







python爬虫——用Scrapy框架爬取阳光电影的所有电影
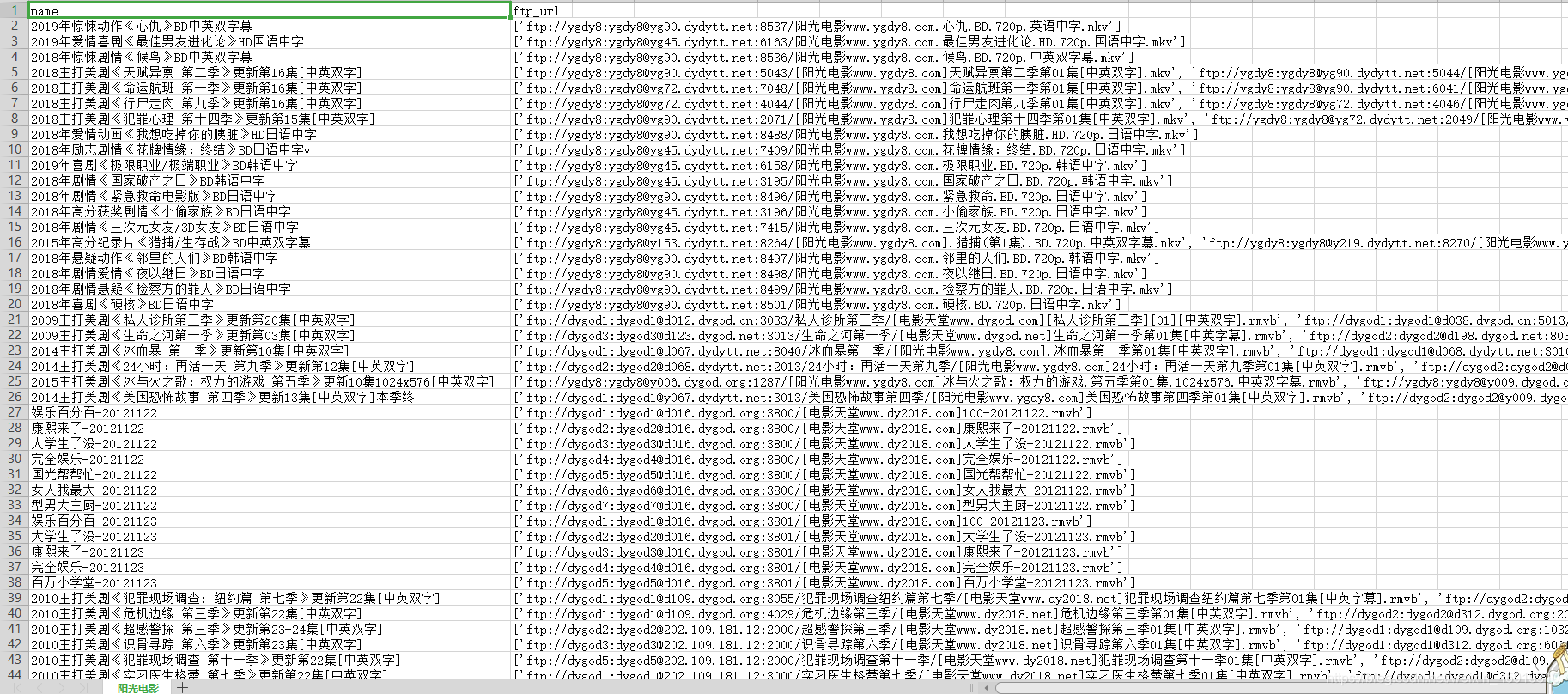
1.附上效果图

2.阳光电影网址http://www.ygdy8.net/index.html
3.先写好开始的网址
name = 'ygdy8'
allowed_domains = ['ygdy8.net']
start_urls = ['http://www.ygdy8.net/index.html']
4.再写采集规则
#采集规则的集合
rules = (
#具体实现的采集规则
#采集导航页中电影的部分 allow是选择出所有带有index的网址 allow是正则表达式 只要写你想提取的链接的一部分就可以了
#deny是去掉游戏那一栏
Rule(LinkExtractor(allow=r'index.html', deny='game')),
# follow=True 下一次提取网页中如果包含我们需要提取的信息是否还要继续提取
Rule(LinkExtractor(allow=r'list_\d+_\d+.html'),follow=True),
#allow里面提取详情页信息
#callback回调函数将相应交给谁处理
Rule(LinkExtractor(allow=r'/\d+/\d+.html'),callback='parse_item',follow=False),
)
第一个规则是从导航栏那里匹配,匹配除了游戏的其他导航栏
#采集导航页中电影的部分 allow是选择出所有带有index的网址 allow是正则表达式 只要写你想提取的链接的一部分就可以了
#deny是去掉游戏那一栏
Rule(LinkExtractor(allow=r'index.html', deny='game')),

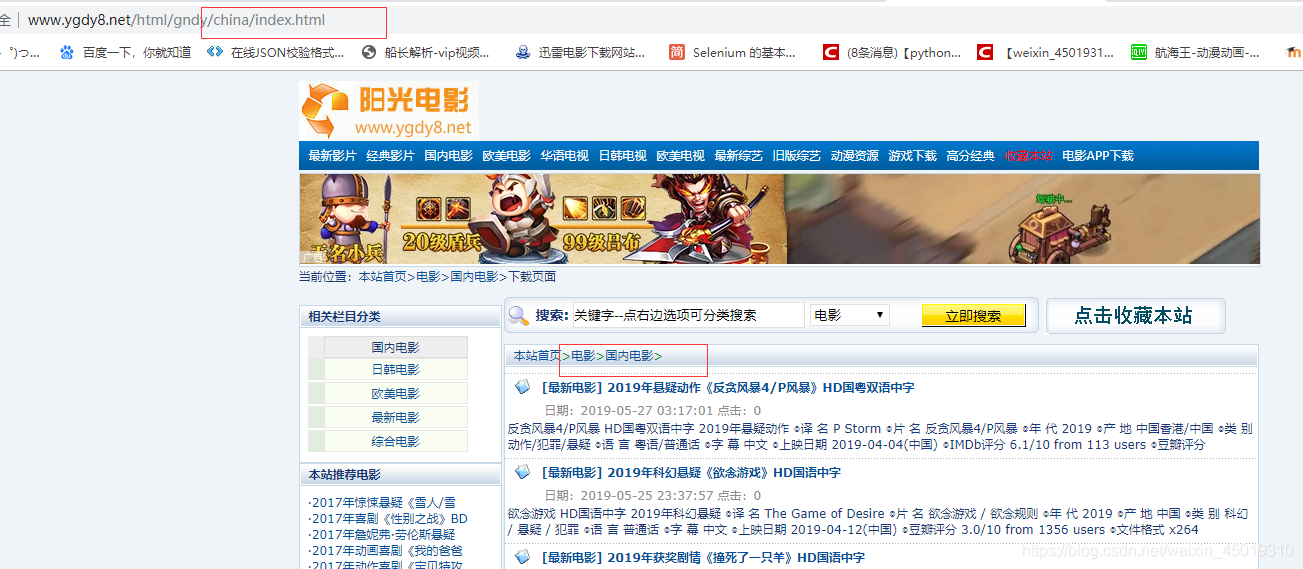
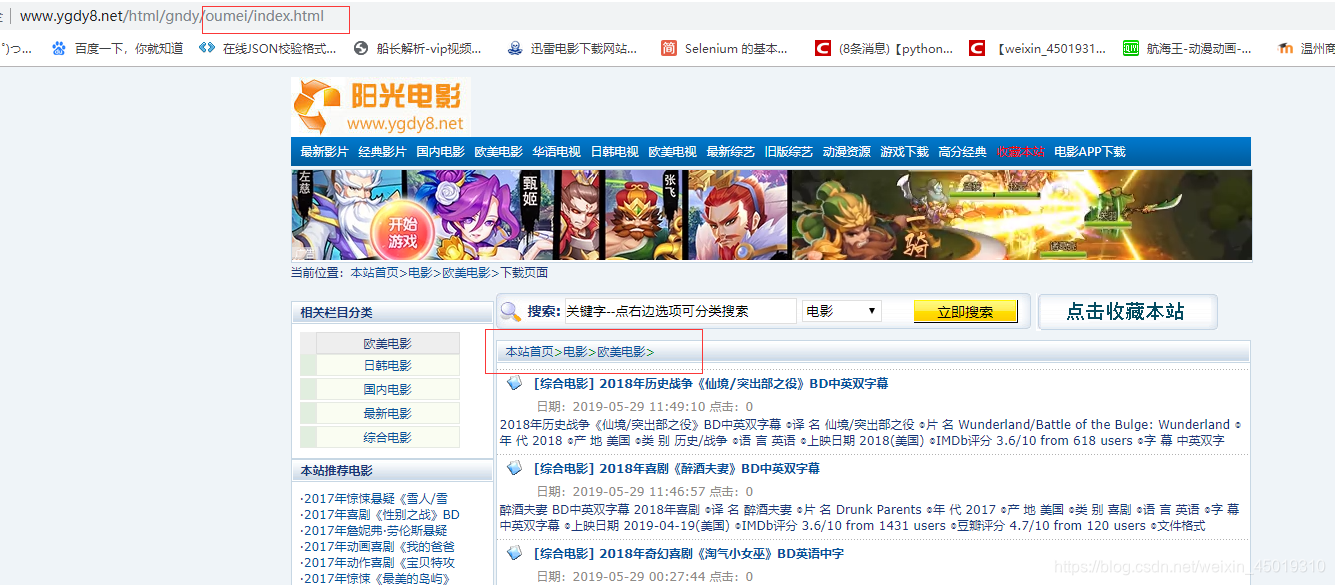
第二个规则是匹配导航栏下每一页的信息,都是由list下划
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









