







知识点一、首先介绍的是inline的用法,它的特性介绍是这样子的
1.inline是一种以空间换时间的做法,省去调用函数额开销。所以代码很长或者有代码比较长 递归的函数适宜使用作为内联函数。
2.inline对于编译器而言只是一个建议,编译器会自动优化,如果定义为inline的函数体代码比较长 / 递归等等,编译器优化时会忽略掉内联。
3.inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
有如下代码进行对比,这是一个交换变量的函数
void swap_c(int& pl, int& p2)
{
int tmp = pl;
pl = p2;
p2 = tmp;
}
//一般内联适用于小函数,小于20-30行
inline/*空间换时间的方法*/ void swap_c(int pl, int p2)
{
int tmp = pl;
pl = p2;
p2 = tmp;
}当没有使用内联函数的时候在运行过程中,走到函数之后会找到函数的声明再对函数进行调用,
如果当函数调用过多的情况下,会开辟很多的内存空间引起不必要的消耗,所有有了内联函数。
在内联函数inline中当程序运行是,内联函数会直接在程序内进行展开,从而减少了堆栈的消耗以达到空间换时间的方法,多次调用会多次展开

一般内联函数适用于小函数,小于20-30行,一旦超出在预编译的时候还是会变成调用正常函数。
知识点二、auto的作用以及用法
auto简介
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它,大家可思考下为什么?
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型
指示符来指示编译器,auto明的变量必须由编译器在编译时期推导而得
int main()
{
int a = 10;//int 这里定义a的int类型
auto b = a; //int 而b的类似是根据a的类型推导出来的
auto& c = a;//int
auto& d = a;//int
auto* e = &a;//int *
auto f = &a;//int *
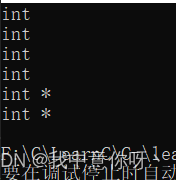
}我们用c++中的函数typeid.name可以检测他们的类型
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
cout << typeid(e).name() << endl;
cout << typeid(f).name() << endl;下面结果和上面定义对应出来如下
而在使用auto的过程中有一些需要注意的地方
一、在同一行定义多个变量
auto c = 3, d = 4.0;// 该行代码会编译失败,因为c d初始化表达式类型不同
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第
一个类型进行推导,然后用推导出来的类型定义其他变量二、auto声明数组
int a[] = { 1,2,3 };
auto b[] = { 4,5,6 };//auto不能直接用来声明数组三,作为参数类型
TestAuto(auto a);
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a实际类型进行推导以上是在使用auto的过程中需要注意的地方
知识点三、for在C++中有了更加简洁的用法,这里就不过多赘述,一看便知,迭代器用法。
int main()
{
int array[] = { 1,2,3,4,5 };
//C语言中的做法
for (int i = 0; i < sizeof(array) / sizeof(int); i++)
{
array[i] *= 2;
}
for (int i = 0; i < sizeof(array) / sizeof(int); i++)
{
cout << array[i] << " ";
}
cout << "C语言"<<endl;
//C++11 -> 范围for
for (auto& e : array)//引用
{
e *= 2;
}
for (auto e : array)
{
cout << e << " ";
}
cout <<"C++ 11" << endl;
}但是需要注意的点是不能像下面这样子用,这样是有问题的,因为在函数中接收的array实际上是第一个参数的地址所以这个地方一定需要注意。
void TestFor(int array[])
{
for (auto e : array)
{
cout << e << " ";
}
}知识点四、nullptr的作用及用法
咱们用下面这段代码的运行结果给大家演示看看运行结果是什么样的
void fun(int n)
{
cout << "整型" << endl;
}
void fun(int* p)
{
cout << "整型指针" << endl;
}
int main()
{
//C
int* p = NULL;
//C++ 11 中,推荐像下面这样去用
int* p2 = nullptr;
fun(0); //整型
fun(NULL); //整型 //预处理后的fun(0);
fun(nullptr); //整型指针 //fun((void*)0);
return 0;
}
运行后p2为指针类型,却输出的是整型,就是因为NULL实际是一个宏,在传统的C文件(stddef.h中,可以看到如下代码:
#ifndef NULL
#ifdef___cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL定义成0,因此与程序的初衷相悖。
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下
将且看成是一个整形常量,如里要将其按照指针方式来使用,必须对其进行强转(void)0。
所以大家以后在c++是使用指针的时候需要注意以下几点。
1.在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
2.在C++11中,sizeof(nullptr)与sizeof((void*)0)所占的字节数相同。
3.为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
如果有帮助的话记得点个赞,谢谢!

















 2303
2303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











