







一、简介
Hudi是Uber公司开源的数据湖架构,它是围绕数据库内核构建的流式数据湖。
Hudi设计文件存储和管理,数据模型有2种:COW和MOR
基本使用:
- hudi底层的数据可以存储到hdfs
- hudi的数据文件是parquet列式存储
- hudi可以使用spark/flink 来消费 kafka消息队列的数据
- hudi先将数据处理为 hudi 格式的 row tables (原始表),然后原始表被 Incremental ETL (增量处理)生成一张 hudi 格式的 derived tables(派生表)
- hudi 支持的查询引擎有:hive、impala、spark等
支持 spark、flink、map-reduce 等计算引擎继续对 hudi 的数据进行再次加工处理
二、数据存储结构
Hudi表的数据文件,一般使用HDFS进行存储。在HDFS种,一个Hudi表的存储文件分为两类。
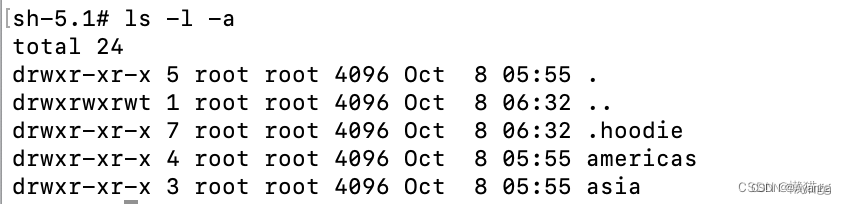
- .hoodie文件夹:存储文件合并操作的日志文件(每一次数据操作都会生成一个文件,这些文件会被陆续合并)
- amricas和asia相关路径:存储实际的数据文件,按分区存储,分区的路径key可以指定
- Hudi把随着时间流逝,对表的一系列CRUD操作叫做Timeline(Timeline来解决因为延迟造成的数据时序问题),Timeline中某一次的操作,叫做Instant。Instant包含Instant Action(数据提交COMMITS、文件合并COMPACTION、文件清理CLEANS),Instant Time(本次操作发生的时间),State(操作的状态:发起REQUESTED、进行中INFLIGHT、已完成COMPLETED)
三、数据模型
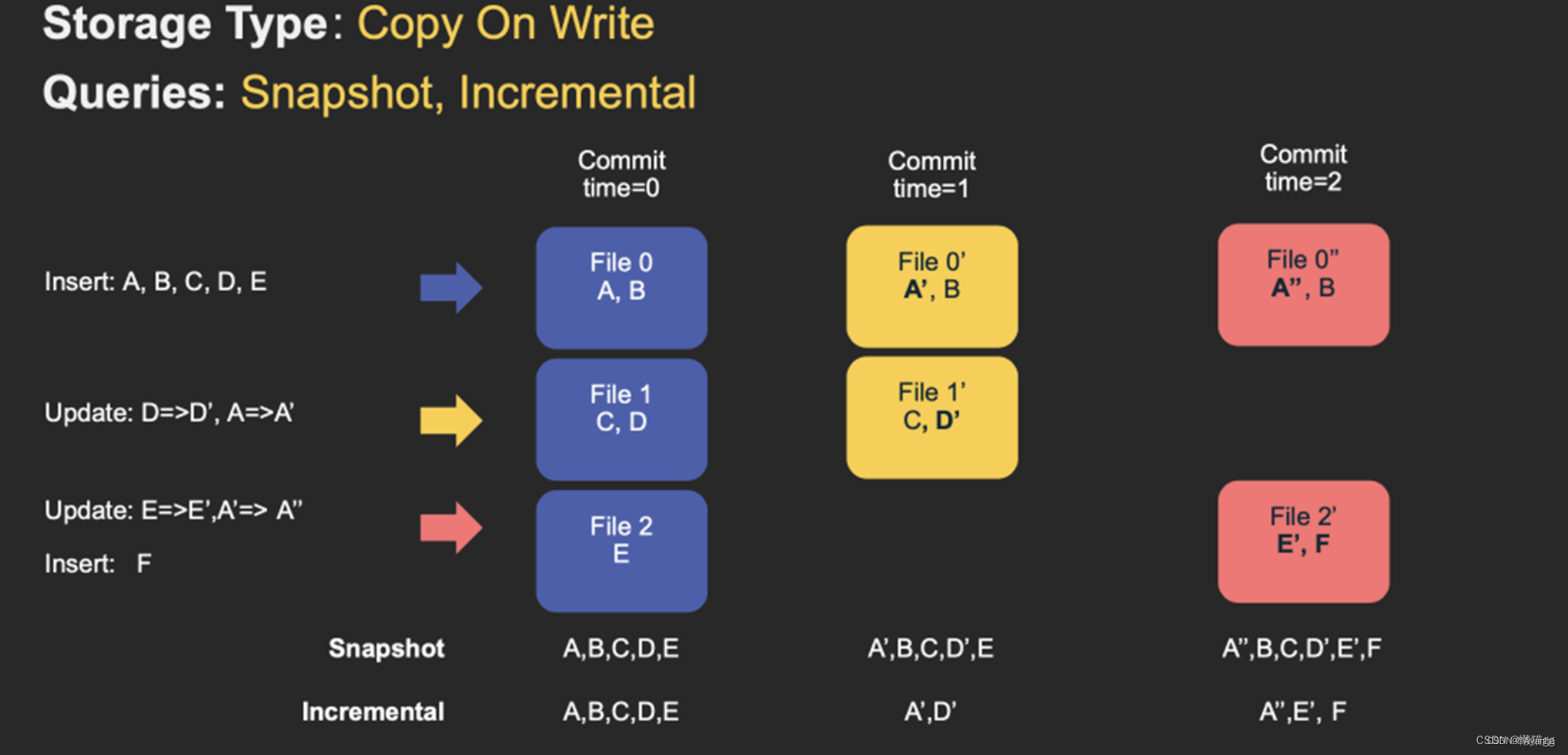
COW
写时复制Copy on Write,它是在数据写入的时候,复制一份原来文件作为拷贝,在拷贝文件上更新或添加新数据,这个拷贝文件就只包含最新的数据了。
COW表主要使用 列式文件格式(Parquet) 存储数据,在写入数据过程中,执行同步合并。
MOR
读时合并Merge On Read,新插入的数据存储在delta log 中,定期再将delta log合并进行parquet数据文件。
读取数据时,会将delta log跟老的数据文件做merge,得到完整的数据返回。
MOR表使用 列式(parquet)与行式(avro) 文件混合的方式存储数据。
在 READ OPTIMIZED 模式下,正在读数据的请求,读取的是最近建立的副本文件,即最新的合并数据。
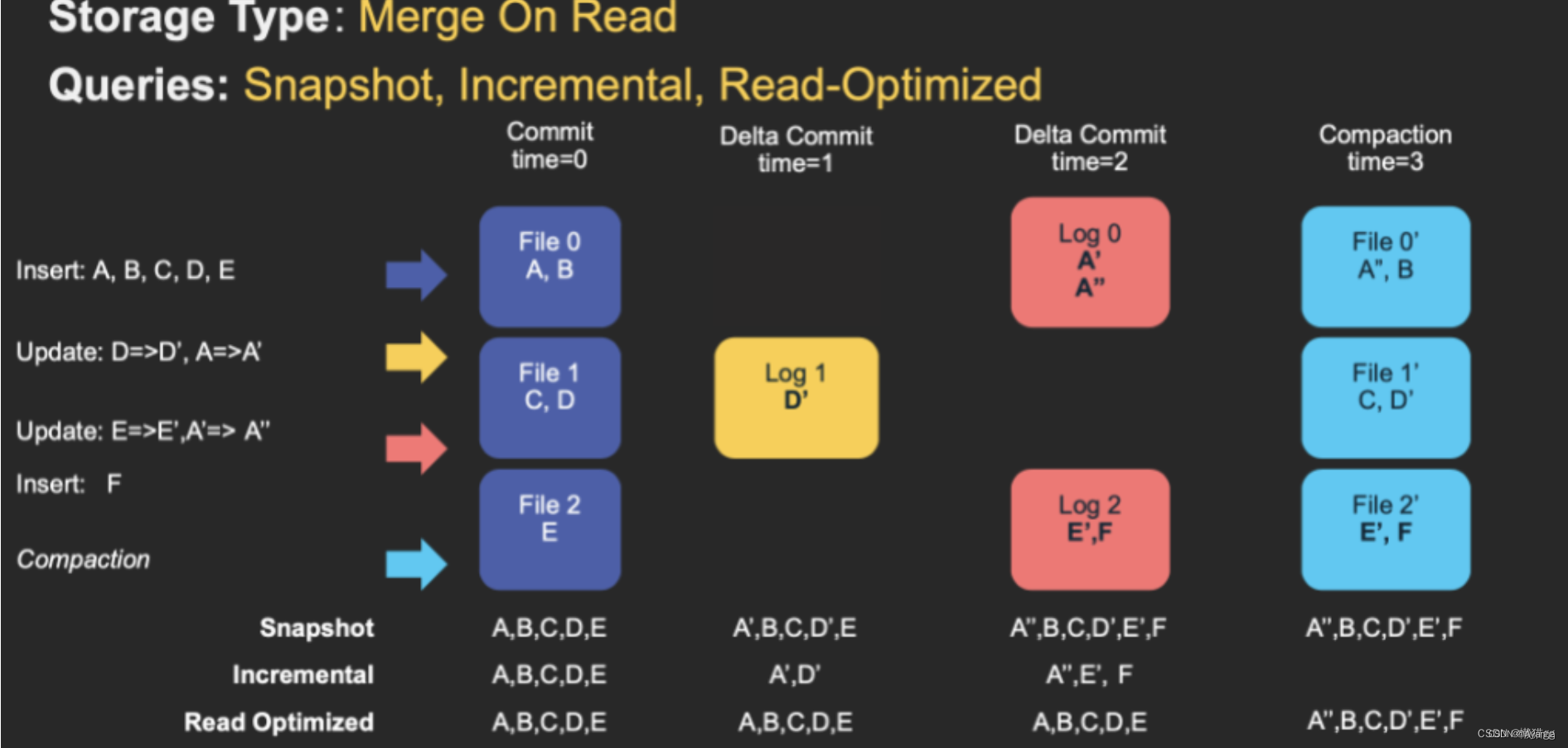
Hudi查询
- Snapshot Queries(快照查询)
动态合并最新的文件,提供实时数据 - Incremental Queries(增量查询)
仅查询新写入数据集的文件,需要指定一个Commit/Compaction的即时时间(位于Timeline上的某个instant)作为条件,来查询此条件之后的新数据 - Read Optimized Queries(读优化查询)
直接查询数据集的最新快照,提供离线数据














 1522
1522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









