






LSTM&DRQN的Python实现
1.LSTM模块的实现
最近在尝试实现一个简单的LSTMCell,源码中看似只是简单地调用一下:
tf.contrib.rnn.BasicLSTMCell()
实际上包含了很多没有弄明白地方。我想把这个学习过程完整地记录一遍。
首先,构建LSTM单元需要导入:
import tensorflow as tf
import numpy as np
还是看看输入到底是什么
上周的报告已经提到,LSTM单元中喂进的数据是一个3维数据,维度分别是input_size,batch_size,time_size。这里把X作为input的数据:
X=np.random.rand(3,6,4)
#batch_size=3,time_size=6,input_size=4
再次指明,input_size和Cell中的hidden_size有关,time_size则是处理一组数据的步长,batch_size则是用户自己选定的(通常开源文献中选为128、256等,从Memory中取出,再投喂给网络)。
为了便于观察Cell的输出结果,我们把X的第二个batch做以下处理:
X=[1,4:]=0
那么输入的三组batch中,每组的实际步长为:
X_length=[6,4,6]
X的输出可以参考如下:
[[[0.97220811 0.25908799 0.54227514 0.41574578]
[0.01295309 0.3510622 0.41254816 0.40131783]
[0.64841554 0.91885768 0.67117895 0.98121062]
[0.14896025 0.3912898 0.1417619 0.43468296]
[0.22438062 0.85157355 0.10037672 0.66274456]
[0.07133907 0.86983479 0.19161431 0.15118635]]
[[0.68270615 0.7659821 0.04970863 0.43649479]
[0.96759885 0.72994591 0.77564044 0.24077003]
[0.94344651 0.98036233 0.85772773 0.67501075]
[0.21152659 0.94275251 0.09053659 0.6004612 ]
[0. 0. 0. 0. ]
[0. 0. 0. 0. ]]
[[0.21548508 0.50614013 0.6444404 0.09635282]
[0.54535114 0.15882572 0.58684033 0.2026541 ]
[0.41272127 0.62597087 0.97968376 0.08931693]
[0.86418767 0.27609746 0.69480801 0.31376662]
[0.0309335 0.36077981 0.22935523 0.12807059]
[0.7778892 0.17223188 0.7626537 0.72124185]]]
#这样就对input的情况进行了一个很清晰的展示!
#time_size是每个batch的步长,但允许有空的位置出现,
这就是第二个batch中的5、6行被全部赋为0的原因。
那么怎么处理这个输入呢?
先来看LSTM的内部构造:
这张图说明,LSTM内部有“四大块”,分别是使用sigmoid函数和tanh函数激活的部分,如下图。
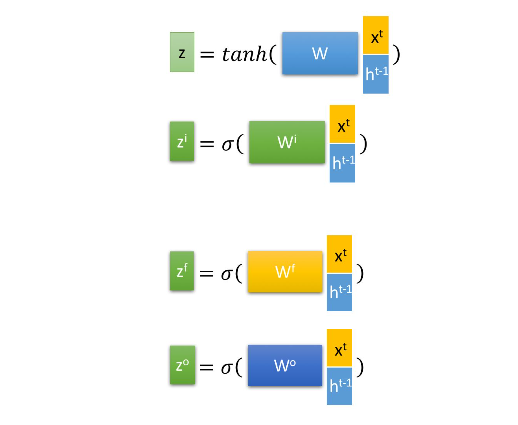
每一块都是一个全连接的神经网络,那么hidden_size就是这个神经网络的每一层的节点数目(文献中指出,LSTM内部的神经网络可以有很多层,但每层的节点数目一般而言是一样的),换言之,内部输出的h_t、c_t的长度都是hidden_size,经过反馈到达输入端,和X_t(input_size)连接以后,权重参数的列数便是(hidden_size+input_size)。
理清了这几个超参数,我们可以写出这样的代码:
hidden_size=5
#创建LSTMcell
cell=tf.contrib.rnn.BasicLSTMCell(num_units=hidden_size,state_is_tuple=True)
接下来让LSTM跑起来:
outputs,last_states=tf.nn.dynamic_rnn(
cell=cell,
dtype=tf.float64,
sequence_length=X_length,
input=X
)
with tf.Session() as session:
session.run(tf.global_variables_initializer())
o1,s1 = session.run([outputs,lats_states])
上面代码中出现了两个个十分重要的函数:tf.contrib.rnn.BasicLSTMCell()、tf.nn.dynamic_rnn()。前一个函数自然是根据我们提供的hidden_size来创建LSTM单元,后一个函数则是给这个LSTM单元input等参数。tf.nn.dynamic_run()有两个返回值,分别是outputs和last_states,这和LSTM的的结构是有关系的。
那么输出呢?
那么输出呢?知道了输入的各种超参数和过程,输出是什么形式?
我们已经提到,tf.nn.danamic_rnn()有两个返回值,outputs和last_states,理解LSTM的输出,需要从这两个tensor入手。
我们来看程序输入的outputs(o1):
#outputs维度是(3, 6, 5)
[[[ 0.10988916 -0.05924489 -0.00219612 0.03131131 0.11956187]
[ 0.14008177 -0.08764294 -0.00184445 0.06144539 0.18363025]
[ 0.09684535 -0.10180583 0.00621872 0.08553708 0.1787711 ]
[ 0.11151131 -0.13483347 -0.01405942 0.12652101 0.28426013]
[ 0.16092931 -0.13378875 0.01335965 0.16779374 0.31270015]
[ 0.1814057 -0.14386612 -0.01726051 0.10565656 0.32259905]]
[[ 0.06112274 -0.03399703 -0.01142925 0.01125745 0.07088148]
[ 0.09888767 -0.10105175 -0.02438729 0.10392439 0.20857589]
[ 0.13660149 -0.12307292 -0.02153195 0.12783929 0.23667747]
[ 0.13729271 -0.140286 -0.0181011 0.17082856 0.27899951]
[ 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. ]]
[[ 0.04344821 -0.06923458 -0.02282487 0.07093523 0.08029628]
[ 0.11463346 -0.09463423 -0.01339233 0.08762536 0.15044823]
[ 0.13361562 -0.12923288 -0.00863851 0.15211888 0.26287943]
[ 0.18059539 -0.13309941 0.0330919 0.17870714 0.31354558]
[ 0.1644137 -0.16305717 -0.01865754 0.16931057 0.34752158]
[ 0.21349885 -0.14284222 0.02098966 0.16654242 0.35304967]]]
每个batch有6个单词(time_step),每个单词有4个字母(input_size),输入3个这样的batch到hidden_size=5(则cell.output_size=hidden_size=5)的全连接网络中,输出自然就是[batch_size,time_size,hidden_size],这样以拆解,就不难理解了outputs了!
那么lats_states呢?顾名思义,last_states就是最后一个状态!
来看输出的last_states(s1):
#lats_stats的维度(2,3,5)。
#这个输出是个tuple,整体上是一个(2,3,5)的数组,实际上是两个(3,5)的数组。
LSTMStateTuple
(c=array([[ 0.37597382, -0.43745685, -0.03624983, 0.28624145, 0.64269234],
[ 0.34083248, -0.38826329, -0.03365382, 0.32866948, 0.49783422],
[ 0.48956227, -0.52104725, 0.03657497, 0.37346697, 0.69955475]]),
h=array([[ 0.1814057 , -0.14386612, -0.01726051, 0.10565656, 0.32259905],
[ 0.13729271, -0.140286 , -0.0181011 , 0.17082856, 0.27899951],
[ 0.21349885, -0.14284222, 0.02098966, 0.16654242, 0.35304967]]))
什么意思呢?
last_states实际上输出的是上面这个单元中的H_t、C_t两个tensor!(LSTM的state是由C_t和 H_t组成的。)
可以看到,H_t是和outputs的最后一行相等的(H_t决定遗忘什么、记住什么)。C_t则是整个Cell的实际输出(DRQN中连接到后面的神经元节点)。
因此shape(last_states)=[2,batch_size,hidden_size]。
可以这样理解:outputs指明了每个batch上的每个time_step的每个input的输出,而last_states(=C_t + H_t)则表明了经过LSTM抽象处理后的最终结果。
最后附上这部分的完整代码:
import tensorflow as tf
import numpy as np
def dynamic_rnn(rnn_type='lstm'):
X=np.random.rand(3,6,4)
X[1,4:]=0
X_length=[6,4,6]
rnn_hidden_size=5
if(rnn_type=='lstm'):
cell=tf.contrib.rnn.BasicLSTMCell(num_units=rnn_hidden_size,state_is_tuple=True)
else:
cell=tf.contrib.rnn.GRUCell(num_units=rnn_hidden_size)
num=cell.output_size
outputs,last_states = tf.nn.dynamic_rnn(
cell=cell,
dtype=tf.float64,
sequence_length=X_length,
inputs=X
)
with tf.Session() as session:
session.run(tf.global_variables_initializer())
o1,s1 = session.run([outputs,last_states])
print(X)
print(np.shape(o1))
print(o1)
print(np.shape(s1))
print(s1)
print(num)
if __name__ == '__main__':
dynamic_rnn(rnn_type='lstm')
为什么要考虑LSTM的输入输出问题?
之前的报告也指出了,既然DRQN要在DNN前面接一个LSTM层,就需要知道这个LSTM层的输出的情况(tensor维度等信息),才能和后面的DNN连接起来。
除此以外,处理图像和视频的DRQN,实质上是这个样子:
一定要知道,在这种DRQN的结构里面,Q-Values就是全连接的DNN网络,前面整个部分是包括了3个卷积层和1个LSTM层的整体。在这种情况下,相比于DQN,图片的输入方式没有任何改变(因为图片面对的是卷积层,DQN和DRQN都是一样的)。
但是,在解决我们项目中的问题时是不使用卷积层的,输入是直接面向LSTM的。这时候输入给DRQN的states同DQN相比就完全不一样了。
如何改造这个输入?如何连接后面的DNN网络?这就是我们一定要搞清楚LSTM输入和输出的原因。
2.DRQN的Python实现
还是要导入python包:
import tensorflow as tf
import numpy as np
还是那个问题:输入是什么?
我们之前已经搞清楚了LSTMCell的输入是一个[batch_size,time_step,input_size]的三维数组。那么针对项目中的频谱分配问题,这个输入怎么安排?
我认为,在单个用户的情况下:
batch_size:自己选定,一般选用128、256等。
inputsize:假定用户使用[A,B,C]三个参量来描述当前的环境,那么input_size=shape([A,B,c]).
timpe_step:用户观察N个时隙,记录N个[A,B,C]tensor,那么time_step=N。
在多用户的情况下(Age of Information-Aware Rdio Resource Management in Vehicular Netwoeks:A Proactive Deep Reinforecment Learning Perspective):
batch_size:仍然自己选用。
input_size:等于shape([A,B,C]).
time_step:等于用户数量N。
因此,输入可以这样设置:
inputs_=tf.placeholder(dtype=tf.float32,
shape=[None,time_step,input_size],
name='inputs')
#batch_size直接定义为None,使用的时候,由投喂函数控制。
创建LSTMCell,输入inputs_:
hidden_size=10;
lstm_=tf.contrib.rnn.BasicLSTMCell(unit_num=hidden_size)
lstm_out,input_state=tf.nn.dynamic_rnn(cell=lstm_,inputs=inputs_,dtype=tf.float32)
还是那个问题:输出是什么?
之前也已经提到,tf.nn.dynamic_rnn()输出的是两个返回值,这里第一个返回值ltsm_out是一个[batch_size,time_step,hidden_size]的tensor,每个batch的最后一行组合在一起,就是H_t。因此:
reduce_out=lstm_out[:,-1,;]
#取出lstm_out每个batch的最后一行,组成H_t
reduce_out就是LSTM层的输入,shape(reduce_out)=[batch_size,input_size]
LSTM怎么和后面的DNN连接起来?
由于shape(reduce_out)=[batch_size,input_size],这样维度的tensor不能直接输入到后面的DNN网络里面(因为还不知道后面的DNN网络第一层节点是多少个)。
假设后面DNN第一层节点的数目仍然是hidden_size,那么使用tf.reshape()来处理
reduce_out=tf.reshape(reduce_out,shape=[-1,hidden_size])
#[-1,hidden_szie]表示把reduce_out转化为一个列数等于hidden_size的tenso。行数自动生成。
终于,我们完整的把LSTM的输入和输出理了一遍,并且把LSTM的输出变为了一个可以直接递交给后面的DNN网络使用的tensor!
后面的内容就和搭建神经网络一致啦。
接下来我们把上面的东西放在一个class里面,形成一个完整可用的Qnetwork:
import tensorflow as tf
import numpy as np
class QNetwork:
def __init__(self, learning_rate=0.01, state_size=4,
action_size=2, hidden_size=10, step_size=1 ,
name='QNetwork'):
with tf.variable_scope(name):
self.inputs_ = tf.placeholder(tf.float32, [None,step_size, state_size], name='inputs_')
self.actions_ = tf.placeholder(tf.int32, [None], name='actions')
one_hot_actions = tf.one_hot(self.actions_, action_size)
self.targetQs_ = tf.placeholder(tf.float32, [None], name='target')
self.lstm = tf.contrib.rnn.BasicLSTMCell(hidden_size)
self.lstm_out, self.state = tf.nn.dynamic_rnn(self.lstm,self.inputs_,dtype=tf.float32)
self.reduced_out = self.lstm_out[:,-1,:]
self.reduced_out = tf.reshape(self.reduced_out,shape=[-1,hidden_size])
self.w2 = tf.Variable(tf.random_uniform([hidden_size,hidden_size]))
self.b2 = tf.Variable(tf.constant(0.1,shape=[hidden_size]))
self.h2 = tf.matmul(self.reduced_out,self.w2) + self.b2
self.h2 = tf.nn.relu(self.h2)
self.h2 = tf.contrib.layers.layer_norm(self.h2)
self.w3 = tf.Variable(tf.random_uniform([hidden_size,action_size]))
self.b3 = tf.Variable(tf.constant(0.1,shape=[action_size]))
self.output = tf.matmul(self.h2,self.w3) + self.b3
#self.output = tf.contrib.layers.layer_norm(self.output)
self.Q = tf.reduce_sum(tf.multiply(self.output, one_hot_actions), axis=1)
self.loss = tf.reduce_mean(tf.square(self.targetQs_ - self.Q))
self.opt = tf.train.AdamOptimizer(learning_rate).minimize(self.loss)















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









