






本文首次提出将Attention机制用于图神经网络,代替之前相关GCN工作中的频域方法:基于谱域的拉普拉斯特征值分解(计算开销大,没有空域意义上的滤波性);基于空域的方法:直接聚合图节点的邻居节点。以上方法存在的问题是:谱域的方法计算开销大,空域的方法很难在不同数量的邻居节点间像CNN的卷积那样具有权重共享的性质。
本文提出的注意力机制结构有三个有点:①计算开销小 ②可以通过给邻居节点不同的权重来处理任意度的节点 ③ 可以用于解决归纳学习问题
文章中的公式说明和推导:
首先用![]() 来表示每个节点的特征向量,
来表示每个节点的特征向量,![]() 表示节点 j 对 i 的重要性,其中W是共享的权重参数大小是:(node_size,node_size),a也是可以学习的参数,它通常是一个向量,在本文的代码实现中它的大小为:(2*hidden_size,1)。然后计算注意力系数:
表示节点 j 对 i 的重要性,其中W是共享的权重参数大小是:(node_size,node_size),a也是可以学习的参数,它通常是一个向量,在本文的代码实现中它的大小为:(2*hidden_size,1)。然后计算注意力系数:![]() 它的意思是求得每个节点之间的注意力重要性(有些没有连接的节点也计算上了)做softmax归一化。最后写开了的公式:
它的意思是求得每个节点之间的注意力重要性(有些没有连接的节点也计算上了)做softmax归一化。最后写开了的公式:
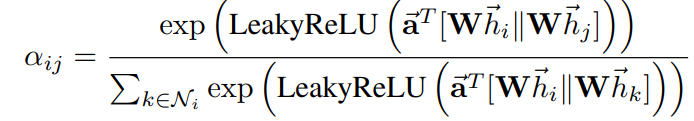
在代码里hi和hj其实都是一样的输入特征矩阵,它们分别乘以a,a的左半部分(hidden_size,1)和右半部分是不同的参数,这样就可以分别得到 i 对 j 的重要性和 j 对 i 的重要性,将其相加最后做LeakyReLU。在代码中由于不是所有节点都是两两相连,所以在计算完αij之后需要用邻接矩阵的信息来只获取分别相连节点的注意力值。
最后计算输出:![]()
文章还提出了多头注意力的概念,具体来说就是将原来的可学习参数a扩展到k个,最后将每个输出h cat起来。再经过一个MLP层融合信息得到输出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









