插入或修改的数据的行键,column_family和column是要插入或修改的数据的列族和列,value是要插入或修改的数据的值。

需要注意的是,当插入的行键和已有的行键冲突时,会将已有的数据覆盖成新插入的数据。如果要修改已有的数据,也是通过put命令实现的。如果要在HBase表中插入或修改大量的数据,也可以使用批量操作,可以通过HBase Shell中的batch命令实现。
查找
在HBase Shell中,可以使用get命令或scan命令实现查找数据的操作。
get命令用于从指定的表中获取一行数据,其语法如下:
get 'table_name', 'row_key'
其中,table_name是表的名称,row_key是要获取的行的行键。
如果要查找表中的多行数据,可以使用scan命令。scan命令用于从指定的表中扫描多行数据,其语法如下:
scan 'table_name'
其中,table_name是表的名称。
需要注意的是,scan命令可能返回大量的数据,因此需要谨慎使用,以免对HBase集群造成过大的负担。如果要获取特定范围内的数据,可以使用scan命令的参数进行限制,例如:
scan 'my_table', {STARTROW=>'row_key_start', ENDROW=>'row_key_end'}
这个命令将扫描名为my_table的表中行键从row_key_start到row_key_end之间的所有数据。


当需要进行复杂的数据查找时,过滤器的使用
可以结合使用过滤器(Filter)和scan命令来实现。在HBase Shell中,可以使用scan命令的FILTER选项来指定过滤器,从而对扫描的结果进行过滤。
以下是一个示例,演示了如何使用HBase Shell结合过滤器和scan命令进行数据查找:
假设我们有一个名为my_table的表,其中包含两个列族:info和data,我们要查找行键以user_开头的、列族为info、列为name的所有单元格的数据。
首先,我们可以使用scan命令来扫描my_table表中的所有行,然后使用SingleColumnValueFilter过滤器来过滤符合条件的单元格。SingleColumnValueFilter过滤器用于根据单元格的值来过滤数据,可以指定过滤条件的列族、列、比较运算符和值等信息。
下面是一个示例,演示了如何使用HBase Shell结合过滤器和scan命令进行数据查找:
hbase(main):001:0> scan 'my_table', {FILTER => "SingleColumnValueFilter('info', 'name', =, 'substring:user_')"}
在这个命令中,我们使用scan命令扫描my_table表中的所有行,并使用SingleColumnValueFilter过滤器来过滤符合条件的单元格。过滤器的参数指定了要过滤的列族为info,要过滤的列为name,比较运算符为等于号=,值为substring:user_,表示要查找列值中包含user_子串的单元格。
需要注意的是,过滤器语法中的单引号和双引号都是必须的,而且不同的过滤器语法可能略有不同,具体的语法使用方法可以参考HBase官方文档。
除了SingleColumnValueFilter过滤器,HBase还提供了多种其他类型的过滤器,例如PrefixFilter、ColumnPrefixFilter、RowFilter等等,可以根据具体的需求选择合适的过滤器来实现数据查找操作。
count
在HBase中,可以使用count命令来统计表中的行数或指定范围内的行数。
count命令用于统计指定表或指定范围内的行数,其语法如下:
count 'table_name', { INTERVAL => interval_num, CACHE => cache_num }
其中,table_name是要统计的表的名称,interval_num是统计间隔的行数,cache_num是缓存的行数,用于提高统计效率。
下面是一个示例,演示了如何使用count命令统计名为my_table的表中的行数:
hbase(main):001:0> count 'my_table'
在这个示例中,我们使用count命令统计了名为my_table的表中的行数。
如果要统计指定范围内的行数,可以在命令中指定起始行和结束行,例如:
count 'my_table', {STARTROW => 'start_row_key', ENDROW => 'end_row_key'}
这个命令将统计名为my_table的表中行键从start_row_key到end_row_key之间的所有行数。
需要注意的是,使用count命令统计行数可能会较慢,特别是对于大表而言。如果需要快速获取行数,可以考虑使用其他方法,例如在应用中进行缓存或使用HBase的Coprocessor扩展功能。
集成HIVE
HBase可以通过HBase Storage Handler来与Hive集成,从而实现在Hive中查询和操作HBase表的功能。HBase Storage Handler是一个Hive扩展,通过Hive的外部表机制,将HBase表映射为Hive表,从而可以在Hive中对HBase表进行操作。
要将HBase和Hive集成,需要完成以下步骤:
-
首先,确保HBase和Hive已经安装和配置好,并且可以正常工作。
-
下载和安装HBase Storage Handler。HBase Storage Handler可以从Apache官网下载,下载链接为:https://hive.apache.org/downloads.html。下载完成后,将jar包放置在Hive的
auxiliary目录中。 -
在Hive中创建外部表以映射HBase表。例如,可以使用类似以下的语句创建一个外部表:
CREATE EXTERNAL TABLE hbase_table(key string, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:col1") TBLPROPERTIES ("hbase.table.name" = "my_hbase_table"); ``` 在这个示例中,我们创建了一个名为`hbase_table`的外部表,将HBase表`my_hbase_table`映射为Hive表。通过`STORED BY`指定使用HBase Storage Handler来管理表的数据存储,通过`SERDEPROPERTIES`指定HBase表中每列与Hive表中每列的映射关系。 -
使用Hive进行查询和操作。创建好外部表后,就可以像操作普通Hive表一样查询和操作HBase表了,例如:
SELECT * FROM hbase_table WHERE key = 'row_key'; ``` 在这个示例中,我们使用Hive查询名为`hbase_table`的外部表中`key`列为`row_key`的数据。
需要注意的是,HBase Storage Handler并不支持所有HBase功能,例如HBase的过滤器、计数器等功能。在使用HBase Storage Handler时,需要注意其支持的功能和限制。
在 HBase 中,行键(Row Key)是一个字节数组,用于唯一标识表中的每一行数据,类似于关系型数据库中的主键。行键是 HBase 中的重要概念,它决定了数据在表中的存储位置和访问方式。在 HBase 中,数据是按照行键有序存储的,因此行键的设计很重要,可以直接影响到数据的读取性能和存储效率。通常情况下,行键是一个有意义的字符串或数字,可以根据具体的业务需求进行设计。比如,对于一个存储用户信息的表,行键可以是用户的唯一标识,比如手机号码、邮箱地址等。对于一个存储订单信息的表,行键可以是订单号等唯一标识。行键的长度没有限制,但是过长的行键会影响 HBase 的性能。因为在 HBase 中,数据是按照行键有序存储的,如果行键过长,会导致数据的存储位置分散,增加数据的访问成本和查询时间。因此,建议行键的长度控制在几十个字节以内。另外,行键还可以被划分为不同的分区,每个分区存储一部分的数据,这样可以提高数据的读取性能和查询效率。在 HBase 中,分区是通过对行键进行哈希计算得到的,因此行键的设计也会直接影响分区的质量和数量。总的来说,行键在 HBase 中扮演着非常重要的角色,它不仅是数据的唯一标识符,还直接影响了数据在表中的存储和访问方式,因此需要根据实际业务需求进行合理的设计和优化。 ↩︎
行键范围定位数据
scan 'table_name', {STARTROW => 'user2', ENDROW => 'user3'}上述代码中,‘table_name’ 表示表名,STARTROW 和 ENDROW 分别表示起始行键和结束行键,scan 命令会扫描 Row Key 在该范围内的所有数据,并返回查询结果。行键前缀定位数据scan 'table_name', {FILTER => "PrefixFilter('user3')"}上述代码中,‘table_name’ 表示表名,PrefixFilter 过滤器会匹配 Row Key 以该前缀开头的所有数据,并返回查询结果。通过 HBase shell 实现行键范围和行键前缀查询数据非常方便,可以快速地定位到需要的数据。 ↩︎DistCP 是 Distributed Copy 的缩写,是 Hadoop 中自带的分布式数据复制工具。DistCP 可以将 Hadoop 文件系统(HDFS)上的数据复制到其他 HDFS 集群或者本地文件系统,支持增量复制和全量复制两种方式。DistCP 可以在分布式环境下高效地复制数据,支持跨集群的数据复制和迁移,是 Hadoop 中非常重要的数据管理和迁移工具之一。 ↩︎















 2225
2225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









