







数据库索引是什么?
数据库索引是数据库中对一列或多列的值进行排序的一种结构
也就是说:索引就像书的目录一样可以非常快速的定位到书的页码。
如果向mysql发出一条sql语句请求,查询的字段没有创建索引的话,可能会导致全表扫描,这样查询效率非常低
索引分类
索引分为聚簇索引和非聚簇索引
聚簇索引按照数据存放的物理位置排序,提高多行检索速度
非聚簇索引提高单行检索速度
数据库储存结构
Hash
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
优点:通过字段的值计算的hash值,定位数据非常快,查找可以直接根据key访问。
缺点: 因为底层数据结构是散列的,无法进行比较大小,不能进行范围查找
index=Hash(key)
B树 平衡搜索树,实际使用会加上平衡算法即平衡二叉搜索树

- 所有非叶子结点至多拥有两个儿子(Left和Right);
- 所有结点存储一个关键字;
- 非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
B-树 多路搜索树(不是二叉的)
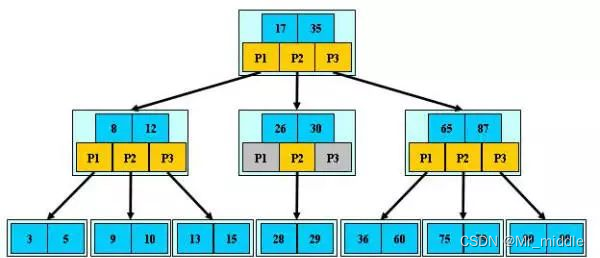
设M为非叶子节点中“区域”(P1、P2、P3)划分的个数
- 定义任意非叶子结点最多只有M个儿子;且M>2;
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M];(向下取整[1.5,3]取[1,3])
- 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
- 非叶子结点的关键字个数=指向儿子的指针个数-1;
- 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
- 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
- 所有叶子结点位于
同一层;
B-树的特性:
- 关键字集合分布在整颗树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束;
- 其搜索性能等价于在关键字全集内做一次二分查找;
- 自动层次控制;
B+树
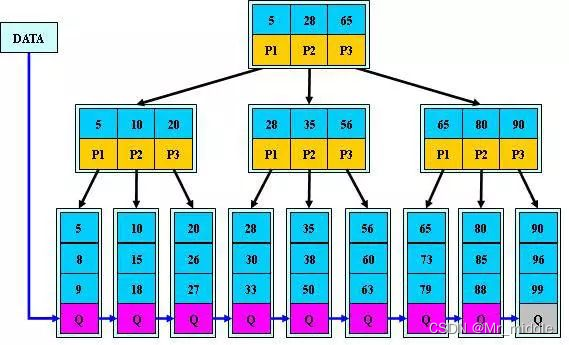
- 其定义基本与B-树相同
- 非叶子结点的子树指针与关键字个数相同;
- 非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
- 为所有叶子结点增加一个链指针;
- 所有关键字都在叶子结点出现;
B+树的特性:
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 更适合文件索引系统;
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
参考博客链接:
什么是B+树 – 王小鑫
数据库索引:B树、B-树、B+树、B*树详解















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









