







目录
1.3.5 HDFS、Yarn、MapReduce三者之间的关系
2.4 NameNode和Secondary NameNode
2.4.1 NameNode和Secondary NameNode的工作机制
3.2.2 Capacity Scheduler——容量调度器
4.3.1.4 CombineTextInputFormat
5.6.2 非第一次启动——服务器运行期间无法与leader保持连接
6.3.1 故障转移处理器——Failover Sink Processor
6.3.2 负载平衡处理器——Failover Sink Processor
6.4.1 多路复用通道选择器——Multiplexing Channel Selector
7.4.2 kafka-console-producer.sh
7.4.3 kafka-console-consumer.sh
8.8.2.4.4 Sort Merge Bucket Map Join
此文章是我在尚硅谷的大数据课程的学习过程中做的一些总结,主要目的是为了让自己更好的理解。如果有不合适的地方可以私下联系我。
一、Hadoop基本内容
1.1 Hadoop概述
Hadoop是一个由Apache基金会开发的分布式系统架构,主要解决海量数据的存储和海量数据的计算问题。
下载地址:https://hadoop.apache.org/releases.html
1.2 Hadoop的优势(4高)
- 高可靠性:Hadoop底层维护多个数据副本,所以即使某个计算元素或存储出现故障,也不会导致数据的丢失。
- 高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。(可以动态增加服务器)
- 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
- 高容错性:能够自动将失败的任务重新分配。
1.3 Hadoop的组成和架构概述
1.3.1 Hadoop的组成
| Hadoop1.x | Hadoop2.x / Hadoop3.x |
| MapReduce 计算+资源调度 |
MapReduce 计算 |
| Yarn 资源调度 |
|
| HDFS 数据存储 |
HDFS 数据存储 |
| Common 辅助工具 |
Common 辅助工具 |
Common:是 Hadoop 体系最底层的一个模块,为 Hadoop 各子项目提供各种工具,如:配置文件和日志操作等。
HDFS:是一个分布式的文件系统,通过目录树来定位文件,主要用于存储文件。HDFS适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
MapReduce:是一个分布式运算程序的编程框架,它的核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
Yarn:是一个资源调度平台,负责作业调度和集群资源管理。
1.3.2 HDFS架构概述
Hadoop Dsitributed File System,简称HDFS,是一个分布式文件系统。主要包含三个节点,分别为NameNode、DataNode和Secondary NameNode。
NameNode(nn):存储文件的元数据,如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
1.3.3 Yarn架构概述
Yet Another Resource Negotiator,简称Yarn,是Hadoop的资源管理器(主要管理的是CPU和内存)。主要包含四个节点,分别为ResourceManager、NodeManager、ApplicationMaster、Container。

ResourceManager(RM):负责整个集群的资源分配和作业调度。
NodeManager(NM):负责管理单个节点服务器资源。
ApplicationMaster(AM):负责管理单个任务运行。
Container:容器,相当于一台独立服务器,里面封装了任务运行所需要的资源。
注:一个Container默认内存是 1 - 8 G,默认 1 个CPU。根据上图,1 个NodeManager是 4G 内存,2 个CPU,所以按照内存来说最多可以开启 4 个Container,按照CPU来说最多可以开启 2 个Container,所以综合起来最多开启2个Container。
1.3.4 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map阶段和Reduce阶段。

Map阶段:并行处理输入数据。
Reduce阶段:对Map阶段结果进行汇总。
1.3.5 HDFS、Yarn、MapReduce三者之间的关系

需求:客户端Client向集群提交一个任务,从100T文件中查询ss1505_wuma.avi。
- 客户端Client提交任务后,ResourceManager接收到任务后分配NodeManager,并开启Container将任务放进去,即ApplicationMaster;
- ApplicationMaster向ResourceManager申请运行任务所需的资源;
- ResourceManager查看是否有所需的资源,若有资源ApplicationMaster将在对应节点开启Map Task;
- Map Task开始工作后,每个Map Task独立工作,各自负责检索各自对应的DataNode,不管有没有检索到,都会返回一个结果,并将结果汇总起来写入HDFS磁盘中;
- 随后在NameNode上进行记账操作,记录汇总结果的文件信息,Secondary NameNode也备份部分信息。
1.4 大数据技术生态体系

工具解释:
- Sqoop:主要用于Hadoop、Hive与传统数据库(MySQL)间进行数据的传递,可以将一个关系型数据库的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中;
- Flume:是一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
- Kafka:是一种可吞吐量的分布式发布订阅消息系统;
- Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库, 它是一个适合于非结构化数据存储的数据库。
- Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张 数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行。
- Spark:Spark是当前最流行的开源大数据内存计算框架,它可以基于 Hadoop 上存储的大数据进行计算。
- Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
- Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
- ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
1.5 Hadoop安装过程中的一些散装知识
1.5.1 在安装Hadoop时的一些重要目录
| 目录名称 | 目录解释 |
| bin | 存放对Hadoop相关服务(hdfs、yarn、mapred)进行操作的脚本 |
| etc |
Hadoop 的配置文件目录,存放 Hadoop 的配置文件 |
| lib | 存放 Hadoop 的本地库(对数据进行压缩解压缩功能) |
| sbin | 存放启动或停止 Hadoop 相关服务的脚本 |
| share | 存放 Hadoop 的依赖 jar 包、文档和官方案例 |
1.5.2 Hadoop常见端口号

额外:
- kafka 默认对客户端暴露的连接端口号:9092;
- zookeeper默认对客户端暴露的连接端口号:2181;
- Spark查看当前Spark-shell运行任务情况端口号:4040;
- Spark历史服务器端口号:18080
1.5.3 Hadoop常用配置文件
| Hadoop2.x | Hadoop3.x | hadoop3.x配置文件解释 |
| core-site.xml | core-site.xml | 1. 指定namenode地址:配置namenode在102服务器上 2. hadoop数据的存储目录 3. hdfs网页登录使用的静态用户 |
| hdfs-site.xml | hdfs-site.xml | 1. nn web端访问地址 2. 2nn web端访问地址:配置2nn在104服务器上 |
| yarn-site.xml | yarn-site.xml | 1. 指定MR走shuffle 2. 指定resourcemanager地址:配置rm在103服务器上 3. 环境变量的继承(3.2版本后无需配置) 4. 开启日志聚集功能、设置日志聚集服务器地址、日志保留时间(秒) |
| mapred-site.xml | mapred-site.xml | 1. 指定mapreduce程序运行在yarn上 2. 配置历史服务器地址和web端地址:配置历史服务器在102上 |
| slaves | workers | 1. 添加所有允许参与的主机名称 |
1.5.4 集群配置规划
- NameNode和Secondary NameNode不要安装在同一台服务器上;
- ResourceManager也很消耗资源,不要和NameNode、Secondary NameNode配置在一台服务器上。

1.5.5 集群启动 / 停止方式总结
| 指令 | 命令 |
| 整体启动/停止HDFS | start-dfs.sh / stop-dfs.sh |
| 分别启动/停止HDFS组件 | hdfs –daemon start / stop namenode/datanode/secondarynamenode |
| 整体启动/停止Yarn | start-yarn.sh / stop-yarn.sh |
| 分别启动/停止Yarn组件 | yarn -daemon start / stop resourcemanager/nodemanager |
1.5.6 Web端查看Hadoop的信息
查看HDFS上存储的文件信息:http://hadoop102:9870
查看Yarn上运行的Job信息:http://hadoop103:8088
查看程序的历史运行情况:http://hadoop102:19888/jobhistory
1.5.7 开启 / 关闭集群的常用命令
- 开启集群顺序:hafs-->yarn-->历史服务器
- 关闭集群顺序:历史服务器-->yarn-->hdfs
# myhadoop.sh是自己编写的代码
# 开启集群->zookeeper
>>>[xxx@hadoop102 ~]$ myhadoop.sh start
>>>[xxx@hadoop102 ~]$ zk.sh start
# 查看多台服务器的节点开启状态
>>>[xxx@hadoop102 ~]$ jpsall
# 正常运行时
# 开启hdfs,第一次运行需要格式化namenode
>>>[xxx@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
>>>[xxx@hadoop102 hadoop-3.1.3]$ /sbin/start-dfs.sh
# 如果是开启hdfs的某个组件
>>>[xxx@hadoop102 hadoop-3.1.3]$ hdfs --daemon start/stop namenode/datanode/secondarynamenode
# 开启yarn,配置在hadoop103上
>>>[xxx@hadoop103 hadoop-3.1.3]$ /sbin/start-yarn.sh
# 如果是开启yarn的某个组件
>>>[xxx@hadoop102 hadoop-3.1.3]$ hdfs --daemon start/stop namenode/datanode/secondarynamenode
# 开启历史服务器,配置在hadoop102上
[xxx@hadoop102 hadoop-3.1.3]$ mapred --daemon start historyserver
# 查看进程
>>>[xxx@hadoop102 hadoop-3.1.3]$ jps
# 开启zookeeper
>>>[xxx@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
>>>[xxx@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
>>>[xxx@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
PS:关闭集群同上,将start改为stop即可。
注:myhadoop.sh 和 jpsall 是已经提前写好的封装代码。
1.5.8 安装时可能出现的问题
问题:当数据被误删后,集群挂掉 或者 NameNode和DataNode只能有一个工作时,问题如何解决?
- 第一步:先杀死所有的进程; [hadoop-3.1.3]$ /sbin/stop-dfs.sh
- 第二步:删除DataNode里的所有信息,把data和logs数据全删除; [hadoop-3.1.3]$ rm -rf data/ logs/
- 第三步:格式化NameNode; [hadoop-3.1.3]$ hdfs namenode -format
- 第四步:重新启动集群。 [hadoop-3.1.3]$ /sbin/start-dfs.sh
1.5.9 免密登录原理
1.5.9.1 原理

# 注:xxx是用户,root是管理员账号
# 使用过ssh,家目录下会有.ssh文件
# 首先进入.ssh文件
>>>[xxx@hadoop102 ~]$ cd .ssh/
# 生成公钥和私钥,执行后敲三次回车获得id_rsa(私钥)和id_rsa.pub(公钥)
>>>[xxx@hadoop102 .ssh]$ ssh-keygen -t rsa
# 将公钥拷贝到hadoop102、hadoop103、hadoop104
>>>[xxx@hadoop102 .ssh]$ ssh-copy-id hadoop102
>>>[xxx@hadoop102 .ssh]$ ssh-copy-id hadoop103
>>>[xxx@hadoop102 .ssh]$ ssh-copy-id hadoop104
# 如果想三台服务器分别都可以免密登录到另外的服务器上,还需要对103和104进行配置
>>>[xxx@hadoop103 .ssh]$ ssh-keygen -t rsa
>>>[xxx@hadoop103 .ssh]$ ssh-copy-id hadoop102
>>>[xxx@hadoop103 .ssh]$ ssh-copy-id hadoop103
>>>[xxx@hadoop103 .ssh]$ ssh-copy-id hadoop104
>>>[xxx@hadoop104 .ssh]$ ssh-keygen -t rsa
>>>[xxx@hadoop104 .ssh]$ ssh-copy-id hadoop102
>>>[xxx@hadoop104 .ssh]$ ssh-copy-id hadoop103
>>>[xxx@hadoop104 .ssh]$ ssh-copy-id hadoop104
# 如果将账号切换为root账号,再次使用ssh登录其他服务器是需要密码的,因此对root账号也是需要配置的
>>>[xxx@hadoop102 .ssh]$ su root
>>>[root@hadoop102 .ssh]# ssh-keygen -t rsa
>>>[root@hadoop102 .ssh]# ssh-copy-id hadoop102
>>>[root@hadoop102 .ssh]# ssh-copy-id hadoop103
>>>[root@hadoop102 .ssh]# ssh-copy-id hadoop104
# 同理,103、104分别也进行配置
1.5.9.2 .ssh文件功能解释

二、HDFS详细介绍
2.1 HDFS概述
2.1.1 HDFS背景和定义
随着数据量越来越大,一个操作系统存不下所有的数据,那么就需要将数据分配到更多的操作系统管理的磁盘中,但是这样的方式不方便管理和维护,所以就迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS 只是分布式文件管理系统中的一种。
HDFS(Hadoop Distributed File System),它是一个用于存储文件的文件系统,通过目录树来定位文件。其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
2.1.2 优缺点
优点:
- 高容错性:数据自动保存多个副本。它通过增加副本的方式提高容错性。当某一个副本丢失以后,它可以自动恢复。
- 适合处理大数据
- 数据规模:能够处理数据规模达到GB、TB,甚至PB级的数据;
- 文件规模:能够处理百万规模以上的文件数量;
- 易于使用:可构建在便宜的机器上,通过多副本机制,提高可靠性。
缺点:
- 不适合低时延数据访问,比如毫秒级的存储数据,是做不到的。
- 无法高效的对大量小文件进行存储。
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标;
- 不支持并发写入、文件随机修改。
- 一个文件只能有一个写,不允许多个线程同时写;
- 仅支持数据append(追加),不支持文件的随机修改。
2.1.3 组成架构

NameNode:就是Master,是一个主管或管理者。
- 管理HDFS的名称空间;
- 配置副本策略;
- 管理数据块(Block)的映射信息;
- 处理客户端读写请求。
DataNode:NameNode下达命令,DataNode执行实际的操作。
- 存储实际的数据块;
- 执行数据的读 / 写操作;
Secondary NameNode:并非NameNode的热备。当NameNode挂掉时,它不能马上替换NameNode并提供服务。
- 辅助NameNode,分担其工作量。比如定期合并Fsimage和Edits,并推送给NameNode;
- 在紧急情况下,可辅助恢复NameNode。
Client:就是客户端。
- 文件切分。文件上传HDFS时,Client将文件切分为一个一个的Block,然后进行上传;
- 与NameNode交互,获取文件的位置信息;
- 与DataNode交互,读取或写入数据;
- Client提供一些命令来管理HDFS,比如NameNode格式化;
- Client可以通过一些命令来访问HDFS,比如对HDFS增删改查操作。
2.1.4 HDFS文件块大小
HDFS中的文件在物理上是分块存储,块的大小可以通过配置参数( dfs.blocksize )规定,默认大小是 128M 或 256M(2.x和3.x),1.x版本是64M;
总结:HDFS文件块的大小主要取决于磁盘的传输速率。
分析过程:
- 集群中将文件分为多个文件块,即1-n block;
- 如果寻址时间为10ms,即查找到目标block的时间为10ms;
- 专家说,寻址时间为传输时间的1%是最佳的。因此可以计算传输时间为1s;
- 而目前磁盘的传输速率普遍为100MB/s,所以100MB/s * 1s = 100MB,计算机里100MB不是一个整数,所以我们取值为128M。
- 当磁盘的传输速率为200~300MB/s时,通常取值为256MB最佳。
所以,HDFS块大小为128M或者256M。
问题:为什么块的大小不能设置太小,也不能设置太大?
- 如果HDFS块设置太大,从磁盘传输数据的时间会明显大于定位这个块的开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
- 如果HDFS块设置太小,会增加寻址时间,程序一直在找块的位置;
2.2 HDFS的Shell操作
通常使用 hadoop fs 或者 hadoop dfs

2.3 HDFS的读写流程(重点)
2.3.1 HDFS读取数据流程

- 客户端通过 DistributedFileSystem 向 NameNode 请求下载文件,NameNode 通过查 询元数据,找到文件块所在的 DataNode 地址。
- 挑选一台 DataNode(就近原则,然后查看当前节点的负载均衡再随机挑选别的)服务器,请求读取数据。
- DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验)。(串行读取数据)
- 客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
2.3.2 HDFS写入数据流程


- HDFS 通过创建一个DistributedFileSystem客户端使用RPC方法向NameNode请求上传一个文件;
- NameNode接收RPC后,检查权限和目录结构确定目标文件是否可以上传和存在。检查完之后写入到目录树里并返回是否可以上传;
- 创建一个new DFSOutputStream数据流用来计算各个文件(block、packet等)的大小。并启动DataStreamer线程,其中存放了一个dataQueue的消息队列,用于存储读取到的数据(各个packet);
- 将block块写成512byte的chunk+4byte的checksum的形式,写够127个时形成一个packet,并将packet写入dataQueue中。
- 在dataQueue有数据之后就需要写入到具体的datanode里了。但是具体写入到哪些datanode,就需要使用RPC方法与namenode通信,根据机构感知策略获取具体存放在dn1、dn2和dn3上;
- dataStremaer线程通过socket把一个个packet写入dn1中,并同时把数据备份到一个ackQueue,防止数据写入失败数据丢失;
- 由于是跨进程通信,dn1启用了DataXceiveServer接收服务,并调用BlockReceiver将packet一部分写入磁盘中,另一部分通过socket把packet发送给dn2、dn2接收packet后也是一部分写入磁盘中,另一部分通过socket把packet发送给dn3、dn3接收到packet后写入磁盘中;
- dn3写入成功后返回给dn2应答、dn2写入成功后返回给dn1应答、dn1写入成功后返回给客户端,客户端通过ResponseProcessor接收应答;如果应答全部正确接收,删除ackQueue中的packet数据;如果接收失败,将ackQueue中的packet数据重新写入到dataQueue中;
- 最后重复4-8过程,直至成功上传数据。
2.3.3 网络拓扑-节点距离计算
在HDFS写数据时,NameNode会选择距离待上传数据最近距离的DataNode接收数据。
节点距离:两个节点到达最近的共同祖先的距离总和。

节点距离计算举例
举例:Distance(/d1/r2/n1, /d2/r4/n1) = 6
解析:先找共同的祖先(/)
- /d1/r2/n1
- 第一层祖先是r2,/d1/r2/n1与其距离为1;
- 第二层祖先是d1,/d1/r2/n1与其距离为2;
- 第三层祖先是/,/d1/r2/n1与其距离为3;
- /d2/r4/n1
- 第一层祖先是r4,/d2/r4/n1与其距离为1;
- 第二层祖先是d2,/d2/r4/n1与其距离为2;
- 第三层祖先是/,/d2/r4/n1与其距离为3;
- 所以,/d1/r2/n1与/d2/r4/n1的距离为6。
2.3.4 机架感知(副本存储节点选择)

2.3.4.1 机架感知的概念
简单版本的概念解析:
- 机架:可以理解为存放一组服务器的柜子,比如上图的机架r1、r2、r3等;
- 机架感知:是HDFS中副本存储节点选择的一种策略。
正式版本的概念解析:
Hadoop的机架感知功能是一种能够识别集群中各个节点所属机架,并在任务调度和数据块副本放置时利用这些信息来优化数据传输和任务执行效率的功能。机架感知的设计基于Hadoop集群的网络拓扑结构,通过将节点和机架的信息进行映射,Hadoop可以更加智能地管理集群资源。
2.3.4.2 机架感知的作用
- 提高数据传输效率:在进行数据块副本放置时,机架感知功能可以尽量将数据块的副本放置在不同的机架上,这样可以避免大量数据在同一机架内的节点之间传输,从而减少网络拥堵,提高数据传输效率;
- 增强容错能力:由于数据块的多个副本被放置在不同的机架上,即使某个机架出现故障,Hadoop也可以从其他机架上的节点获取数据,保证了数据的可靠性和可用性;
- 优化任务调度:在执行MapReduce等任务时,机架感知功能可以帮助Hadoop将任务分配给离数据最近的节点,从而减少数据传输的开销,提高任务执行效率。
注:机架感知功能在Hadoop中默认是关闭的,需要手动开启才能使用。
2.4 NameNode和Secondary NameNode
2.4.1 NameNode和Secondary NameNode的工作机制
前置条件:需要引入Fsimage和Edits文件的产生原理。Fsimage和Edits的产生需要思考一个问题,即:NameNode的元数据是存储在哪里的?
分析过程:
- 如果只存储在NameNode节点的磁盘中:
- 优点:可靠性高;
- 缺点:需要经常进行随机访问和响应客户请求,效率低;
- 如果只存储在内存中:
- 优点:计算快,效率高;
- 缺点:一旦断电,元数据丢失,整个集群无法工作。
- 如果磁盘一份(Fsimage)、内存一份:
- 可靠性高;
- 如果是在磁盘中对文件随机读写(修改历史数据),效率仍然是低的;如果将修改历史数据的操作变为在文件末尾追加元数据(Edits),效率将大大提升。
因此,引入 Fsimage 文件和 Edits 文件,每当元数据有更新或者添加时,修改内存中的元数据并追加到Edits文件中。可以通过定期合并 Fsimage 和 Edits ,合成元数据。
但是,如果定期合并 Fsimage 和 Edits 由 NameNode 节点完成,又会导致效率过低。因此,引入一个新的节点 SecondaryNamenode , 专门用于 Fsimage 和 Edits 的合并。
注解:在磁盘中存储元数据的文件为Fsimage,在文件末尾追加元数据的文件为Edits。

第一阶段:NameNode启动
- 第一次启动 NameNode 格式化后,创建 Fsimage 和 Edits 文件。如果不是第一次启动,直接加载编辑日志(edits_inprogress_001)和镜像文件(fsimage)到内存;
- 客户端 client 向 NameNode 请求对元数据进行增删改;
- NameNode 在 edits_inprogress_001 中记录操作日志,更新滚动日志;
- NameNode 根据 edits_inprogress_001 里的日志内容在内存中对元数据进行增删改。
第二阶段:Secondary NameNode启动
- Secondary NameNode 询问 NameNode 是否需要 CheckPoint,并返回 NameNode 的检查结果;
- Secondary NameNode 向 NameNode 请求执行 CheckPoint;
- NameNode 滚动正在写的 Edits 日志(edits_inprogress_001);
(1)生成一个新的 Edits 日志(edits_inprogress_002),客户端请求的增删改操作 会记录在该日志文件中;
(2)将当前的日志文件(edits_inprogress_001)重命名为 edits_001;
- 将滚动前的编辑日志(edits_001)和镜像文件(fsimage)拷贝到 Secondary NameNode;
- Secondary NameNode 加载编辑日志(edits_001)和镜像文件(fsimage)到内存,并进行合并;
- 合并后生成新的镜像文件 fsimage.chkpoint;
- 拷贝 fsimage.chkpoint 到 NameNode;
- NameNode 将 fsimage.chkpoint 重新命名成 fsimage。
2.4.2 Fsimage 和 Edits 解析
每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
2.4.2.1 Fsimage 概念和命令
Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
-
对于文件来说包括了数据块描述信息、修改时间、访问时间等。
-
对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。
- oiv 查看 Fsimage 文件
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径 # 输入命令: [xxx@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000075 -o /opt/module/hadoop-3.1.3/fsimage.xml # 将fsimage.xml下载到桌面 [xxx@hadoop102 current]$ sz /opt/module/hadoop-3.1.3/fsimage.xml
思考:根据 fsimage.xml 文件可以看出,Fsimage 中没有记录块所对应 DataNode,为什么?
答:是因为在集群启动后,要求 DataNode 向NameNode上报数据块信息,间隔一段时间后会再次上报。
2.4.2.2 Edits 概念和命令
Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
- oev 查看 Edits 文件
hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径 # 输入命令 [xxx@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000061-0000000000000000075 -o /opt/module/hadoop-3.1.3/edits.xml # 将edits.xml下载到桌面 [xxx@hadoop102 current]$ sz /opt/module/hadoop-3.1.3/edits.xml
2.4.3 CheckPoint 时间设置 (了解即可)
- 通常情况下,Secondary NameNode 每隔一小时执行一次。(hdfs-default.xml 的默认值)
- 一分钟检查一次操作次数,当操作次数达到一百万时,Secondary NameNode 执行一次。(hdfs-default.xml 的默认值)
2.5 DataNode 工作机制
2.5.1 DataNode 工作机制

- 一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳;
- DataNode 启动后向 NameNode 注册(上报数据块Block信息),注册通过后,NameNode将对应信息记录在元数据里,并向DataNode返回结果;
- 随后,DataNode 周期性(6 小时)的向 NameNode 上报所有的块信息;
- 心跳(即:DataNode 与 NameNode 之间的交互)是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令,比如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 DataNode 的心跳, 则认为该 DataNode 节点不可用;
- 集群运行中可以安全加入和退出一些机器。
2.5.2 数据完整性(先做了解)
如下是 DataNode 节点保证数据完整性的方法:
(1)当 DataNode 读取 Block 的时候,它会计算 CheckSum。
(2)如果计算后的 CheckSum,与 Block 创建时值不一样,说明 Block 已经损坏。
(3)Client 读取其他 DataNode 上的 Block。
(4)常见的校验算法 crc(32),md5(128),sha1(160)。
(5)DataNode 在其文件创建后周期验证 CheckSum。
2.5.3 掉线时限参数设置

- dfs.namenode.heartbeat.recheck-interval 和 dfs.heartbeat.interval 都在 hdfs-default.xml 有默认值。dfs.namenode.heartbeat.recheck-interval 默认值为5min,dfs.heartbeat.interval 默认为3s,可以根据自己需求灵活配置,但是公式要知道怎么计算的。
2.6 HDFS的一些散装知识
2.6.1 hdfs小文件处理


2.6.2 hdfs的NameNode内存
- Hadoop2.x 系列,配置 NameNode 默认 2000M。
- Hadoop3.x 系列,配置 NameNode 内存是动态分配的。
- NameNode 内存最小值 1G,每增加 100 万个文件 block,增加 1G 内存。
三、Yarn详细介绍
3.1 Yarn概述
3.1.1 组成架构
Yarn主要由ResourceManager、NodeManager、Container、ApplicationMaster组件构成。

3.1.2 工作机制(重点)

- MR 程序提交到客户端所在的节点;
- YarnRunner 向 ResourceMangaer 申请一个 Application;
- ResourceMangaer 向 YarnRunner 返回 Application 的资源提交路径;
- 程序将运行所需资源提交到HDFS上;
- 资源提交完毕后,申请运行MRAppMaster;
- ResourceMangaer 将用户请求初始化为一个Task,并放入FIFO调度队列里;
- 当Task排到,由NodeManager领取Task任务,并开启Container生产MRAppMaster;
- Container从HDFS拷贝资源到本地;
- MRAppMaster 向 ResourceMangaer 申请运行 Map Task 的容器;
- ResourceMangaer 将运行 MapTask 任务分配给空闲的 NodeManager,空闲的 NodeManager 领取到任务并创建容器;
- MRAppMaster 向接收到任务的 NodeManager 发送程序启动脚本,NodeManager 启动 MapTask,MapTask 运行结束后对数据按照分区持久化到磁盘;
- MRAppMaster 等所有的 Map Task 运行完毕后,向 ResourceMangaer 申请容器运行 Reduce Task;
- ResourceMangaer 将运行 ReduceTask 任务分配给空闲的 NodeManager,空闲的 NodeManager 领取到任务并创建容器将 Reduce Task放进去,同时 Reduce 向 Map 获取相应分区的数据进行运行;
- 程序运行结束后,MRAppMaster 向 ResourceMangaer 请求注销自己。
3.2 Yarn调度器
Hadoop 作业调度器主要有三种:FIFO、容量(Capacity Scheduler) 和公平 (Fair Scheduler) 。
- Apache Hadoop3.1.3 默认的资源调度器是 Capacity Scheduler。
- CDH 框架默认调度器是 Fair Scheduler。
3.2.1 FIFO——先进先出调度器
FIFO 调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务。
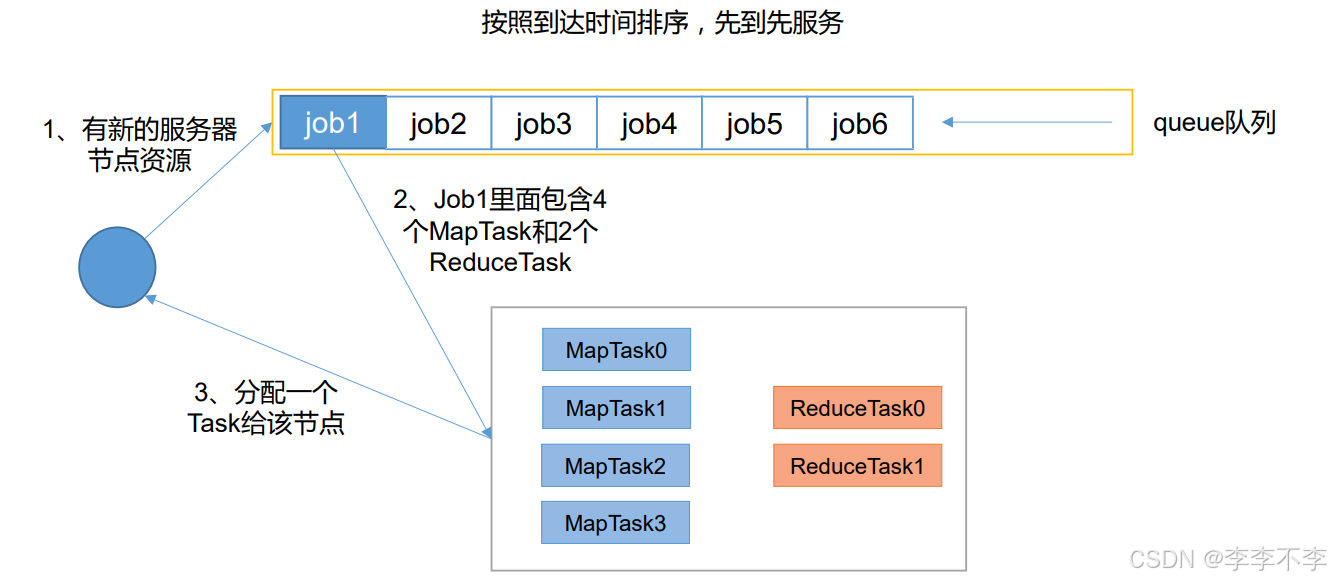
3.2.2 Capacity Scheduler——容量调度器
Capacity Scheduler 是 Yahoo 开发的多用户调度器。
3.2.2.1 容量调度器特点

特点:
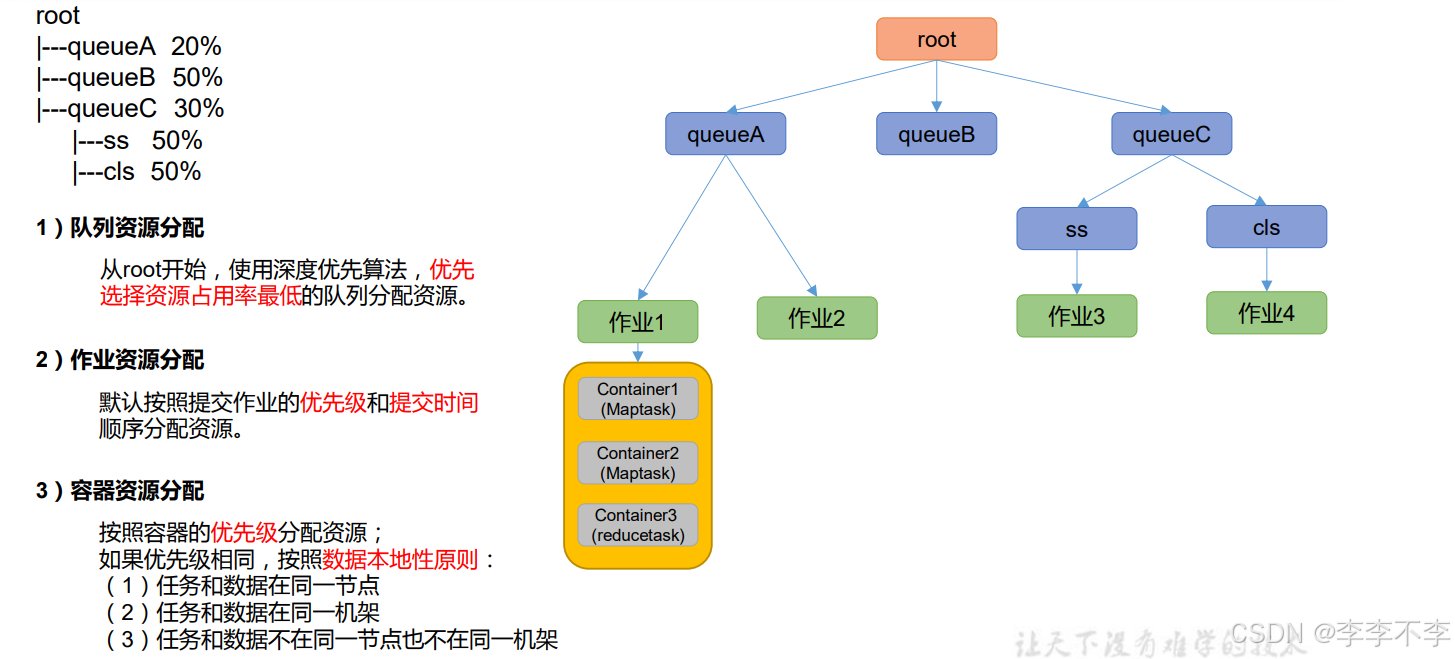
- 多队列:每个队列可配置一定的资源量,每个队列采用FIFO调度策略,在同一个队列中优先满足先进入队列的资源,如果先进的 job 资源满足可以同时开启下一个 job 。
- 容量保证:管理员可为每个队列设置资源最低保证和资源使用上限。
- 灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用 程序提交,则其他队列借调的资源会归还给该队列。
- 多租户:
- 支持多用户共享集群和多应用程序同时运行。
- 为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
3.2.2.2 容量调度器的资源分配算法
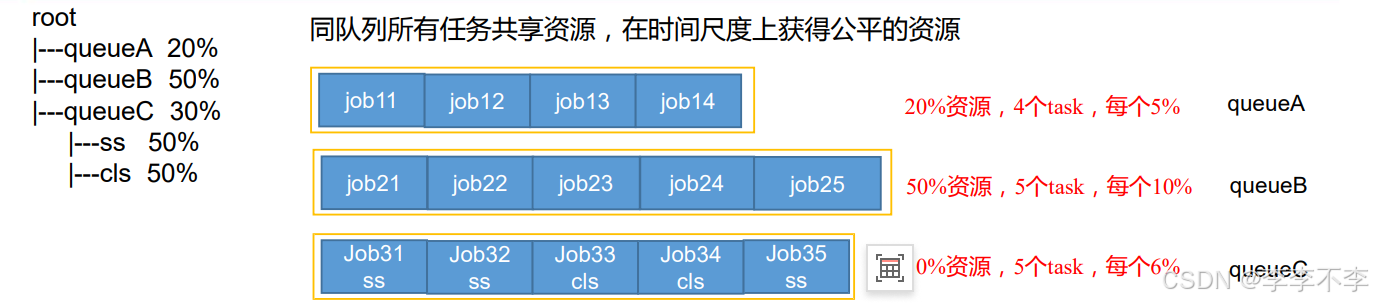
3.2.3 Fair Scheduler——公平调度器
Fair Schedulere 是 Facebook 开发的多用户调度器。
3.2.3.1 公平调度器特点

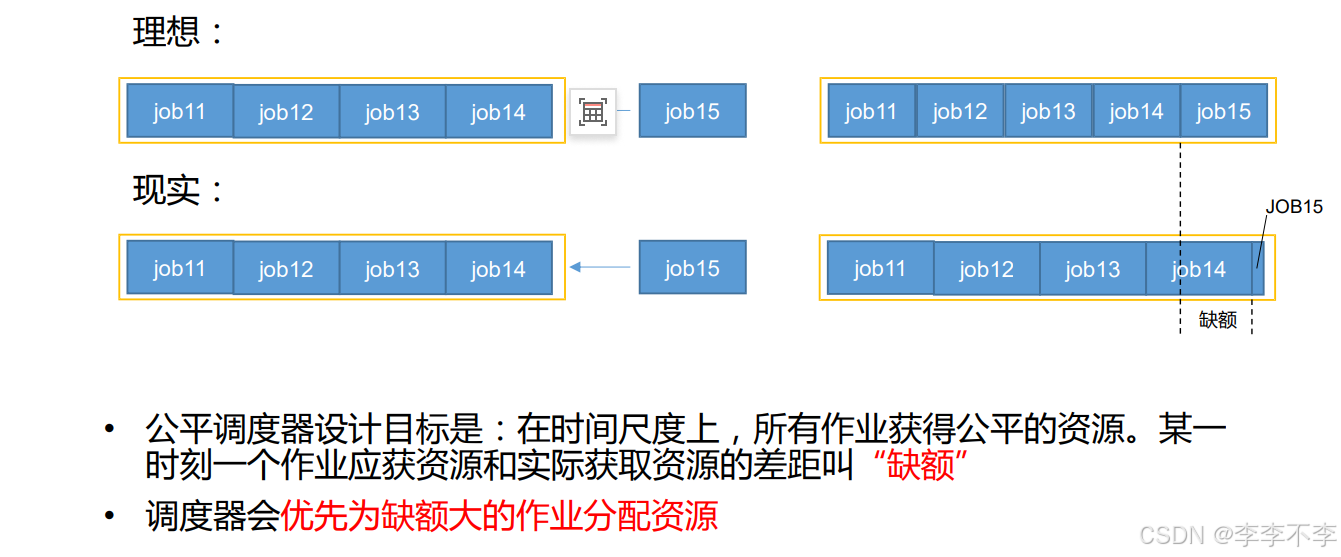
补充一下缺额的概念:
3.2.3.2 公平调度器资源分配算法
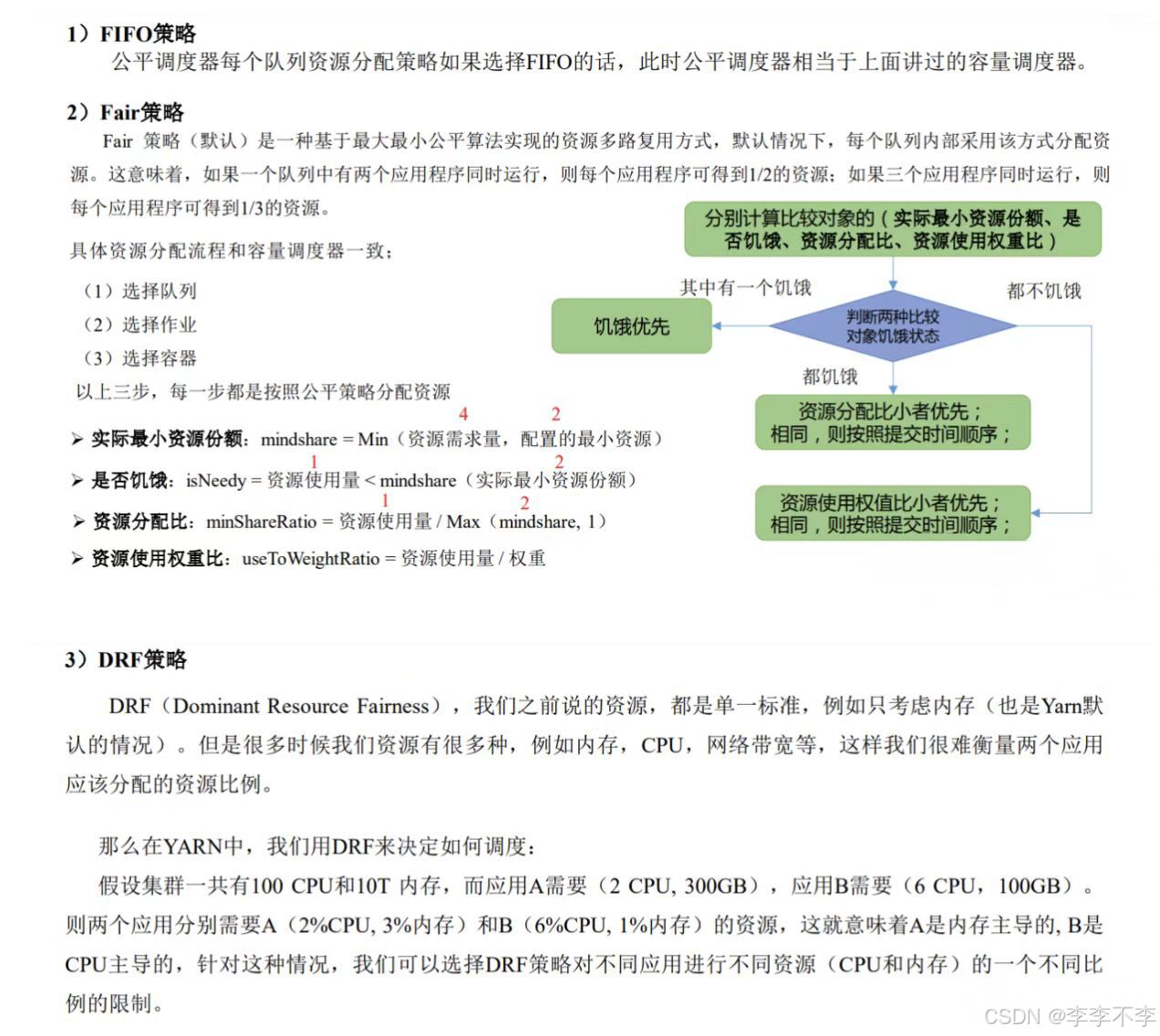
公平调度器案例1——按队列资源分配:
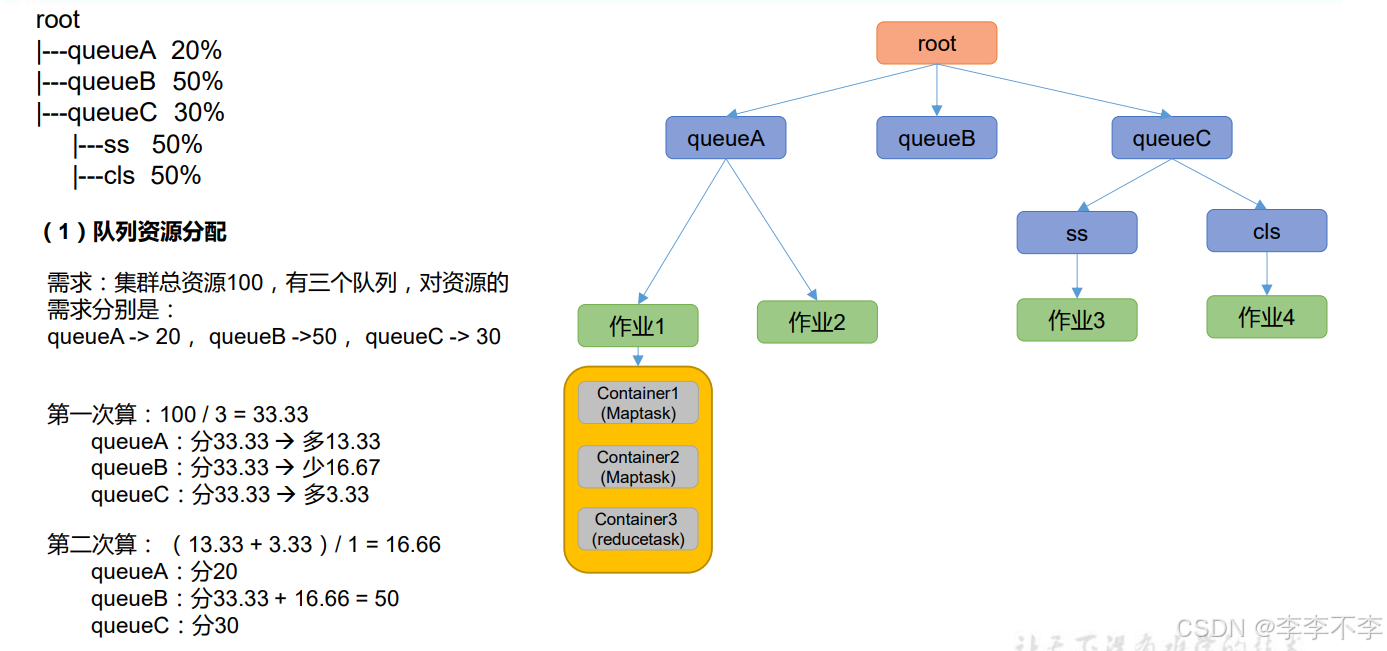
公平调度器案例2——按作业资源分配:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2347
2347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









