







文章目录
Redis Object
Object是什么
- Redis是
key-value存储,基于内存存储的,key和value在Redis中都被抽象为对象,key只能是String对象,而Value支持丰富的对象种类,包括String、List、Set、HSet、Stream等。
typedef struct redisobject{
unsigned type:4; //哪种Redis对象
unsigned encoding:4; //底层使用的编码格式
unsigned lru:LRU_BITS; //记录对象的访问信息,用于内存淘汰
int refcount; //引用计数,用来描述有多少个指针,指向该对象
void *ptr; //内容指针,指向实际内容
} robj;
主要:type、encoding、*ptr
String
- String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,
value其实不仅是字符串, 也可以是数字(整数或浮点数),value 最多可以容纳的数据长度是 512M。
c语言字符串不足
- 获取字符串长度的时间复杂度为 O(N);
- 字符串的结尾是以 “\0” 字符标识,字符串里面不能包含有 “\0” 字符,因此不能保存二进制数据;
- 字符串操作函数不高效且不安全,比如有缓冲区溢出的风险,有可能会造成程序运行终止;
SDS
SDS内部
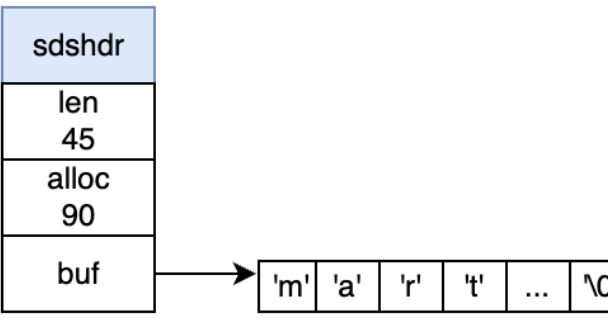
struct __attribute__ ((__packed__)) sdshd{
uint8_t len;
uint8_t alloc;
unsigned char flags;
char buf[];
}
len:记录字符串长度,时间复杂度只需要 O(1)。alloc:分配给字符数组的空间长度。这样在修改字符串的时候,可以通过 alloc - len 计算出剩余的空间大小。flags:用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64buf[]:字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。
flags:
SDS 结构中有个flags成员变量,表示的是 SDS 类型。
- sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。
- 区别:
它们数据结构中的 len 和 alloc 成员变量的数据类型不同。 - 设计的原因:
灵活保存不同大小的字符串,从而有效节省内存空间。比如,在保存小字符串时,结构头占用空间也比较少。
- 区别:
- Redis内部对于字符串的追加和长度计算是很常见的,而c语言在计算长度的复杂度为O(N),对字符串追加需要重新分配内存
- String 类型的底层的数据结构实现主要是
int 和 SDS(简单动态字符串)。SDS 不仅可以保存文本数据,还可以保存二进制数据。(SDS的所有API都会以处理二进制的方式来处理 SDS 存放在 buf[] 数组里的数据)SDS 获取字符串长度的时间复杂度是 O(1)。(len 属性记录了字符串长度)Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出。(SDS 在拼接字符串之前会检查 SDS 空间是否满足要求)- 不再以’\0’作为判断标准,二进制更安全。
- 增加空余空间(alloc-len),为后续追加数据预留余地
当判断出缓冲区大小不够用时,Redis 会自动将扩大 SDS 的空间大小,以满足修改所需的大小。
预留空间规则
- len小于1M的情况下,
alloc是len的一倍,即预留len大小的空间; - len大于1M的情况下,
alloc是1M+len,即预留1M大小的空间 - 简单说(len, 1M)
内部实现
-
字符串对象的内部编码(encoding)有 3 种 :
int、raw和 embstr。INT编码:存一个整型,可以用long表示。EMBSTR编码:字符串小于等于阈值字节,使用该编码。RAW编码:字符串大于阈值字节,使用该编码。- 该阈值在3.2版本之前是39字节,3.2版本之后是44字节。
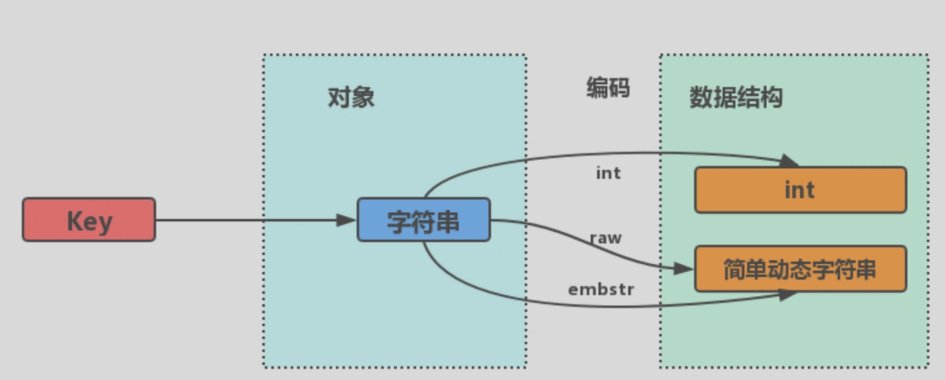
- 字符串对象保存的是
整数值,并且这个整数值可以用long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void*转换成 long),并将字符串对象的编码设置为int。

- 字符串对象保存的是
一个字符串,并且这个字符申的长度小于等于 32 字节,字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为embstr。

- 字符串对象保存的是
一个字符串,并且这个字符串的长度大于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为raw

-
embstr和raw的区别- embstr和raw都是由redisObject和SDS两个结构组成,但是
enbstr下的redisObject和SDS是连续的内存,RAW编码下redisObject和SDS的内存是分开的。 embstr会通过一次内存分配函数来分配一块连续的内存空间来保存redisObject和SDS(在emstr)raw编码会通过调用两次内存分配函数来分别分配两块空间来保存redisObject和SDS
- embstr和raw都是由redisObject和SDS两个结构组成,但是
-
embstr优点- embstr编码将创建字符串对象所需的内存分配次数从 raw 编码的两次降低为一次;
- 释放 embstr编码的字符串对象同样只需要调用一次内存释放函数;
- embstr编码的字符串对象的所有数据都保存在一块连续的内存里面可以更好的利用 CPU 缓存提升性能。
-
embstr缺点- 如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,所以
embstr编码的字符串对象实际上是只读的,当我们对embstr编码的字符串对象执行任何修改命令(例如append)时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。 embstr由于redisObject和sds是连续的,重新分配的时候需要这两个整体都分配,而raw是不连续的,所以重新分配的时候redisObject是不连续的。
- 如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,所以
-
编码转换- INT->RAW:当存的内容不再是整数,或者大小超过long的时候;
- EMBSTR->RAW:任何写操作之后EMBSTR都会变成RAW
应用场景
缓存对象
- 使用 String 来缓存对象有两种方式:
- 直接缓存整个对象的 JSON(
SET user:1 '{"name":"xiaolin", "age":18}') - 采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值(
MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20。)
- 直接缓存整个对象的 JSON(
常规计数
- 因为 Redis 处理命令是单线程,所以执行命令的过程是原子的。因此 String 数据类型适合计数场景,比如计算访问次数、点赞、转发、库存数量等等。
# 初始化文章的阅读量
> SET aritcle:readcount:1001 0
OK
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 1
> GET aritcle:readcount:1001
"1"
分布式锁
- SET 命令有个 NX 参数可以实现「key不存在才插入」,可以用它来实现分布式锁:
- 如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
- 如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
加锁
分布式锁加上过期时间
SET lock_key unique_value NX PX 10000
解锁
- 先判断锁的 unique_value 是否为加锁客户端
- 解锁
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
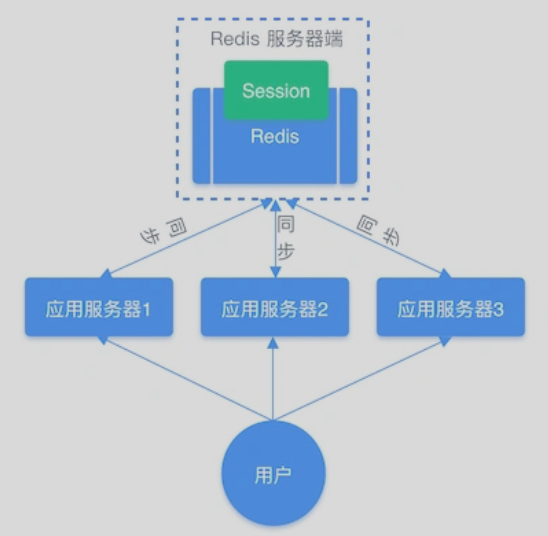
共享 Session 信息
- 借助 Redis 对这些 Session 信息进行统一的存储和管理,这样无论请求发送到那台服务器,服务器都会去同一个 Redis 获取相关的 Session 信息,这样就解决了分布式系统下 Session 存储的问题。
List
- List 列表是简单的字符串列表,按照插入顺序排序,可以从头部或尾部向 List 列表添加元素。
常用命令
# 将一个或多个值value插入到key列表的表头(最左边),最后的值在最前面
LPUSH key value [value ...]
# 将一个或多个值value插入到key列表的表尾(最右边)
RPUSH key value [value ...]
# 移除并返回key列表的头元素
LPOP key
# 移除并返回key列表的尾元素
RPOP key
# 返回列表key中指定区间内的元素,区间以偏移量start和stop指定,从0开始
LRANGE key start stop
# 从key列表表头弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞
BLPOP key [key ...] timeout
# 从key列表表尾弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞
BRPOP key [key ...] timeout
内部实现

- List 类型的底层数据结构是由双向链表或压缩列表实现的:
- 如果列表的元素个数小于 512 个(
这是由zllen记录的),列表每个元素的值都小于 64 字节。Redis 会使用压缩列表作为 List 类型的底层数据结构; - 如果列表的元素不满足上面的条件,Redis 会使用
双向链表作为 List 类型的底层数据结构;
- 如果列表的元素个数小于 512 个(
在 Redis 3.2 版本之后 List 数据类型底层数据结构就只由 quicklist 实现了,替代了双向链表和压缩列表。
ZIPLIST(压缩列表)---内存紧凑
- 压缩列表是一种排列紧凑的列表,主要做为底层数据结构提供紧凑型的数据存储方式。
- 一开始是ziplist但是对象元素超过了ziplist限制,会自动转换为linkedlist
- ziplist本身存在一个连锁更新的问题,所以Redis7.0之后,使用了listpack的编码。
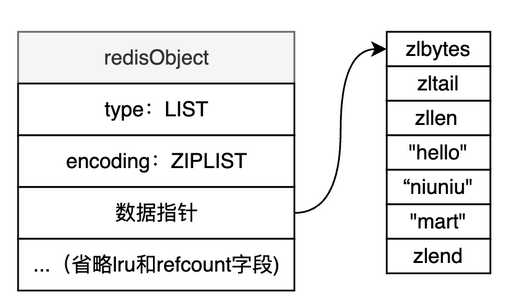
ziplist整体结构

zlbytes:表示该ziplist一共占了多少字节数,这个数字是包含zlbytes本身占据的字节的。zltail: 记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量。zllen:表示有多少个数据节点,本题中有3个。entry1~entry3:表示压缩列表数据节点。zlend:一个特殊的entry节点,表示ziplist的结束。
entry的节点结构
<prevlen> <encoding> <entry-data>
prevlen:表示上一个节点的数据长度,通过这个字段可以定位上一个节点的数据,实现从后往前操作。- 如果前一节点的长度小于254字节,那么prevlen属性 需要用1字节长的空间来保存这个长度值,否则使用5字节长的空间保存这个长度值。
encoding:编码类型。- 包括
数据的类型和数据的字节长度这两个部分。 类型主要有俩种字符串和整数。 - 读到encoding时就知道往后偏移多少能到写一个节点头部了。
- 包括
entry-data:实际的数据。类型和长度都由 encoding 决定。
prevlen
- 当往压缩列表中插入数据时,压缩列表会根据数据类型是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息。
- 这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
prevlen 和 encoding 是如何根据数据的大小和类型来进行不同的空间大小分配?
根据字符串长度:
- 压缩列表里的每个节点中的 prevlen 属性都记录了「前一个节点的长度」,而且 prevlen 属性的空间大小跟前一个节点长度值有关
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
根据字符串类型
- 如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码
- 如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1 字节/2字节/5字节的空间进行编码
ziplist查询
查询ziplist的数据总量:通常是O(1)时间复杂度,因为zllen是2个字节,当zllen大学65535时,zllen就存不下了,此时zllen就是0,然后数据总量就需要重新遍历此时就是O(N)。查询指定数据节点:需要遍历这个压缩列表,平均时间复杂度是O(N)。
ziplist更新数据
- ziplist最大的问题就是连锁更新数据导致性能不稳定。
连锁更新:新增一个节点如果该节点长度超过254则后面节点的prevlen(原本1个字节),就要变为5个字节导致后面这个节点长度也增大,如此连锁反应造成连锁更新,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。- 如果新增节点长度较小,不会造成后续prevlen节点的扩充,那么只会带来后面节点的单纯位置后移,这不属于连锁反应
压缩列表缺点
- 不能保存过多的元素,否则查询效率就会降低;
新增或修改某个元素时,压缩列表占用的内存空间需要重新分配,甚至可能引发连锁更新的问题。
LISTPACK优化
- listpack是为了解决ziplist最大的痛点-连锁更新
- 由于prevlen表示上一个节点的数据长度,通过这个字段定位上一个节点的数据,因此连锁更新是由prevlen导致的。
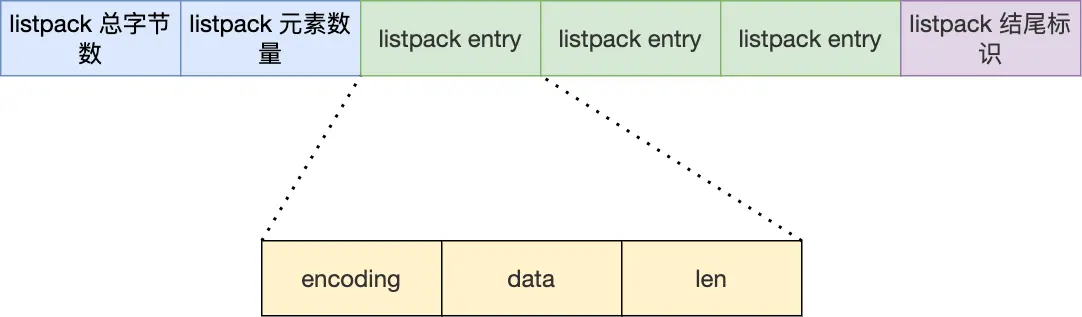
<encoding><data><len>
encoding:编码类型
data:数据内容
len:存储整个节点除它自身之外的长度。(encoding+data的总长度;)
改进点
- 存储的是自身节点的长度,不会因其他节点长度变化而变化,解决了连锁更新的问题。
- ziplist的entry是存储的是上一个节点的长度,而这里是存储自身当前节点的长度,从而解决自身改变,导致下一个节点改变,从而避免连锁更新。
找到上一个节点
- element-tot-len所占用的每一个字节的第一个bit用于标识是否结束。0代表结束,1代表继续,剩下的7个bit来存储数据大小。

LINKEDLIST(双向链表)---删除更为灵活,但是牺牲了内存
- linkedlist是双链表实现的list
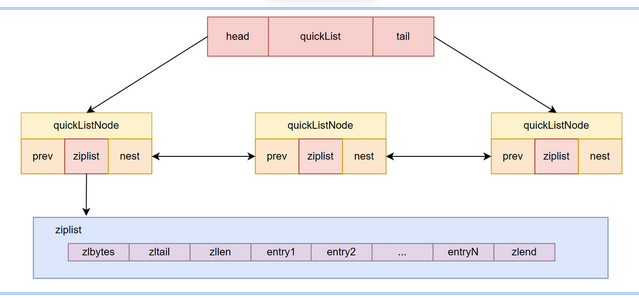
QUICKLIST=双向链表+压缩列表
quicklist 解决办法,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
- 用linkedlist主要是为了提高更新效率,ziplist数据稍微多时,插入删除数据可能会导致很多的内存复制。
- ziplist和linkedlist查询时间复杂度都是O(n)
- linkedlist是一个单个节点,只能存一个数据,现在单个节点存的是一个ziplist,即多个数据
内部结构
typedef struct quicklistNode {
//前一个quicklistNode
struct quicklistNode *prev; //前一个quicklistNode
//下一个quicklistNode
struct quicklistNode *next; //后一个quicklistNode
//quicklistNode指向的压缩列表
unsigned char *zl;
//压缩列表的的字节大小
unsigned int sz;
//压缩列表的元素个数
unsigned int count : 16; //ziplist中的元素个数
....
} quicklistNode;
应用场景
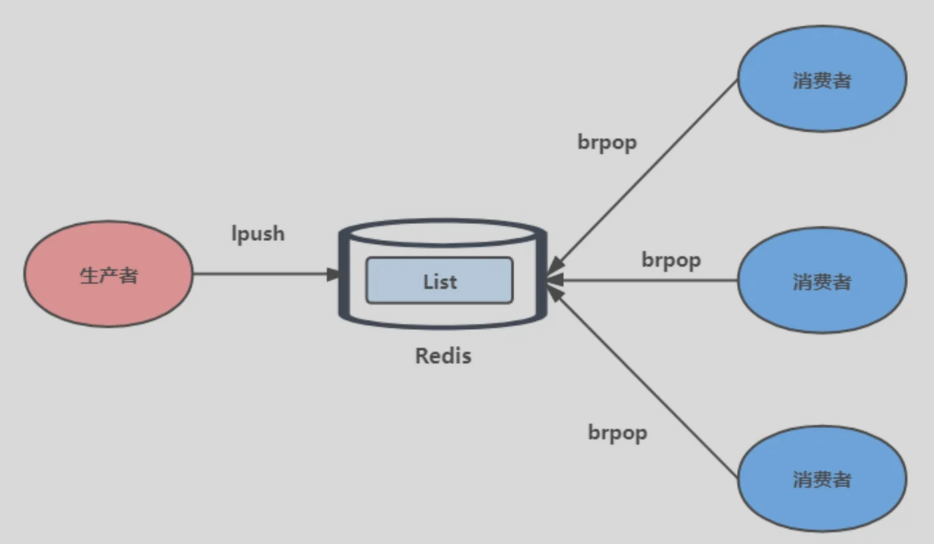
消息队列
- 消息队列在存取消息时,必须要满足三个需求,分别是
消息保序、处理重复的消息和保证消息可靠性。
1.消息保存

List 可以使用LPUSH + RPOP(或者反过来,RPUSH+LPOP)命令实现消息队列。
- 生产者使用 LPUSH key value[value…] 将消息插入到队列的头部,如果 key 不存在则会创建一个空的队列再插入消息。
- 消费者使用 RPOP key 依次读取队列的消息,先进先出。
缺点
- 当有消息送达时,List不会主动通知消费者有消息写入,消费者只能while(1)循环不断检查,有消息则返回结果,无消息返回空继续循环。
解决办法
BRPOP命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据
2.处理重复消息
- 每个消息都有一个全局的 ID。
- 消费者要记录已经处理过的消息的 ID。(将已处理的ID和要处理的ID对比)
但是 List 并不会为每个消息生成 ID 号,所以我们需要自行为每个消息生成一个全局唯一ID,生成之后,我们在用 LPUSH 命令把消息插入 List 时,需要在消息中包含这个全局唯一 ID。
> LPUSH mq "111000102:stock:99"
(integer) 1
3.保证消息可靠性
消费者程序在处理消息的过程出现了故障或宕机,就会导致消息没有处理完成,那么,消费者程序再次启动后,就没法再次从 List 中读取消息了。
- List 类型提供了
BRPOPLPUSH命令,这个命令的作用是让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息再插入到另一个 List(可以叫作备份 List)留存。
总结
- 消息保序:使用
LPUSH + RPOP; - 阻塞读取:使用
BRPOP; - 重复消息处理:生产者自行实现全局唯一 ID;
- 消息的可靠性:使用
BRPOPLPUSH
4.List做消息队列缺陷
- List 不支持多个消费者消费同一条消息,因为一旦消费者拉取一条消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费。
- 要实现一条消息可以被多个消费者消费,那么就要将多个消费者组成一个消费组,但是 List 类型并不支持消费组的实现。而新类型
Stream支持消费组形式的消息读取。
总结
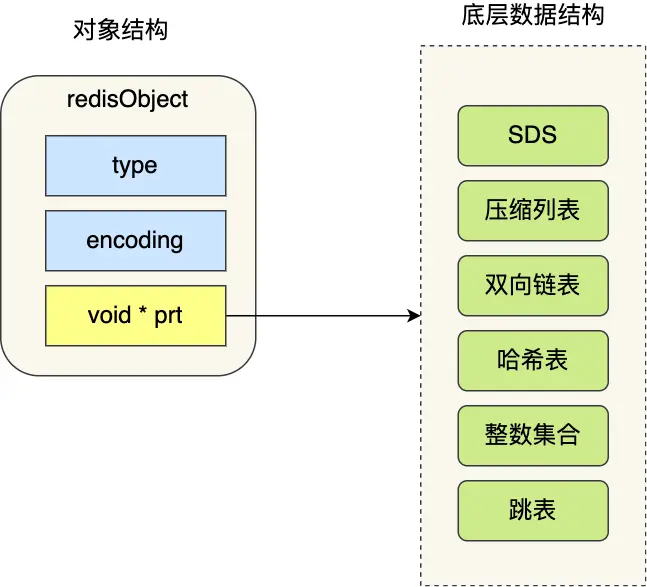
所有类型底层数据结构

Redis 键值对数据库的全景图

原文来自https://www.xiaolincoding.com/redis/data_struct/command.html#%E5%BA%94%E7%94%A8%E5%9C%BA%E6%99%AF-2
















 1118
1118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











