






simple_Webserver
它是个什么项目?——Linux下C的简易的多并发的Web服务器,通过输入网址可以浏览本地主机的所设置的工作路径的目录及文件,助力初学者快速实践网络编程,搭建属于自己的服务器。
- 使用了 epoll+信号处理+守护进程+多线程的并发模型。
- 目前仅支持解析HTTP的GET请求行
- 未来将参考github有名的项目:TinyWebServer来改进该项目
- 本地环境:阿里云服务器linux
- 经Webbench压力测试可以实现上万的并发连接数据交换
压力测试图结果放在多线程优化中。
注意:要开始这个项目,需要对linux编程、网络编程有一定的了解,这方面书籍推荐《Unix网络编程》
Web服务器开发流程分析
整体项目分为两个部分:
- 第一个部分是通用的epoll的服务器开发部分。
- 第二个部分是处理客户端请求。
- 通用的epoll的服务器开发部分流程如下图所示:
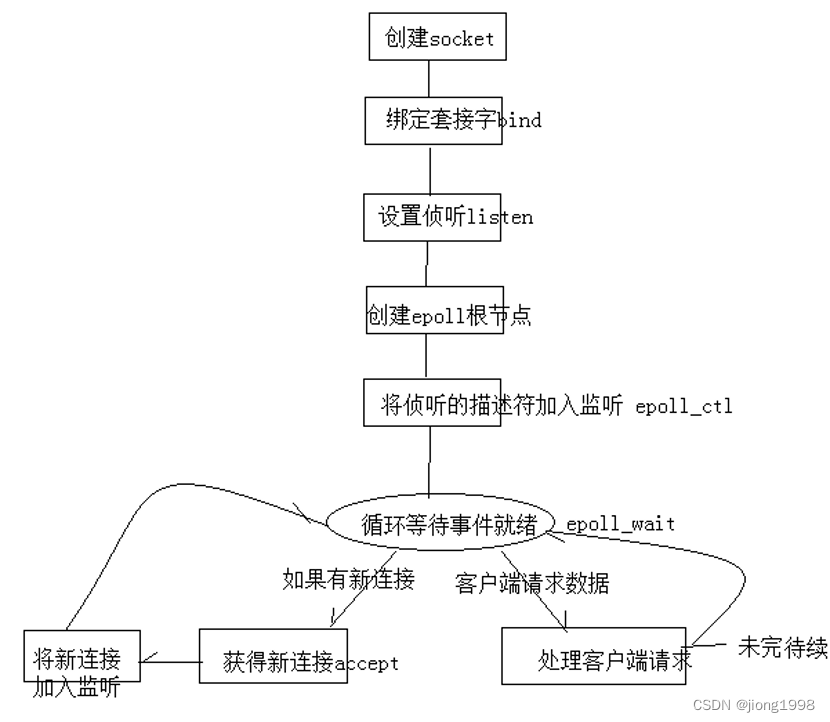
epoll的三个函数:
- epoll_create----创建树根
- epoll_ctl----添加, 删除和修改要监听的节点
- epoll_wait----委托内核监控
注意:在浏览器关闭连接时,记得下树。
- 处理客户端请求部分流程如下图所示:
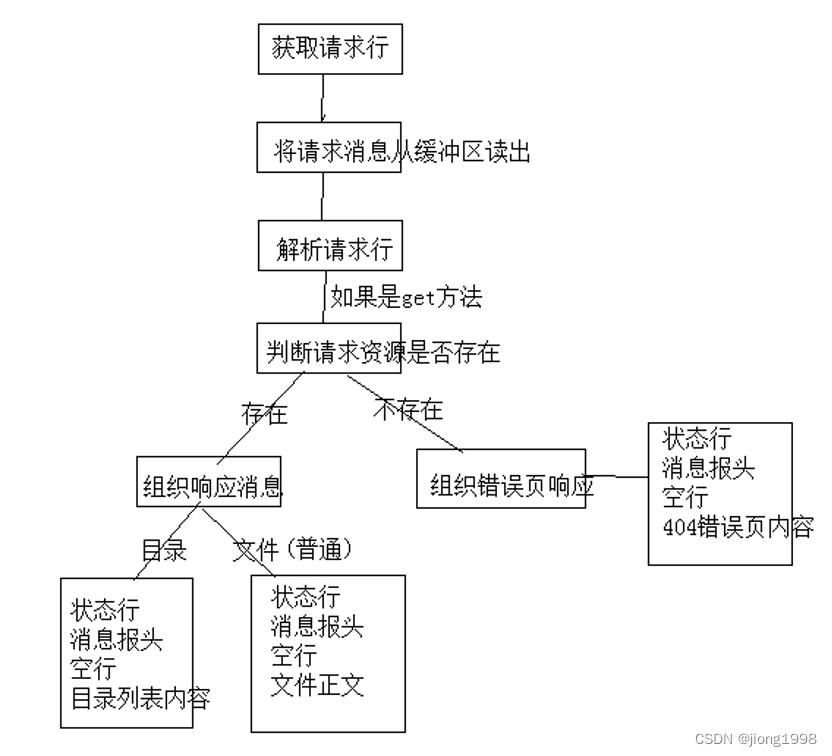
处理客户端请求的流程:
int http_request(int cfd)
{
//读取请求行
Readline();
//分析请求行,得到要请求的资源文件名file
如:GET /hanzi.c /HTTP1.1
//循环读完剩余的内核缓冲区的数据,不然数据还会留在缓冲区
while((n = Readline())>0);
//判断文件是否存在
stat();
1文件不存在
返回错误页
组织应答信息:http响应格式消息+错误页正文内容(作实体体)
2文件存在
判断文件类型:
普通文件
组织应答信息:http响应格式消息+文件正文(作实体体)
目录文件
组织应答消息:http响应格式消息+html格式文件正文(作实体体)
}
Web服务器开发问题具体分析:
1. 浏览器请求的文件分析
在前面的流程分析中,我们已经知道:我们先根据浏览器发送过来的http请求报文的请求行来获取浏览器请求的内容:
- 如果请求的文件不存在,则首先直接返回错误信息的响应报文的前三个部分,然后再返回一个提前做好的错误页面(该部分为实体体,下面都同理)。
- 如果请求的文件为普通文件则处理起来很简单,首先直接返回正确信息的响应报文的前三个部分,再传输对应的文件(从磁盘中读取文件数据,然后发送到connfd)
- 如果请求的文件为目录,则处理起来比较麻烦。具体来说:首先直接返回正确信息的响应报文的前三个部分,然后再发送提前做好的html文件头部信息,其次根据scandir函数获取当前目录下的所有文件名,根据获取到的当前路径下的所有文件名发送html的中间部分(超链接的形式,作为htm格式的数据的一部分),该函数如下所示。最后发送提前做好的html文件尾部信息。这样发送给浏览器的响应数据为一个完路的html文件格式。
sprintf(buffer, "<li><a href=%s/>%s</a></li>", namelist[num]->d_name, namelist[num]->d_name);
2. 工作目录问题
web服务器程序名启动的时候所在的目录为其工作目录,我们需要使用chdir函数将工作目录调整到对应的目录上。
//改变工作路径
chdir("./web");
//检查工作路径
char buf[80];
getcwd(buf,sizeof(buf));
printf("current working directory: %s\n", buf);
3. 信号SIGPIPE问题
考虑具体的场景:浏览器关闭了与服务器的连接,而如果此时web服务器正在给浏览器发送数据,就会导致内核会给服务器端发送SIGPIPE信号,而SIGPIPE信号的默认处理动作是终止进程。而终止服务器这不是我们想要看到的,因此需要捕获SIGPIPE信号,并设置为SIG_IGN(忽略该信号)。
具体
//使用signal函数版本
signal(SIGPIPE, SIG_IGN);
//使用sigaction函数版本
struct sigaction act;
act.sa_handler = SIG_IGN;
sigemptyset(&act.sa_mask);
act.sa_flags = 0;
sigaction(SIGPIPE, &act, NULL);
注意:如果希望项目是可移植的,建议使用sigaction函数。
4. connfd改为非阻塞模式
为什么connfd要改为非阻塞模式?
当我们获取到http发送的请求报文时,我们仅需要第一行的请求行,剩下的部分我们并不需要,而我们又需要读完它避免粘包(上一次连接的数据影响到下一次的连接,导致下一次的连接请求发生错误)。所以需要使用循环来读。代码如下:
while((n=Readline(connfd, buf, sizeof(buf)))>0);
而循环读完缓冲区数据后,Readline函数会阻塞等待缓冲区的数据到来,所以将connfd设置成非阻塞。
5. 解析http请求报文的请求行
例如,请求行为:GET /hanzi.c HTTP/1.1
利用sscanf函数以及正则表达式
char buf[1024];
sscanf(buf, "%[^ ] %[^ ] %[^\r\n]", reqType, fileName, protocal);
其中,代码的[^ ]表示遇到空格就结束。
6. 在浏览器中的每一次访问都是个独立的访问,与上一次的访问没有关系,这一点是需要注意的
7.粘包现象
两个解决思路
- 设置connfd为非阻塞,循环读,每次读判断是否n=0
- 利用select的超时特性,检查select的返回值(存疑,个人实验没解决,先保留,参考博客:https://blog.csdn.net/AnonymKing/article/details/86216415?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-86216415-blog-7577124.pc_relevant_multi_platform_whitelistv3&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-86216415-blog-7577124.pc_relevant_multi_platform_whitelistv3&utm_relevant_index=1)
8.优化:多线程
参考之前写过的多线程服务器代码 https://github.com/jiong1998/unix_socket.io/issues/3
将单线程改为多线程,具体来说
//2、客户的数据到
else
{
connfd = event[i].data.fd;
http_request(connfd, epfd);
}
在原本单线程的代码中,客户请求连接和请求数据都是由一个主线程搞定的,在多线程版本中,由子线程完成 浏览器对数据的请求。
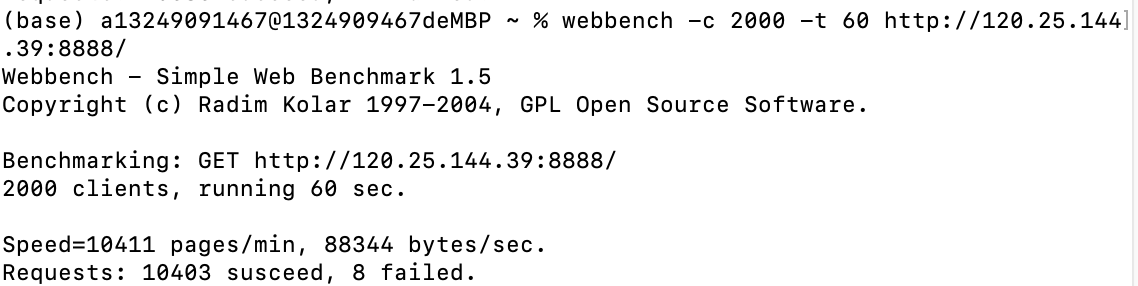
经Webbench压力测试, 多线程版本下的性能比单线程版本的性能提升了十倍以上!
多线程的epoll的压力测试结果:
测试参数:webbench -c 2000 -t 60 http://120.25.144.39:8888/
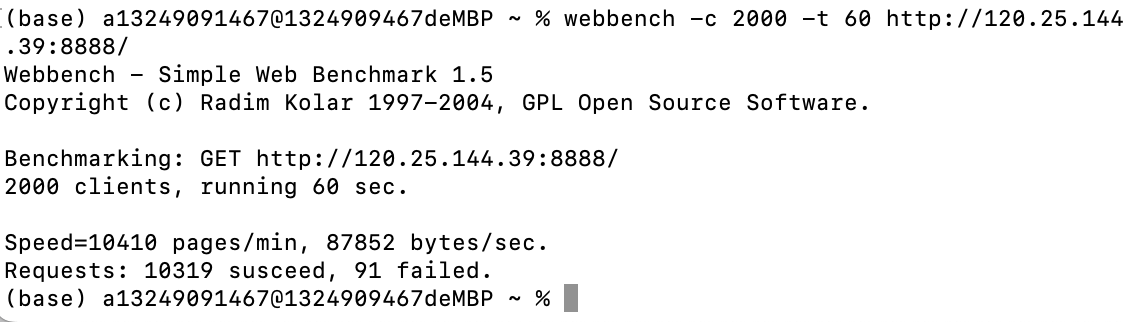
单线程的epoll的压力测试结果:
.改为守护进程
最后,其实了解原理后,epoll可以很轻松的换select/poll/甚至是libevent的网络框架。笔者只做了epoll和poll的版本,经过对比,很轻易的可以看出 epoll的效率要远高于 poll。
存在的问题及缺陷
对于大文件的浏览还是存在速度过慢的问题。















 2002
2002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









