







前言
本文来自2022的CVPR。
这篇论文由字节跳动和中国科学院先进院技术研究院共同完成
图像超分辨率的目的是从相应的低分辨率(low-resolution,LR)输入构建高分辨率(high-resolution,HR)图像。
一、摘要
GCFSR: 不借助人脸先验,一种生成细节可控的人脸超分方法
人脸超分辨通常依靠面部先验来恢复真实细节并保留身份信息。在 GAN piror 的帮助下,最近的进展可以取得令人印象深刻的结果。他们要么设计复杂的模块来修改固定的 GAN prior,要么采用复杂的训练策略来对生成器进行微调。作者提出了一种生成细节可控的人脸超分框架,称为 GCFSR,它可以重建具有真实身份信息的图像,而无需任何额外的先验。
GCFSR 是一个编码器-生成器架构。为了完成多个放大倍率的人脸超分,设计了两个模块:样式调制和特征调制模块。风格调制旨在生成逼真的面部细节;特征调制会根据条件放大倍率对多尺度编码特征和生成特征进行动态融合。该架构简单而优雅,可以用端到端的方式从头开始训练。
对于较小倍率超分(<=8倍),GCFSR 可以在仅有的 GAN loss 的约束下产生令人惊讶的好结果。在添加 L1 loss 和 perceptual loss 后,GCFSR 可以在大倍率超分任务上(16, 32, 64)达到 sota 的结果。而在测试阶段,我们可以通过特征调制来调节生成细节的强度,通过不断改变条件放大倍率来实现各种生成效果。
code: https://github.com/hejingwenhejingwen/GCFSR
二、创新点
1.不使用GAN prior
本文首先比较GLEAN、GFPGAN、GPEN三种有名的人脸超分模型
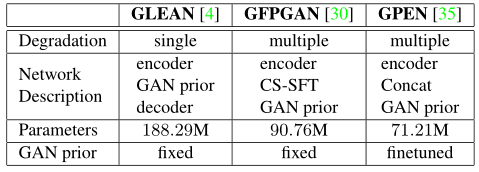
GLEAN:GLEAN利用RRDBNet进行特征提取,然后将固定的GAN先验与一个额外的解码器结合起来,生成最终的输出。
GFPGAN:采用额外的UNet,用L1损失训练来去除退化,然后将Unet中的特征转化为缩放和移动操作的参数,这些参数将用于修改固定GAN先验。
GPEN:GPEN直接将编码器和GAN先验的特征连接起来。由于串联操作给GAN先验引入了新的参数,GPEN给GAN先验一个小的学习率以进一步微调。
因为先验,前两者在刚开始训练时就可以达到很好的性能(有点像迁移学习),后者收敛缓慢,性能较差。
绝大多数模型都使用了先验,先验被证明效果非常好,但是是否不用先验也可以效果非常好呢?
2.风格调制+特征调制

GCFSR的结构。它包含一个编码器(红色)和一个生成器(绿色和蓝色)。编码器网络使用几个分层卷积层来提取多层次的特征和潜伏代码w。
生成器通过一连串的风格调制卷积,即这里的风格调制(绿色),将最上面的编码特征图和潜伏代码w生成现实的面部细节。
而特征调制(蓝色)模块则控制编码和生成的特征在条件上升因子s下的表现程度。我们以端到端方式训练整个网络。(有颜色的块是从头开始训练的,而其他块是固定的或不包含可训练的参数)。
3.上升因子s

s是如何控制超分的表现程度的
上升因子s首先被MLP转换为一组缩放向量,σ={σ(l) 1,2, σ(l+1) 1,2 , … }.

输出图像是通过tRGB层从融合后的特征h(i)逐步计算出来的。对所有中间的RGB输出进行升采样和求和,得出最终的输出,即y = ˆy(u)。
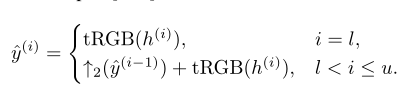
三、训练细节
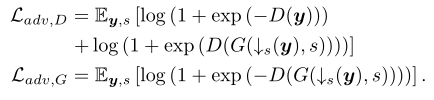
在4×和8×的SR任务中,只用对抗性损失训练的GCFSR就打败了其他模型
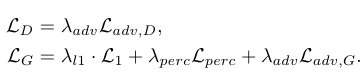
为了进一步提高SR的性能,使用常规的组合。L1、感知损失(SRGAN中提出,将生成器生成的图片和真实的HR图像输入VGG19中比较提取后的特征)、和对抗性损失。
实验
在FFHQ数据集上训练GCFSR,对于测试数据集,我们按照GLEAN从CelebA-HQ数据集中提取100张图像
为了评估,采用了广泛使用的非参考感知指标。FID和NIQE。我们还采用了像素级指标(PSNR和SSIM)和知觉指标(LPIPS)
训练的小批量大小被设定为24。用水平翻转来增强训练数据。用Adam优化器训练我们的模型,总共进行了300k次迭代。生成器和鉴别器的学习率都被设置为2×10-3。用PyTorch框架实现我们的模型


在CelebA-HQ上与最先进的方法进行16×、32×、64×SR的定量比较。GLEAN使用了三个模型,而其他的则使用一个模型来完成三个SR任务。红色和蓝色表示最佳和次佳性能。

对s的实验
总结
提出了一个叫做GCFSR的人脸识别框架,没有任何额外的先验,但可以处理非常大的因素的人脸识别(高达64×)。
GCFSR有一个编码生成器的架构,并且是端到端的可训练的快速收敛。
特别是,所提出的风格调制模块有助于生成真实的人脸细节,而特征调制模块则在条件放大系数的控制下动态地融合多级编码的特征和生成的特征。
通过这种方式,我们的GCFSR可以重建具有良好身份信息的忠实图像,并为用户调整提供灵活性。














 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









