









XPath——全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言。它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。所以在爬虫里就可以直接使用Xpath来进行数据获取,而且方法相较于正则表达式和bs4等要简单很多。
工程中常用Python的lxml库,利用XPath进行HTML的解析。
安装库
pip3 install lxml
导入
from lxml import etree
Xpath的常用规则
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点(绝对路径) |
| // | 从当前节点选取子孙节点(相对路径) |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
Xpath的基本语法
XPath 基础表达式
| 表达式 | 描述 |
|---|---|
| /node | 表示在xml文档的根目录查找结点名称为node的结点 |
| ./node | 表示在当前结点下查找结点名称为node的结点 |
| //node | 表示在xml文档中递归查找结点名称为node的节点 |
| //* | 表示在xml文档中查询所有的结点,但是排除文本节点 |
| //node() | 表示在xml文档中查询所有结点,包含文本节点 |
| //text() | 表示在xml文档中递归查找所有的文本节点 |
| //*/text()[contains(., ‘test’)] | 表示在xml文档中递归查找所有结点,条件为该结点的文本节点包含"test" |
| //node[@id] | 表示在xml文档中递归查找结点名称为node的结点,条件为该结点必须含有id属性 |
| //node[id] | 表示在xml文档中递归查找结点名称为node的结点,条件为该结点必须含有结点名称为id的结点 |
| //nodes[node/id] | 表示递归查找nodes结点,条件为nodes结点下必须有node结点,且node结点下必须有id结点 |
| //nodes[@id]/node[id] | 表示递归查找含有id属性的nodes结点下的node结点,条件为node结点下必须含有id结点 |
| //nodes[@id]/node[0] | 表示递归查找含有id属性的nodes结点下的第一个node结点 |
| //nodes[@id]/node[last()] | 表示递归查找含有id属性的nodes结点下的最后一个node结点 |
| //nodes/node[position() < 4] | 表示递归查找nodes结点下索引小于4的node结点 |
| //nodes[@id]/node[position() < last()] | 递归查找含有id属性的nodes结点下除最后一个结点外的node结点 |
| /nodes/child::node()[name()=‘node’] | 表示查找nodes结点下结点名称为node的子结点 |
| /nodes/child::node | 等同于/nodes/node表示查找nodes下的node子结点 |
| /nodes/node/attribute::id | 等同于/nodes/node/@id表示查找nodes结点下的node结点的id属性 |
| //nodes[@id=‘1001’]/node[starts-with(@id, ‘1’)] | 表示查找id属性为1001的nodes结点下的id属性以1开头的node结点 |
| //@*[ends-with(., ‘1’)] | 表示查找以1结尾所有属性 |
| (//* | //@*)[substring(name(), 1, 5) = ‘class’] 查找所有结点名称或属性名称的1到5之间的字符等于’class’的结点 |
| //node[@attr!=’-2’ and @attr!=‘2’] | 查找所有node节点,其attr属性不等于2和-2 |
XPath 文档轴用途:
| 表达式 | 描述 |
|---|---|
| self | 选择当前节点 |
| parent | 选择当前节点的父节点 |
| child | 选择当前节点的所有子节点 |
| attribute | 选择当前节点的所有属性 |
| ancestor | 选择当前节点的所有祖先,包括父节点、父节点的父节点等等 |
| ancestor-or-self | 选择当前节点的祖先以及当前节点本身 |
| descendant | 选择当前节点的所有后代,包括子节点、子节点的子节点等等 |
| descendant-or-self | 选择当前节点的后代以及当前节点本身 |
| preceding | 选择整个文档中出现在当前节点前面的所有节点 |
| preceding-sibling | 选择文档中出现在当前节点前面的所有同胞节点(即与当前节点同级的节点) |
| following | 选择整个文档中出现在当前节点后面的所有节点 |
| following-sibling | 选择文档中出现在当前节点后面的所有同胞节点(即与当前节点同级的节点) |
| namespace | 选择当前节点的所有名称空间节点 |
实例展示-豆瓣电视剧
豆瓣电视剧这个网页比较特殊,是由动态页面+静态所组合的,可以看到在打开的初始网页中有个“加载更多”的选项
哦吼,熟悉的动态网页,那就要在网页检查中找到他的真正网址
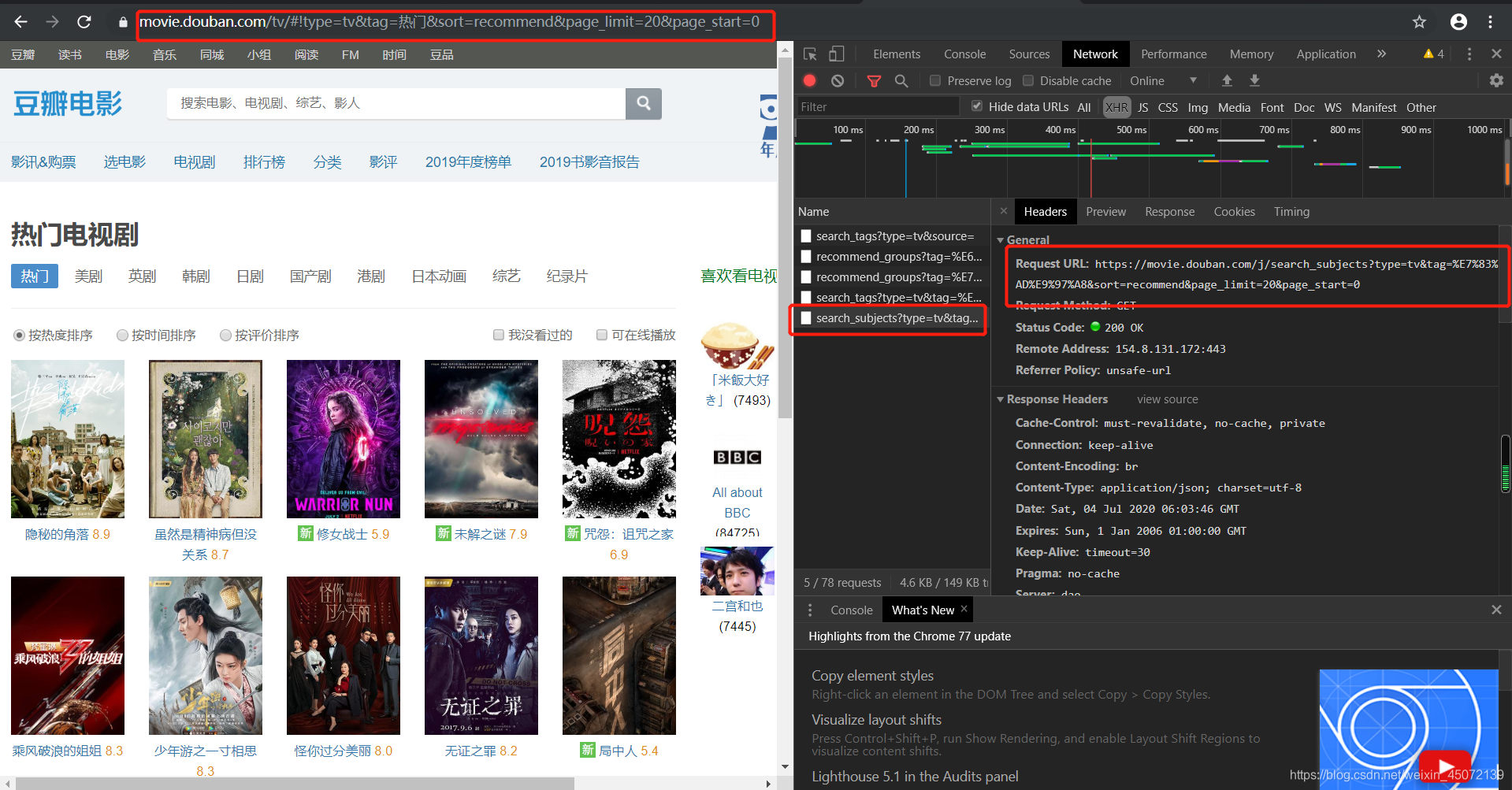
通过网址我们找到了真正的网址信息,发现这一页所有的电视剧信息都保存在Request URL后面的这个网址中,打开这个网址可以看到我们所需的详细网址也在这个页面中,即每一个电视剧的详情页,所以我们决定对该网址进行请求来获取数据。
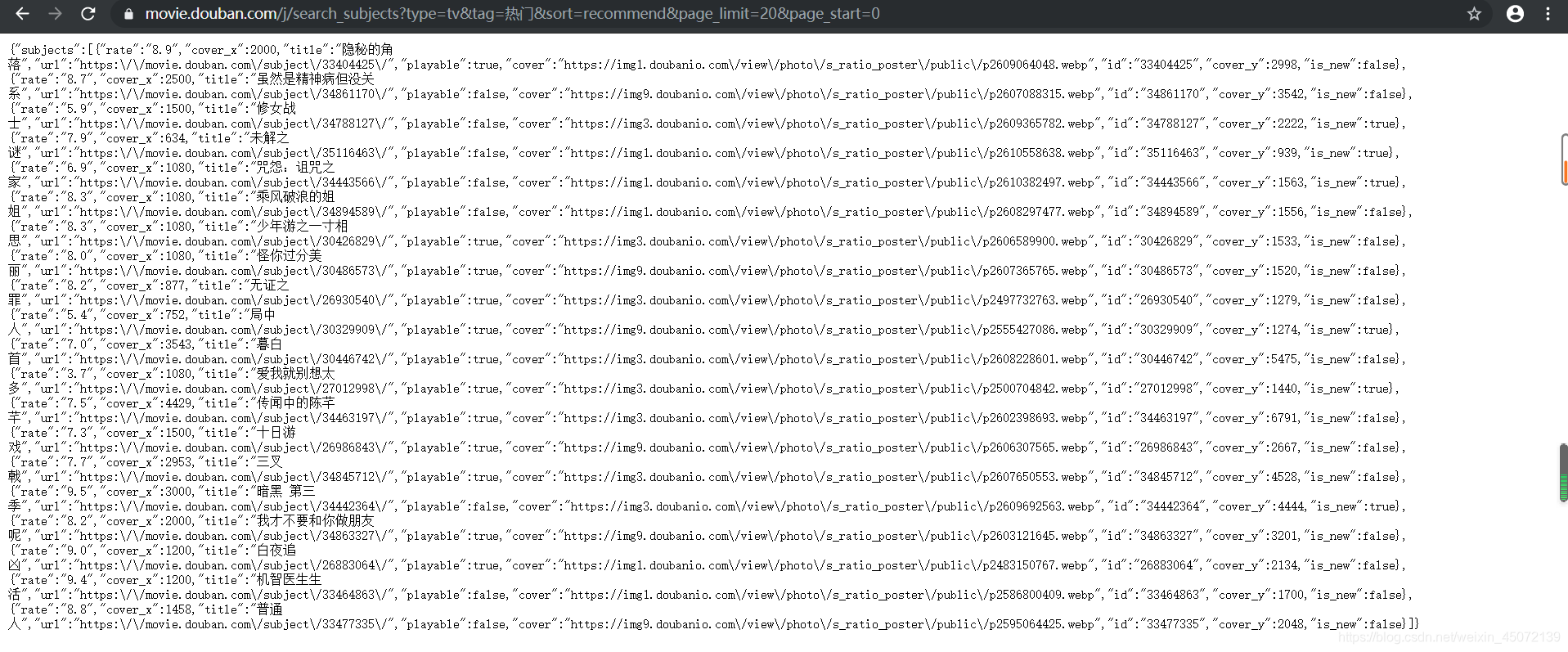
说那么多其实用的就一点点,并且使用谷歌浏览器的童鞋可能已经发现了,右键在想获取的信息上时,是可以直接copy所需信息的xpath,这。。不香吗?
但是有的时候也会发现复制下来的xpath并不准确,或是获取不到我们所需的完整信息,所以学习xpath对于爬虫也是非常重要的。
话不多说,开始上代码。
目标网址:https://movie.douban.com/tv
工具:Python3.7
环境:win10
import requests
import pandas as pd
from lxml import etree
import json
url='https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0'
#代理ip
proxies = {'http': '1.85.5.66',}
#设置headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36X-Requested-With: XMLHttpRequest'}
response=requests.get(url,headers=headers,proxies=proxies) #请求
print(response.status_code) #查看响应体,如果输出200就表示网页请求成功
response.encoding = 'utf-8'
html = response.json() # 将json格式的字符串转为python数据类型
html1=html['subjects'] #数据存放在subjects中,所以将他提取出来
#每一个电视剧的详细页网址在subjects中,所以需要从subjects中将url提取出来
url=[]
for one in html1:
url.append(one['url'])
print(url)
这样就获得了每个电视剧详情页的网址,这段代码所得到的结果是这样的:

可以看到采集到的详情页网址被保存在了列表里,所以接下来就是对这些详情页进行请求获取详我们需要的细信息,也就要用到xpath的方法。
title=[]
jianj=[]
juqing=[]
otherlike=[]
fen=[]
watch=[]
for i in range(len(url)):
res=requests.get(url[i],headers=headers,proxies=proxies)
html = etree.HTML(res.text)
title.append(''.join(html.xpath('//*[@id="content"]/h1/span/text()')))
jianj.append(''.join(html.xpath('//*[@id="info"]/span/text()')))
juqing.append(''.join(html.xpath('//*[@id="link-report"]/span/text()')))
otherlike.append(''.join(html.xpath('//*[@id="recommendations"]/div/dl/dd/a/text()')))
fen.append(''.join(html.xpath('//*[@id="interest_sectl"]/div/div[2]/strong/text()')))
watch.append(''.join(html.xpath('//*[@id="content"]/div[2]/div[2]/div[1]/ul/li/a/text()')))
columns={'剧名':title,'简介':jianj,'剧情':juqing,'还喜欢':otherlike,'评分':fen,'观看':watch}
df=pd.DataFrame(columns)
df.head()
得到的数据如下:

Xpath应该是我目前用到的最简单的爬虫方法了,如果以后遇到更简单的再继续和大家分享哦O(∩_∩)O














 2446
2446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









